TensorFlow——学习率衰减的使用方法
2024-09-02 15:29:22
在TensorFlow的优化器中, 都要设置学习率。学习率是在精度和速度之间找到一个平衡:
学习率太大,训练的速度会有提升,但是结果的精度不够,而且还可能导致不能收敛出现震荡的情况。
学习率太小,精度会有所提升,但是训练的速度慢,耗费较多的时间。
因而我们可以使用退化学习率,又称为衰减学习率。它的作用是在训练的过程中,对学习率的值进行衰减,训练到达一定程度后,使用小的学习率来提高精度。
在TensorFlow中的方法如下:tf.train.exponential_decay(),该方法的参数如下:
learning_rate, 初始的学习率的值
global_step, 迭代步数变量
decay_steps, 带迭代多少次进行衰减
decay_rate, 迭代decay_steps次衰减的值
staircase=False, 默认为False,为True则不衰减
例如
tf.train.exponential_decay(initial_learning_rate, global_step=global_step, decay_steps=1000, decay_rate=0.9)表示没经过1000次的迭代,学习率变为原来的0.9。
增大批次处理样本的数量也可以起到退化学习率的作用。
下面我们写了一个例子,每迭代10次,则较小为原来的0.5,代码如下:
import tensorflow as tf
import numpy as np global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1 learning_rate = tf.train.exponential_decay(initial_learning_rate,
global_step=global_step,
decay_steps=10,
decay_rate=0.5) opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1) with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(learning_rate)) for i in range(50):
g, rate = sess.run([add_global, learning_rate])
print(g, rate)
下面是程序的结果,我们发现没10次就变为原来的一般:
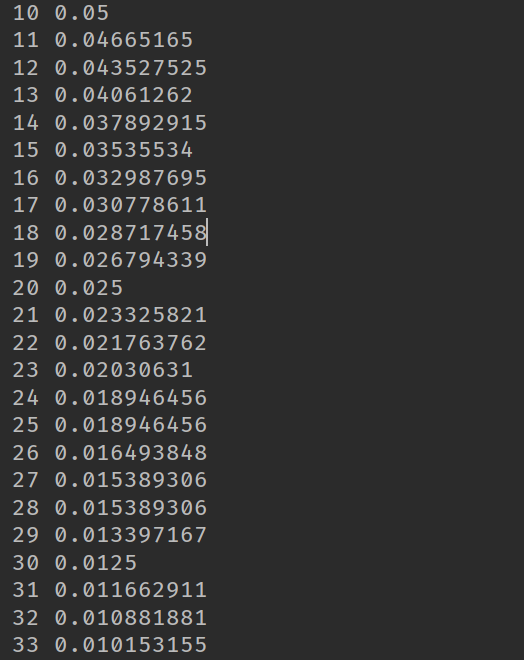
随后,又在MNIST上面进行了测试,发现使用学习率衰减使得准确率有较好的提升。代码如下:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt mnist = input_data.read_data_sets('MNIST_data', one_hot=True) tf.reset_default_graph() x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10]) w = tf.Variable(tf.random_normal([784, 10]))
b = tf.Variable(tf.zeros([10])) pred = tf.matmul(x, w) + b
pred = tf.nn.softmax(pred) cost = tf.reduce_mean(-tf.reduce_sum(y * tf.log(pred), reduction_indices=1)) global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1 learning_rate = tf.train.exponential_decay(initial_learning_rate,
global_step=global_step,
decay_steps=1000,
decay_rate=0.9) opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1) optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) training_epochs = 50
batch_size = 100 display_step = 1 with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c, add, rate = sess.run([optimizer, cost, add_global, learning_rate], feed_dict={x:batch_xs, y:batch_ys})
avg_cost += c / total_batch if (epoch + 1) % display_step == 0:
print('epoch= ', epoch+1, ' cost= ', avg_cost, 'add_global=', add, 'rate=', rate)
print('finished') correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print('accuracy: ', accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))
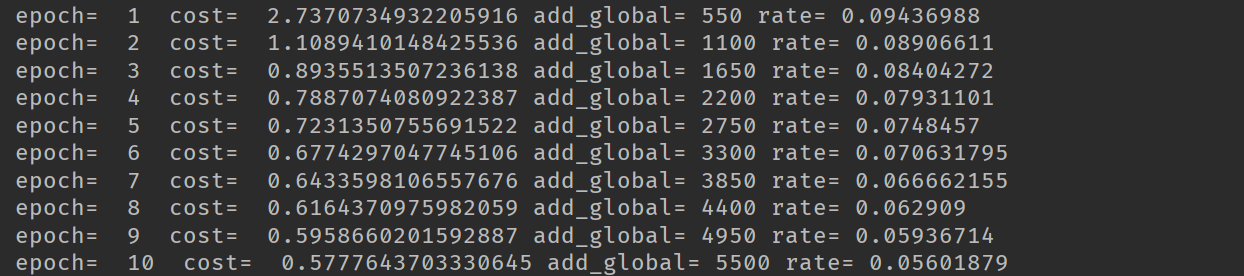
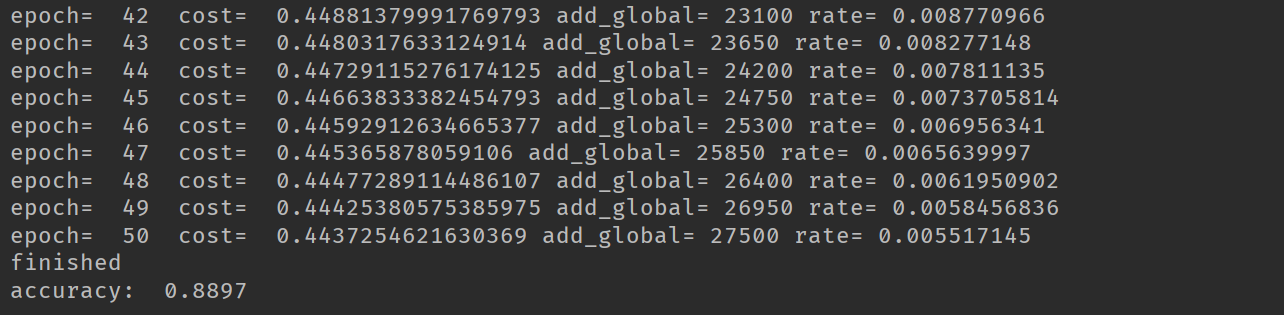
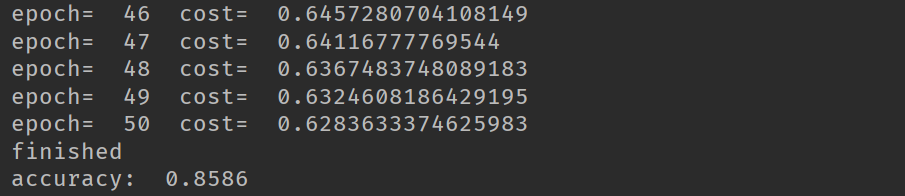
在使用衰减学习率我们最后的精度达到0.8897,在使用固定的学习率时,精度只有0.8586。
最新文章
- 6.在MVC中使用泛型仓储模式和依赖注入实现增删查改
- 复杂对象的本地化(以Person为例)
- C++ STL之priority_queue
- Nodejs_day01
- AD新建用户、组、OU
- params关键字载入空值的陷阱
- bandit_pass
- mayavi安装
- 最常用Python开源框架有哪些?
- hdu 5314 动态树
- 解析HTTP报文——C#
- NotePad++ 添加HEX-Editor插件
- 对象存储服务(Object Storage Service,简称 OSS)
- Java面试题集锦
- 艾妮记账本微信小程序开发(失败版)
- Eclipse常用快捷键(用到想到随时更新)
- Android自定义视图三:给自定义视图添加“流畅”的动画
- Apache启用GZIP压缩网页传输
- tp5数据输出
- c语言格式控制符