第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
2024-10-10 07:20:48
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器
1、

2、
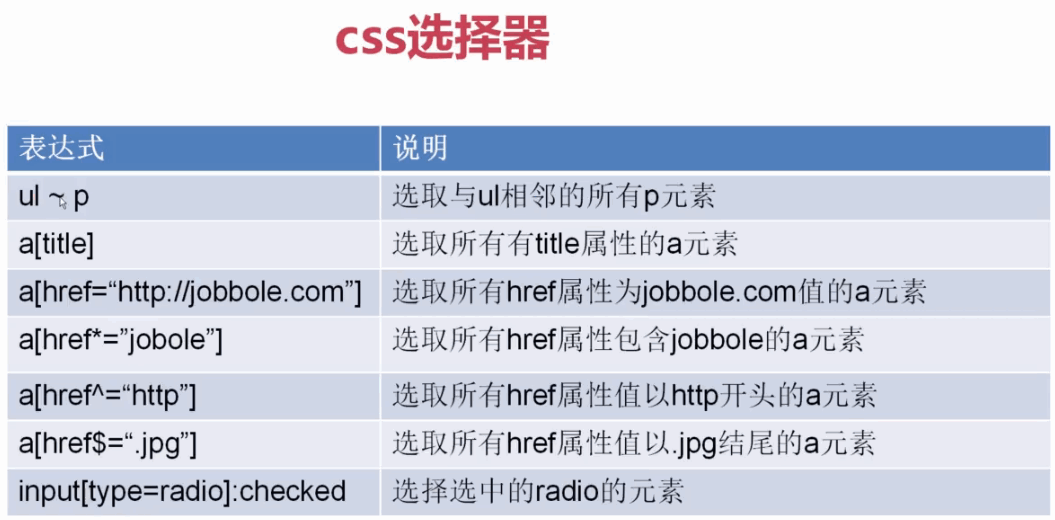
3、
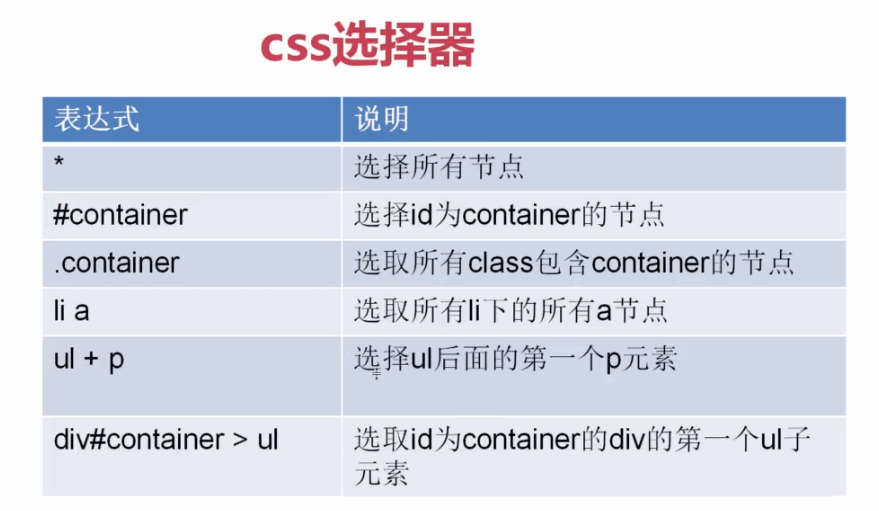
::attr()获取元素属性,css选择器
::text获取标签文本
举例:
extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如果没有数据默认是什么,一般我们设置为空字符串
extract()获取过滤后的数据,返回字符串列表
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): asd = response.css('.archive-title::text').extract() #这里也可以用extract_first('')获取返回字符串
# print(asd) for i in asd:
print(i)
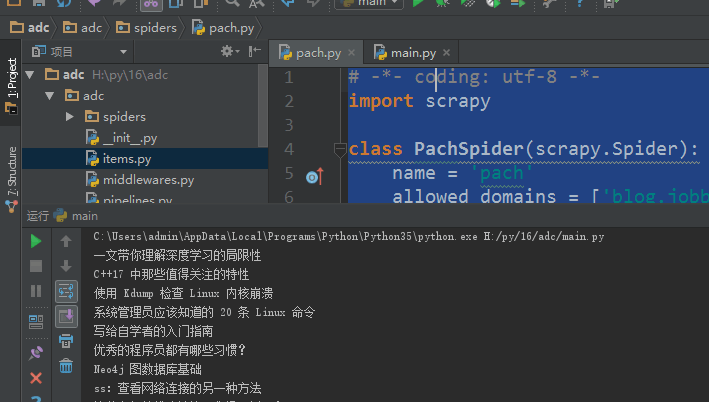
最新文章
- android adb命令
- ACM题目————Equations
- UIActionViewController 详解 iOS8
- php的冒泡算法
- poj 3233 Matrix Power Series
- zoj2729 Sum Up(模拟)
- Data URI(转)
- 过河(DP)
- 【转】Entity Framework 5.0系列之自动生成Code First代码
- 重构手法之Split Temporary Variable(分解临时变量)
- 测者的性能测试手册:Yourkit 监控JettyYourkit 监控Jetty
- Simulink--MATLAB中的一种可视化仿真工具
- Project Euler Problem 10
- mybatis-config.xml 模板
- java的前缀自增自减和后缀自增自减
- easyui表单提交验证form
- Python中raw_input() & input() 的功能对比
- 海思hi3518 移植live555 实现H264的RTSP播放
- 字段值为NULL时的like注意事项
- 页面跳转问题-button 确定提交按钮