SQL2005中的事务与锁定(五)- 转载
------------------------------------------------------------------------
-- Author : HappyFlyStone
-- Date : 2009-10-05 14:00:00
-- Version: Microsoft SQL Server 2005 - 9.00.2047.00 (Intel X86)
-- Apr 14 2006 01:12:25
-- Copyright (c) 1988-2005 Microsoft Corporation
-- Enterprise Edition on Windows NT 5.2 (Build 3790: Service Pack 2)
------------------------------------------------------------------------
在生产交易过程中多个用户同时访问数据是不可以避免的,通过不同的隔离等级对资源与数据进行各种类型的锁定保护并在适当时候释放保证交易的正确运行,使得交易完整并保证数据的一致性。不管是锁定还是行版本控制器都决定着商业逻辑的流畅、事务的完整、数据的一致。所以我们要根据实际情况进行部署,在并发性性能与资源管理成本之间找到平衡点,怎样才能找到这个平衡点呢,那我们就得对SQLSERVER如何管理资源与锁有一个了解,SQLSERVER不但管理锁定,还要管理锁定模式之间的兼容性或升级锁定及解决死锁问题。通过SQL SERVER强大的、细致的锁定机制,使得并发性能得到最大程度的发挥,但是使用尽可能少的系统资源也是我们最希望的。
本身有两种锁定体系:一种是对共享数据的锁定,这种锁定就是我们大部时间讨论的锁定;一种是对内部数据结构及处理索引,这是一种称为闩锁的轻量级锁,比第一种锁定少耗资源,在sys.dm_tran_locks中是看不到这种锁的信息。我们在数据分页上放置物理记录或压缩、折分、转移分页数据时,这种锁就会发生了。我们在前面一直在说数据的逻辑一致性,那这种逻辑上的一致性就是通过锁定来控制的,而我们新提到的闩是保证物理的一致性(这种闩是系统内部使用所以我们不重点讨论了)。
并发访问数据时,SQL Server 2005使用下列机制确保事务完整并维护数据的一致性:
|-锁定
每个事务对所依赖的资源(如行、页或表)请求不同类型的锁。锁可以阻止其他事务以某种可能会导致事务请求锁出错的方式修改资源。当事务不再依赖锁定的资源时,它将释放锁。
|-行版本控制
当启用了基于行版本控制的隔离级别时,数据库引擎将维护修改的每一行的版本。应用程序可以指定事务使用行版本查看事务或查询开始时存在的数据,而不是使用锁保护所有读取。通过使用行版本控制,读取操作阻止其他事务的可能性将大大降低。
锁定和行版本控制可以防止用户读取未提交的数据,还可以防止多个用户尝试同时更改同一数据。如果不进行锁定或行版本控制,对数据执行的查询可能会返回数据库中尚未提交的数据,从而产生意外的结果。
最后说一下锁的粒度与并发性能是矛盾的,但是对管理锁定的成本却是有利的,锁的粒度越大并发性能下降,锁的粒度越小管理锁定成本越大。用图示例一下:
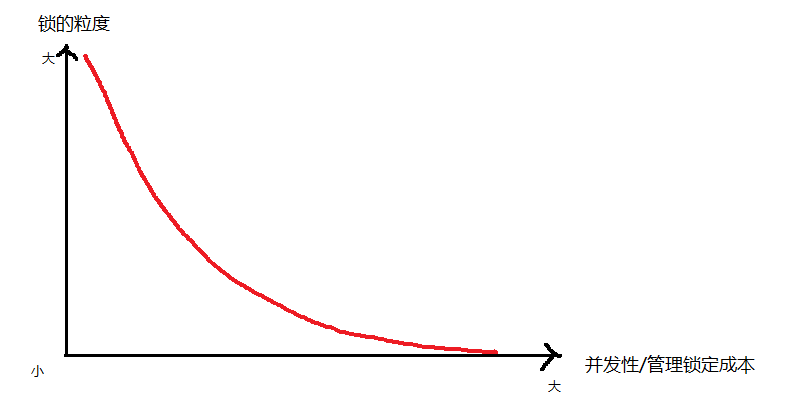
六、锁定
1、锁粒度和可锁定资源
SQL Server2005 具有多粒度锁定,允许一个事务锁定不同类型的资源。为了尽量减少锁定的开销,数据库引擎自动将资源锁定在适合任务的级别。锁定在较小的粒度(例如行)可以提高并发度,但开销较高,因为如果锁定了许多行,则需要持有更多的锁。锁定在较大的粒度(例如表)会降低了并发度,因为锁定整个表限制了其他事务对表中任意部分的访问,但其开销较低,因为需要维护的锁较少。
SQL SERVER可以锁定表、分页、行级、索引键或范围。在这我提醒大家一下,对于聚集索引的表,因为数据行就是索引的叶级,所以锁定是键锁完成而不是行锁。
数据库引擎通常必须获取多粒度级别上的锁才能完整地保护资源。这组多粒度级别上的锁称为锁层次结构。例如,为了完整地保护对索引的读取,数据库引擎实例可能必须获取行上的共享锁以及页和表上的意向共享锁。
下表列出了数据库引擎可以锁定的资源:
查询一:
SELECT * FROM MASTER..SPT_VALUES WHERE TYPE = 'LR' /* name number type low high status --------------- ----------- ---- ------- --------- ----------- LOCK RESOURCES 0 LR NULL NULL 0 NUL 1 LR NULL NULL 0 DB 2 LR NULL NULL 0 FIL 3 LR NULL NULL 0 TAB 5 LR NULL NULL 0 PAG 6 LR NULL NULL 0 KEY 7 LR NULL NULL 0 EXT 8 LR NULL NULL 0 RID 9 LR NULL NULL 0 APP 10 LR NULL NULL 0 MD 11 LR NULL NULL 0 HBT 12 LR NULL NULL 0 AU 13 LR NULL NULL 0 (13 行受影响) */
备注:
RID RID 锁定堆中行的行标识符
KEY KEY 序列化事务中的键范围行锁
PAG PAGE 数据或索引页面,8K为单位
EXT EXTENT 数据或索引页面,连续的8*page
HBT HOBT 堆或B树,保护索引或堆表页堆的锁
TAB TABLE 整个表,包括数据及索引
FIL FILE 数据库文件
APP APPLICATION 应用程序资源
MD METADATA 元数据
AU ALLOCATION_UNIT 分配单元
DB DATABASE 数据库
注:SPT_VALUES这个大家不陌生吧,好多人用它生成一个连续的ID号的啦,当时也有人问这个表的用途,现在发现它的作用了吧。下面我们还会使用到。
2、锁定模式
我们在前提面前到的共享锁定、更新锁定、排它锁定,这是为了配合前面的事务而提及的,那么SQL SERVER2005一共有多少锁定模式呢?我们通过一个简单的查询来列表:
查询:
SELECT * FROM MASTER..SPT_VALUES WHERE [TYPE] = 'L' /* NAME NUMBER TYPE LOW HIGH STATUS ---------------- ----------- ---- ----------- ----------- ----------- LOCK TYPES 0 L NULL NULL 0 NULL 1 L NULL NULL 0 SCH-S 2 L NULL NULL 0 SCH-M 3 L NULL NULL 0 S 4 L NULL NULL 0 U 5 L NULL NULL 0 X 6 L NULL NULL 0 IS 7 L NULL NULL 0 IU 8 L NULL NULL 0 IX 9 L NULL NULL 0 SIU 10 L NULL NULL 0 SIX 11 L NULL NULL 0 UIX 12 L NULL NULL 0 BU 13 L NULL NULL 0 RANGES-S 14 L NULL NULL 0 RANGES-U 15 L NULL NULL 0 RANGEIN-NULL 16 L NULL NULL 0 RANGEIN-S 17 L NULL NULL 0 RANGEIN-U 18 L NULL NULL 0 RANGEIN-X 19 L NULL NULL 0 RANGEX-S 20 L NULL NULL 0 RANGEX-U 21 L NULL NULL 0 RANGEX-X 22 L NULL NULL 0 (23 行受影响) */
我们可以看到一共有22种锁定模式 ,我简单的对上述[NAME]进行简单的枚举:
S --- 共享锁定(Shared) U --- 更新锁定(Update) X --- 排它锁定(Exclusive) I --- 意向锁定(Intent) Sch --- 架构锁定(Schema) BU --- 大量更新(Bulk Update) RANGE --- 键范围(Key-Range) 其它是在上述锁定的变种组合,比如IS --- 意向共享锁定
其实对这些锁定模式没什么介绍,大家可以参考联机帮助:访问和更改数据库数据锁定和行版本控制数据库引擎中的锁定。其实这些锁定模式在前一篇基本都有出现,大家可以在看下面的定义再回头看看前一篇的相关内容。下面我就简单的说说:
共享锁(S 锁)
当我们查询(select)数据时SQL SERVER2005会尝试在数据上申请共享锁定(S锁),但是前提是在当前的数据上不存在与共享锁定互斥的锁定。资源上存在共享锁时,任何其他事务都不能修改数据但是可以读取数据。读取操作一完成,就立即释放资源上的共享锁,除非将事务隔离级别设置为可重复读或更高级别,或者在事务持续时间内用锁定提示(HOLDLOCK)保留共享锁。
更新锁(U 锁)
是一种介于共享锁与排它锁之间的锁定,是一种中继锁定,像一个中间闸门,把从共享锁定转为排它锁的请求进行排队,有效的防止常见的死锁。在可重复读或可序列化事务中,一个事务读取数据 [获取资源(页或行)的共享锁(S 锁)],然后修改数据 [此操作要求锁转换为排他锁(X 锁)]。如果两个事务获得了资源上的共享模式锁,然后试图同时更新数据,则一个事务尝试将锁转换为排他锁(X 锁)。共享模式到排他锁的转换必须等待一段时间,因为一个事务的排他锁与其他事务的共享模式锁不兼容;发生锁等待。第二个事务试图获取排他锁(X 锁)以进行更新。由于两个事务都要转换为排他锁(X 锁),并且每个事务都等待另一个事务释放共享模式锁,因此发生死锁。而有了更新锁则可避免这种潜在的死锁问题,在查找到要更新的数据后SQL SERVER首先给数据设置更新锁定,因为共享锁定与更新锁定不互斥,在其它事务设置共享锁定时依然可以设置更新锁定,继而因更新锁定斥的,如果其它要修改数据的事务必须等待。如果事务修改资源,则更新锁转换为排他锁(X 锁)。
排他锁(X 锁)
可以防止并发事务对资源进行访问。使用排他锁(X 锁)时,任何其他事务都无法修改数据;仅在使用 NOLOCK 提示或未提交读隔离级别时才会进行读取操作。
数据修改语句(如 INSERT、UPDATE 和 DELETE)合并了修改和读取操作。语句在执行所需的修改操作之前首先执行读取操作以获取数据。因此,数据修改语句通常请求共享锁和排他锁。例如,UPDATE 语句可能根据与一个表的联接修改另一个表中的行。在此情况下,除了请求更新行上的排他锁之外,UPDATE 语句还将请求在联接表中读取的行上的共享锁。
排他锁定随事务结束而释放。
意向锁(I锁)
数据库引擎使用意向锁来保护共享锁(S 锁)或排他锁(X 锁)放置在锁层次结构的底层资源上。意向锁之所以命名为意向锁,是因为在较低级别锁前可获取它们,因此会通知意向将锁放置在较低级别上。
- 防止其他事务以会使较低级别的锁无效的方式修改较高级别资源。
- 提高数据库引擎在较高的粒度级别检测锁冲突的效率。
例如,在该表的页或行上请求共享锁(S 锁)之前,在表级请求共享意向锁。在表级设置意向锁可防止另一个事务随后在包含那一页的表上获取排他锁(X 锁)。意向锁可以提高性能,因为数据库引擎仅在表级检查意向锁来确定事务是否可以安全地获取该表上的锁。而不需要检查表中的每行或每页上的锁以确定事务是否可以锁定整个表。
意向锁包括意向共享 (IS)、意向排他 (IX)、意向排他共享 (SIX)、意向更新 (IU)、共享意向更新 (SIU ,S和 IU 锁的组合)、更新意向排他 (UIX,U 锁和 IX 锁的组合)。
在这儿的SIX,SIU,UIX我们可以理解成一种转换锁定,并不是由SQLSERVER直接申请的,是由一种模式向另一种模式转换时中间状态。比如说SIX表示一种正持有共享锁定的进程正在企图申请意向排它锁定,或是这样理解一个持有共享锁定的资源中有部分分页或行被另一个进程的排它锁定锁定了。其它同理可以理解。
为了更好的说明一点, 大家先看一个例子:
begin tran
update [dbo].[T_People_Heap] set Name='New Name' where id=7 commit--Don't commit
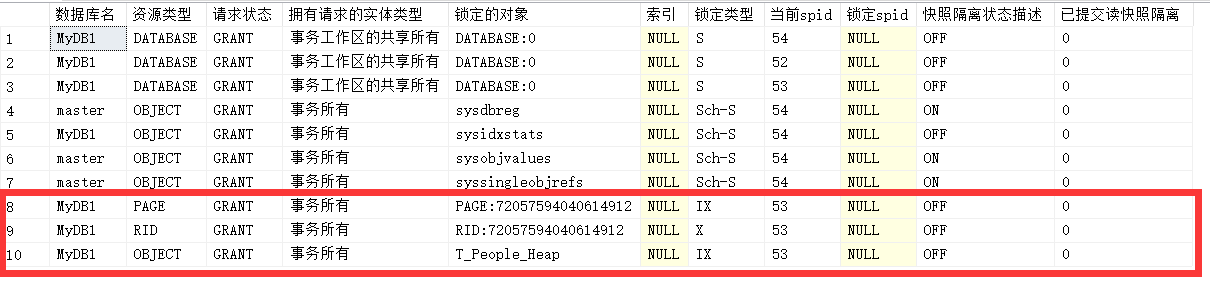
这是我在T_People_Heap表上加Where条件的一个更新动作,然后通过我以前写的一个工具:sp_us_lockinfo查看锁的信息,其实我的update只是影响一个行记录,但是我们发现有三个锁存在,只要当前事务不结束,其它事物对这个表申请不管是页面的锁定还是表级的锁定一定会与现在的表或页意向锁冲突,进而发生阻塞,而且我们在前面的隔离等级的实例中也有例子,你会发现它的请求状态是WAIT 而不是GRANT。
架构锁(架构修改锁 Sch-M 锁、架构稳定性锁Sch-S 锁)
执行表的数据定义语言 (DDL) 操作(例如添加列或删除表)时使用架构修改锁。在架构修改锁起作用的期间,会防止对表的并发访问。这意味着在释放架构修改锁(Sch-M 锁)之前,该锁之外的所有操作都将被阻止。
当编译查询时,使用架构稳定性锁。架构稳定性锁不阻塞任何事务锁,包括排他锁(X 锁)。因此在编译查询时,其他事务 [包括在表上有排他锁(X 锁)的事务] 都能继续运行。但不能在表上执行 DDL 操作。
大容量更新锁(BU 锁)
当将数据大容量复制到表,且指定了 TABLOCK 提示或者使用 sp_tableoption 设置了 table lock on bulk 表选项时,将使用大容量更新锁。大容量更新锁允许多个线程将数据并发地大容量加载到同一表,同时防止其他不进行大容量加载数据的进程访问该表。
在SQL SERVER2005有两种类型键锁:键锁及键范围锁。采用哪种类型的键锁取决于隔离级别。对于已提交读、可重复读、快照隔离时SQLSERVER锁定实际的索引键(如果是堆表除了实际非聚集索引上的键锁同时有实际行上的行锁),如果是可串行化隔离时就可以看到键范围锁。在早期的版本中我们实验可以看到SQLSERVER是通过分页锁定或表锁来实现的,也许键范围锁不是最完美的,但是我们应该看到它比分页或表锁定所锁定的范围要小得多,在保证不出现幻影的前提下键范围锁比以前版本采用锁定提供了更高的并发性能。
键锁、键范围锁(Key-range锁)
在SQL SERVER2005有两种类型键锁:键锁及键范围锁。采用哪种类型的键锁取决于隔离级别。对于已提交读、可重复读、快照隔离时SQLSERVER锁定实际的索引键(如果是堆表除了实际非聚集索引上的键锁同时有实际行上的行锁),如果是可串行化隔离时就可以看到键范围锁。在早期的版本中我们实验可以看到SQLSERVER是通过分页锁定或表锁来实现的,也许键范围锁不是最完美的,但是我们应该看到它比分页或表锁定所锁定的范围要小得多,在保证不出现幻影的前提下键范围锁比以前版本采用锁定提供了更高的并发性能。
键范围锁放置在索引上,指定开始键值和结束键值。此锁将阻止任何要插入、更新或删除任何带有该范围内的键值的行的尝试,因为这些操作会首先获取索引上的锁。键范围锁包括按范围-行格式指定的范围组件和行组件,是一种组合锁模式(Range范围-索引项的锁模式)。比如:RangeI-N ,RangeI 表示插入范围,N(NULL) 表示空资源,它表示在索引中插入新键之前测试范围。
在SELECT * FROM MASTER..SPT_VALUES WHERE [TYPE] = 'L'查询结果的最后9条个就是键范围锁。这种锁定因持续时间比较短一般在sys.dm_tran_locks中很难见到。比如RangeI_N这个锁定,是在键范围内插入记录时获得的,在键范围内找到位置立即升级为X锁定,这个过程很短,我们在sys.dm_tran_locks中很难找到它的踪影,不过我们是可以模拟出来的,下面我们来模拟一下:
查询一:
DROP TABLE TB GO CREATE TABLE TB (ID INT primary key, COL VARCHAR(16)) GO INSERT INTO TB SELECT 1,'A' GO SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRAN SELECT * FROM TB WHERE id BETWEEN 1 AND 5 --OLD数据 --COMMIT TRAN --Don't commit SELECT @@SPID /* (1 行受影响) ID COL ----------- ---------------- 1 A (1 行受影响) ------ 52 (1 行受影响) */
查询二:
INSERT TB SELECT 2,'E'
查询三:
exec sp_us_lockinfo
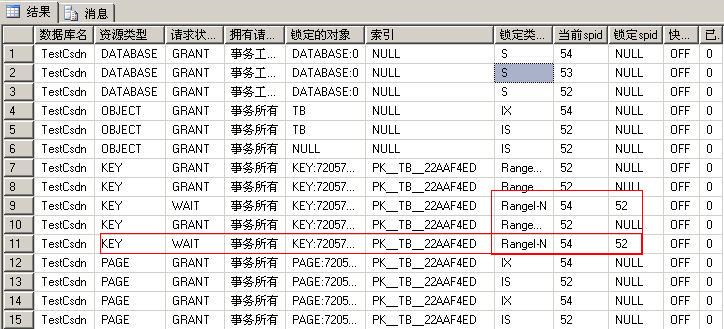
在使用可序列化事务隔离级别时,对于 Transact-SQL 语句读取的记录集,键范围锁在索引获上取锁定阻止一切尝试在包含索引键值落入范围内增删改的数据行,可以隐式保护该记录集中包含的行范围。键范围锁可防止幻读。通过保护行之间键的范围,它还防止对事务访问的记录集进行幻像插入或删除。
例如我们在上面有例子的可串行化隔离级别下,选择索引键值在’1-5’的数据时,SQL SERVER 对落在1-5之间键值设置键范围锁定,避免包含在这个范围内的键值的插入及这个范围内键值的删除及更新。
最后强调一下键范围键产生的条件:
- 事务隔离级别必须设置为 SERIALIZABLE。
- 询处理器必须使用索引来实现范围筛选谓词。例如,SELEC中的 WHERE 子句。
3、锁兼容性矩阵
锁兼容性控制多个事务能否同时获取同一资源上的锁。如果资源已被另一事务锁定,则仅当请求锁的模式与现有锁的模式相兼容时,才会授予新的锁请求。如果请求锁的模式与现有锁的模式不兼容,则请求新锁的事务将等待释放现有锁或等待锁超时间隔过期。

关于SQL Server的锁,可以查看下面这篇微软官方文档,有很详细的介绍:
最新文章
- scala 学习之: list.fill 用法
- postgresql 锁的定位
- javascript 金额格式化
- java mail jar冲突
- 难搞的EXCHANGE重新安装错误
- python-用户登录小程序
- Stack(栈)
- 2.2. 添加托管对象模型(Core Data 应用程序实践指南)
- 通过Percona Xtrabackup实现数据的备份与恢复
- php的laravel框架使用心得
- C/C++之循环结构
- Hbase问题
- 4.2 Oracle Dataguard failover 操作步骤
- Python:Selenium 2:使用
- CSS---文档流布局 | 脱标-postion-zindex | 脱标-浮动
- log4j2 实际使用详解
- 使用typeof()或者typeof数据类型检测
- Base标签小记:更改当前页面的地址
- centos 安装laravel
- kendo ui treeview 标题太长时的自动换行