【深度学习】之Caffe的solver文件配置(转载自csdn)
原文: http://blog.csdn.net/czp0322/article/details/52161759
今天在做FCN实验的时候,发现solver.prototxt文件一直用的都是model里自带的,一直都对里面的参数不是很了解,所以今天认真学习了一下里面各个参数的意义。
DL的任务中,几乎找不到解析解,所以将其转化为数学中的优化问题。sovler的主要作用就是交替调用前向传导和反向传导 (forward & backward) 来更新神经网络的连接权值,从而达到最小化loss,实际上就是迭代优化算法中的参数。
Caffe的solver类提供了6种优化算法,配置文件中可以通过type关键字设置:
- Stochastic Gradient Descent (type: “SGD”)
- AdaDelta (type: “AdaDelta”)
- Adaptive Gradient (type: “AdaGrad”)
- Adam (type: “Adam”)
- Nesterov’s Accelerated Gradient (type: “Nesterov”)
- RMSprop (type: “RMSProp”)
简单地讲,solver就是一个告诉caffe你需要网络如何被训练的一个配置文件。
Solver.prototxt 流程
- 首先设计好需要优化的对象,以及用于学习的训练网络和测试网络的prototxt文件(通常是train.prototxt和test.prototxt文件)
- 通过forward和backward迭代进行优化来更新参数
- 定期对网络进行评价
- 优化过程中显示模型和solver的状态
solver参数
base_lr
这个参数代表的是此网络最开始的学习速率(Beginning Learning rate),一般是个浮点数,根据机器学习中的知识,lr过大会导致不收敛,过小会导致收敛过慢,所以这个参数设置也很重要。
lr_policy
这个参数代表的是learning rate应该遵守什么样的变化规则,这个参数对应的是字符串,选项及说明如下:
- “step” - 需要设置一个stepsize参数,返回base_lr * gamma ^ ( floor ( iter / stepsize ) ),iter为当前迭代次数
- “multistep” - 和step相近,但是需要stepvalue参数,step是均匀等间隔变化,而multistep是根据stepvalue的值进行变化
- “fixed” - 保持base_lr不变
- “exp” - 返回base_lr * gamma ^ iter, iter为当前迭代次数
- “poly” - 学习率进行多项式误差衰减,返回 base_lr ( 1 - iter / max_iter ) ^ ( power )
- “sigmoid” - 学习率进行sigmod函数衰减,返回 base_lr ( 1/ 1+exp ( -gamma * ( iter - stepsize ) ) )
gamma
这个参数就是和learning rate相关的,lr_policy中包含此参数的话,需要进行设置,一般是一个实数。
stepsize
This parameter indicates how often (at some iteration count) that we should move onto the next “step” of training. This value is a positive integer.
stepvalue
This parameter indicates one of potentially many iteration counts that we should move onto the next “step” of training. This value is a positive integer. There are often more than one of these parameters present, each one indicated the next step iteration.
max_iter
最大迭代次数,这个数值告诉网络何时停止训练,太小会达不到收敛,太大会导致震荡,为正整数。
momentum
上一次梯度更新的权重,real fraction
weight_decay
权重衰减项,用于防止过拟合。
solver_mode
选择CPU训练或者GPU训练。
snapshot
训练快照,确定多久保存一次model和solverstate,positive integer。
snapshot_prefix
snapshot的前缀,就是model和solverstate的命名前缀,也代表路径。
net
path to prototxt (train and val)
test_iter
每次test_interval的test的迭代次数,假设测试样本总数为10000张图片,一次性执行全部的话效率很低,所以将测试数据分为几个批次进行测试,每个批次的数量就是batch_size。如果batch_size=100,那么需要迭代100次才能将10000个数据全部执行完,所以test_iter设置为100。
test_interval
测试间隔,每训练多少次进行一次测试。
display
间隔多久对结果进行输出
iter_size
这个参数乘上train.prototxt中的batch size是你实际使用的batch size。 相当于读取batchsize * itersize个图像才做一下gradient decent。 这个参数可以规避由于gpu内存不足而导致的batchsize的限制 因为你可以用多个iteration做到很大的batch 即使单次batch有限。
average_loss
取多次foward的loss作平均,进行显示输出。
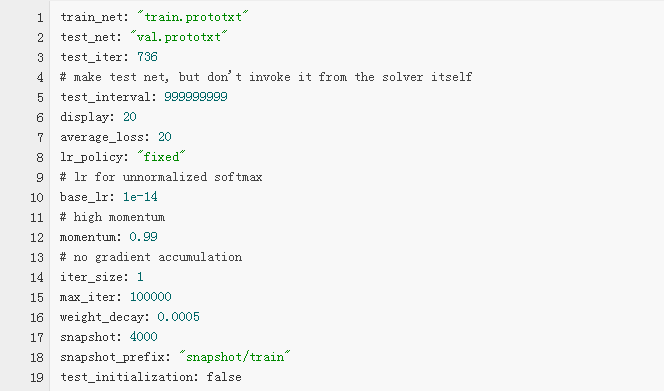
FCN的solver.prototxt文件
最新文章
- android studio使用中遇到的问题
- JSP与Servelt的区别
- Silverlight:针式打印机文字模糊的改善办法
- CI框架 数据库批量插入 insert_batch()
- 加了GO后报 'GO' 附近有语法错误
- .NET设计模式(8):适配器模式(Adapter Pattern)(转)
- javascript改变背景/字体颜色(Through the javascript to change the background and font color)
- (转)Android’s HTTP Clients
- python成长之路第三篇(4)_作用域,递归,模块,内置模块(os,ConfigParser,hashlib),with文件操作
- ZendStudio10 代码格式化 xml
- python none,null,,,,,类型
- 64位Win10系统安装Mysql5.7.11
- 浅析调用JSR303的validate方法, 验证失败时抛出ConstraintViolationException
- 谈一谈Java中的Error和Exception
- 什么是HTTP Referer?
- Ubuntu终端常用快捷键(精简)
- kernel: INFO: task sadc:14833 blocked for more than 120 seconds.
- ProxySQL Cluster的搭建
- tomcate+keepalived配置双机热备
- leetCodeReorderList链表合并