深度学习基础(一)LeNet_Gradient-Based Learning Applied to Document Recognition
作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner
这篇论文内容较多,这里只对部分内容进行记录:
以下是对论文原文的翻译:
在传统的模式识别模型中,往往会使用手动设计的特征提取器从输入中提取相关信息并去除不相关的可变性,然后一个可训练的分类器对这些提取到的特征进行分类。在本论文的方案中,标准的全连接多层网络就相当于分类器,并且该方案尽可能多地依赖特征提取器本身的学习。在字符识别任务中,一个网络可以将几乎未经过处理的数据作为输入。虽然任意一个全连接前向网络在字符识别等任务中能够取得不错的效果,但是仍然有不少问题存在。
首先,输入的图像一般都很大,经常有几百个变量(即像素)。如果采用全连接网络的话,即使第一个隐含层仅有100个神经元,那前两层之间的权重参数也会有几万个。数量如此大的参数会增加系统的容量,但也因此需要更大的训练集。而且,在某些硬件设备上实现时由于需要存储的参数如此多,可能会带来内存不足的问题。但是,用于图像或语音的非结构化网络的主要缺陷是,对于转换或输入的局部失真没有内在的不变性。在被提供给神经网络固定大小的输入层之前,字符图像或其他2D或1D信号必须近似地标准化并居于输入域的中心。不幸的是,没有这样完美的预处理:手写体通常在单词级别标准化,这可能导致单个字符的大小、倾斜和位置变化。这一点,再加上书写风格的多样性,会导致输入对象中不同特征的位置发生变化。原则上,一个足够大的全连接网络可以学习产生与这种变化不同的产出。然而,学习这样一项任务可能会导致在输入中不同位置具有相似权重模式的多个单元,从而在输入中不同特征出现的任何地方检测到这些特征。学习这些权重参数需要数目巨大的训练样本来覆盖可能的变化空间。
其次,全连接结构忽略了输入的整体结构。输入变量可以以任何不影响训练输出的顺序给定。与变量不同的是,图像有很强的2D局部结构:像素在空间上是高度相关的。
卷积神经网络结合了三种结构的思想以确保一定程度的平移、缩放和畸变不变性:局部感受野(local receptive fields)、权值共享(shared weights )或权值复制(weights replication)和时间或空间子采样(sub-sampling)。图中展示的LeNet-5是一种用于识别字符的典型卷积神经网络。网络中输入平面接收尺寸统一且中心对齐后的字符图像。
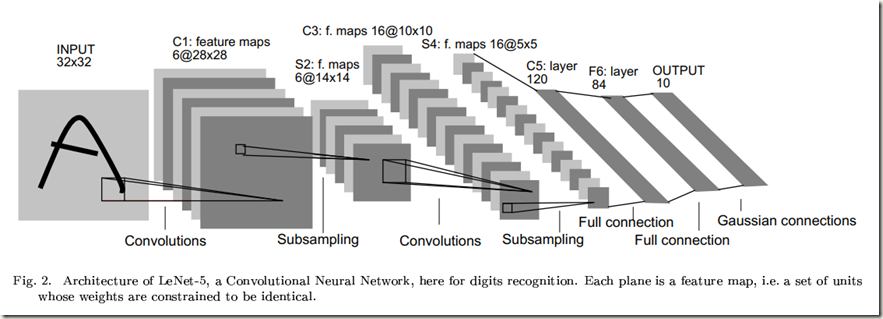
LeNet-5结构描述:
不加输入层的话,该网络共有7层权重层。
输入是一个32*32的像素图像。该尺寸比数据集中最大的字符要大得多(最多20*20个像素位于28*28的中心区域),这是为了确保潜在的显著特征比如笔画终点和拐角能够位于高层特征检测算子的感受野中。在LeNet-5中,最后一层卷积层的感受野的中心点集在32*32输入的中心形成一个20*20的区域。输入的像素值会先标准化以便于背景(white)与-0.1对应,前景(black)与1.175对应。该操作使得输入的平均值大概为0,并且方差为1,这样有助于加速学习。
卷积层(C1)有6个特征图(feature map)。特征图中的每个神经元与输入中的一个5*5邻域相连接。特征图的尺寸是28*28,相较于前一层有所缩小,这是因为进行卷积操作时仅在图像内部进行卷积,而没有对边缘进行padding。C1层包含有156个可训练参数和122,304个连接。
子采样层(S2)含有6个特征图,每个特征图的尺寸是14*14。特征图的每个单元与C1层中相应的特征图的2*2邻域相连(核是单通道单feature map)。计算过程是:先将邻域内输入的四个单元相加,然后乘上一个可训练系数,再加上一个可训练偏置,计算结果会经过sigmoid函数作用。该层中2*2的感受野不重叠,因此S2中特征图的尺寸是C1中特征图的一半。S2层有12个可训练参数和5,880个连接。(我看有的代码中将该层当做MaxPooling层)
卷积层(C3)有16个特征图,每个特征图的尺寸是10*10。特征图的每个神经元与S2层中几个特征图相同位置的5*5的邻域相连(卷积核是单通道多feature map的)(有的代码中将该层当做有16个滤波器的卷积层,即正常的卷积层)。下表展示了S2中特征图与C3中特征图的对应情况:

至于为什么C3中的特征图不与S2的所有特征图均相连,论文中是这样解释的:首先,不完全连接能够保证连接的数量在一个合理的范围内,也就是说保证连接的数量不会太多。更重要的是,这样安排打破了对称,不同的特征图可以提取不同的特征,因为它们被分配的输入集不同。
上面表格中贴出的连接关系有如下特点:C3中前6个特征图分别从S2中连续的3个特征图获取输入;C3中接下来6个特征图分别从S2中连续的4个特征图获取输入;接下来3个特征图分别从S2中4个不连续的特征图获取输入;最后一个特征图从S2中的所有特征图获取输入。
C3层有1,516(60*25+16)个训练参数和151,600个连接。同样没有padding。在权重分配上值得注意的是:C3层中某个特征图从S2中部分的特征图获取输入时,它们共享偏置,但是每个卷积核的权重不同。比如,C3中第一个feature map从S2中前三个feature map获取输入,在计算时一共有三个卷积核(5*5*3=75个可训练参数)和一个共享的偏置(1个可训练参数),所以一共76个trainable parameters.
子采样层(S4)有16个尺寸为5*5的特征图。特征图的每个神经元从C3层中与之对应的特征图中的2*2邻域获取输入。S4层有32个可训练参数和2,000个连接(当做MaxPooling层120)
卷积层(C5)有120个特征图。特征图的每个神经元从S4层的所有特征图的5*5邻域获取输入。因为S4层的特征图的尺寸也为5*5,所以C5特征图的尺寸为1*1,这就相当于S4与C5之间存在一个全连接层。但是C5被称作卷积层而不是全连接层,这是因为如果LeNet-5的输入变得更大,那么特征图的维度会超过1*1。卷积网络的尺寸可以动态递增,这个过程会在论文的后面介绍。该层一共有48,120个训练参数,计算方法与C3层相同。
全连接层(F6)包含84个神经元,与C5层全连接。该层神经元数目是根据输出层设定的,在后面会解释。层中一共有10,164个训练参数
最后,输出层由欧氏径向基函数单元(RBF)组成,每个类一个,每个输入84个。
关于径向基函数的详细信息可以参考这里
最新文章
- JAVA语言搭建白盒静态代码、黑盒网站插件式自动化安全审计平台
- 用alarmmanager 多次发送PendingIntent
- linux下使用automake工具自动生成makefile文件
- 曲演杂坛--为什么SELECT语句会被其他SELECT阻塞?
- Loadrunner中web_custom_request使用场景
- python学习第四天第一部分
- 对stack概念的理解与应用
- HDOJ-ACM1425 sort 简单hash应用
- 剪花布条(kmp)
- 新项目架构从零开始(三)------基于简单ESB的服务架构
- IE8下提示'console'未定义错误
- 0513JS数组遍历、内置方法、训练
- 初步了解Spring
- 对python3中pathlib库的Path类的使用详解
- nginx实现限速
- Leetcode——30.与所有单词相关联的字串【##】
- .net core相关博客
- win7仿win98电脑主题
- Flink之状态之checkpointing
- Android中读取图片EXIF元数据之metadata-extractor的使用
热门文章
- LRU原理和Redis实现——一个今日头条的面试题(转载)
- IntelliJIdea 2016.2 使用 tomcat 8.5 调试spring的web项目时,bean被实例化两次导致timer和thread被启动了两遍的问题的解决
- nmon监控
- CentOS 7下PXE+Kickstart无人值守安装操作系统
- 织梦dedecms移动版设置二级域名的方法 织梦如何设置m.开头的域名
- Python中的retry
- ImportError: No module named 'requests.packages.urllib3'
- AWT是Java最早出现的图形界面,但很快就被Swing所取代。
- python调用shell脚本时需要切换目录
- Redis防止重複請求鎖功能