34.scrapy解决爬虫翻页问题
2024-09-27 20:12:28
这里主要解决的问题: 1.翻页需要找到页面中加载的两个参数。
'__VIEWSTATE': '{}'.format(response.meta['data']['__VIEWSTATE']),
'__EVENTVALIDATION': '{}'.format(response.meta['data']['__EVENTVALIDATION']),
还有一点需要注意的就是 dont_filter=False
yield scrapy.FormRequest(url=response.url, callback=self.parse, formdata=data, method="POST", dont_filter=False)
2.日期 我自己做的时候取的是2008-2018年的数据。
3.还有的就是数据字段入库乱的问题。
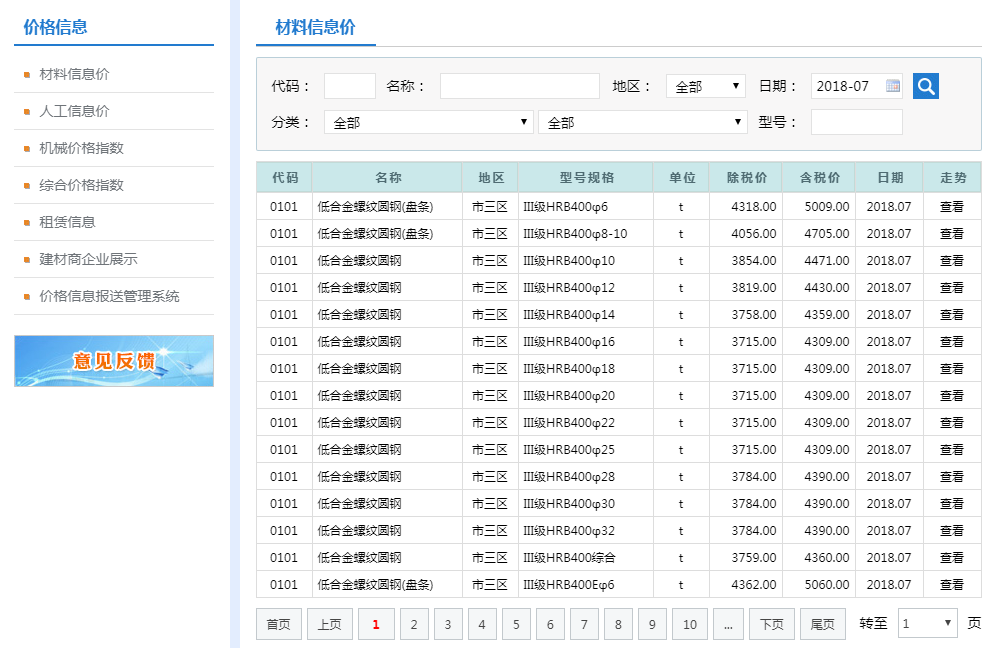
4.一些问题比如越界等,我都没做具体的解决只是做了一个抛出异常没做处理。 这个相对较麻烦一点,首先先分析一下网站,地址: http://www.nbzj.net/MaterialPriceList.aspx (宁波造价网) 这里呢我主要是拿这个材料信息价数据。
nbzj.py # -*- coding: utf-8 -*-
import scrapy
import re
from nbzj_web.items import NbzjWebItem class NbzjSpider(scrapy.Spider):
name = 'nbzj'
allowed_domains = ['www.nbzj.net']
start_urls = ['http://www.nbzj.net/MaterialPriceList.aspx']
custom_settings = {
"DOWNLOAD_DELAY": 1,
"ITEM_PIPELINES": {
'nbzj_web.pipelines.MysqlPipeline': 300,
},
"DOWNLOADER_MIDDLEWARES": {
'nbzj_web.middlewares.NbzjWebDownloaderMiddleware': 500,
},
}
def parse(self, response):
_response=response.text
# print(_response) #获取翻页参数
__VIEWSTATE=re.findall(r'id="__VIEWSTATE" value="(.*?)" />',_response) A=__VIEWSTATE[0]
# print(A)
__EVENTVALIDATION=re.findall(r'id="__EVENTVALIDATION" value="(.*?)" />',_response)
B=__EVENTVALIDATION[0]
# print(B) #页码
page_num=re.findall(r'>下页</a><a title="转到第(.*?)页"',_response)
# print(page_num[0])
max_page=page_num[0]
# print(max_page) content={
'__VIEWSTATE':A,
'__EVENTVALIDATION':B,
'page_num':max_page,
} # 获取标签列表 tag_list=response.xpath("//div[@class='fcon']/table[@class='mytable']//tr/td").extract()
# print(tag_list)
#这里我直接取文本出现问题,我就直接拿标签数据等下面在做字符串的修改删除
list=[]
try:
tag1=tag_list[:9]
list.append(tag1)
tag2=tag_list[9:18]
list.append(tag2)
tag3=tag_list[18:27]
list.append(tag3)
tag4=tag_list[27:36]
list.append(tag4)
tag5=tag_list[36:45]
list.append(tag5)
tag6=tag_list[45:54]
list.append(tag6)
tag7=tag_list[54:63]
list.append(tag7)
tag8=tag_list[63:72]
list.append(tag8)
tag9=tag_list[72:81]
list.append(tag9)
tag10=tag_list[81:90]
list.append(tag10)
tag11=tag_list[99:108]
list.append(tag11)
tag12=tag_list[108:117]
list.append(tag12)
tag13=tag_list[117:126]
list.append(tag13)
tag14=tag_list[126:135]
list.append(tag14)
tag15=tag_list[135:144]
list.append(tag15) print(list) for tag in list: item=NbzjWebItem()
# print(tag)
#代码
code=tag[0].replace('<td style="text-align: center">','').replace('</td>','')
# print(code)
item['code']=code
#名称
name=tag[1].replace('<td>','').replace('</td>','')
# print(name)
item['name']=name
#地区
district=tag[2].replace('<td style="text-align: center">','').replace('</td>','')
# print(district)
item['district']=district
#型号规格
_type=tag[3].replace('<td>','').replace('</td>','')
# print(_type)
item['_type']=_type
#单位
unit=tag[4].replace('<td style="text-align: center">','').replace('</td>','')
# print(unit)
item['unit']=unit
#除税价
except_tax_price = tag[5].replace('<td style="text-align: right">','').replace('</td>','')
# print(except_tax_price)
item['except_tax_price']=except_tax_price
#含税价
tax_price = tag[6].replace('<td style="text-align: right">','').replace('</td>','')
# print(tax_price)
item['tax_price']=tax_price
#时间
time=tag[7].replace('<td style="text-align: center">','').replace('</td>','')
print(time)
item['time']=time # print('-'*100)
yield item
# print('*'*100)
except:
pass yield scrapy.Request(url=response.url,callback=self.parse_detail,meta={"data": content}) def parse_detail(self,response):
for h in range(2008,2019):
list=['','','','','','','','','','','','']
for j in list:
try:
max_page=response.meta['data']['page_num']
# print(max_page)
for i in range(2,int(max_page)):
data={ '__VIEWSTATE': '{}'.format(response.meta['data']['__VIEWSTATE']),
'__VIEWSTATEGENERATOR': 'E53A32FA',
'__EVENTTARGET': 'ctl00$ContentPlaceContent$Pager',
'__EVENTARGUMENT':'{}'.format(i),
'__EVENTVALIDATION': '{}'.format(response.meta['data']['__EVENTVALIDATION']),
'HeadSearchType': 'localsite',
'ctl00$ContentPlaceContent$txtnewCode':'',
'ctl00$ContentPlaceContent$txtMaterualName':'',
'ctl00$ContentPlaceContent$ddlArea':'',
'ctl00$ContentPlaceContent$txtPublishDate': '{} - 0{}'.format(h,j),
'ctl00$ContentPlaceContent$ddlCategoryOne':'',
'ctl00$ContentPlaceContent$hidCateId':'',
'ctl00$ContentPlaceContent$txtSpecification':'',
'ctl00$ContentPlaceContent$Pager_input': '{}'.format(i-1),
'ctl00$foot$ddlsnzjw': '',
'ctl00$foot$ddlswzjw': '',
'ctl00$foot$ddlqtxgw': ''
}
yield scrapy.FormRequest(url=response.url, callback=self.parse, formdata=data, method="POST", dont_filter=False)
except:
pass
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class NbzjWebItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() code=scrapy.Field()
name=scrapy.Field()
district=scrapy.Field()
_type=scrapy.Field()
unit=scrapy.Field()
except_tax_price=scrapy.Field()
tax_price =scrapy.Field()
time=scrapy.Field()
middlewares.py # -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals class NbzjWebSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider. # Should return None or raise an exception.
return None def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response. # Must return an iterable of Request, dict or Item objects.
for i in result:
yield i def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict
# or Item objects.
pass def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated. # Must return only requests (not items).
for r in start_requests:
yield r def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name) class NbzjWebDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware. # Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
piplines.py # -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # -*- coding: utf-8 -*-
from scrapy.conf import settings
import pymysql class NbzjWebPipeline(object):
def process_item(self, item, spider):
return item # 数据保存mysql
class MysqlPipeline(object): def open_spider(self, spider):
self.host = settings.get('MYSQL_HOST')
self.port = settings.get('MYSQL_PORT')
self.user = settings.get('MYSQL_USER')
self.password = settings.get('MYSQL_PASSWORD')
self.db = settings.get(('MYSQL_DB'))
self.table = settings.get('TABLE')
self.client = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port, db=self.db, charset='utf8') def process_item(self, item, spider):
item_dict = dict(item)
cursor = self.client.cursor()
values = ','.join(['%s'] * len(item_dict))
keys = ','.join(item_dict.keys())
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=self.table, keys=keys, values=values)
try:
if cursor.execute(sql, tuple(item_dict.values())): # 第一个值为sql语句第二个为 值 为一个元组
print('数据入库成功!')
self.client.commit()
except Exception as e:
print(e) print('数据已存在!')
self.client.rollback()
return item def close_spider(self, spider): self.client.close()
setting.py # -*- coding: utf-8 -*- # Scrapy settings for nbzj_web project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'nbzj_web' SPIDER_MODULES = ['nbzj_web.spiders']
NEWSPIDER_MODULE = 'nbzj_web.spiders' # mysql配置参数
MYSQL_HOST = "172.16.10.197"
MYSQL_PORT = 3306
MYSQL_USER = "root"
MYSQL_PASSWORD = ""
MYSQL_DB = 'web_datas'
TABLE = "web_nbzj" # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'nbzj_web (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'nbzj_web.middlewares.NbzjWebSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'nbzj_web.middlewares.NbzjWebDownloaderMiddleware': 543,
} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'nbzj_web.pipelines.NbzjWebPipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
scrapy crawl nbzj 执行结果如下

由于设置deloy为 1s 所以速度会比较慢,采集237142条数据。

最新文章
- MVVM TextBox的键盘事件
- 谈谈枚举的新用法——java
- jQuery 获取 radio 选中后的文字
- JS原型链
- jquery mobile
- DOM - EventListener 句柄操作
- copy 和 strong(或retain)的区别
- javascript中字符串格式转化成json对象记录
- 使用纯代码定义UICollectionView和自定义UICollectionViewCell
- iOS 创建OpenGL 环境的思考
- 基于Modbus的C#串口调试开发
- Sudoku Killer
- 关于close和shutdown
- Mysql AVG() 值 返回NULL而非空结果集
- DockerFile详解--转载
- 【iCore1S 双核心板_FPGA】例程八:触发器实验——触发器的使用
- python 部分数据处理代码
- git的全局变量
- MySQL优化具体
- 使用Hbuilder开发IOS应用上架审核提示请指定用户在位置许可模式警报中使用位置的预定用途。