Scrapy爬虫案例 | 数据存储至MySQL
2024-10-19 16:39:15
首先,MySQL创建好数据库和表
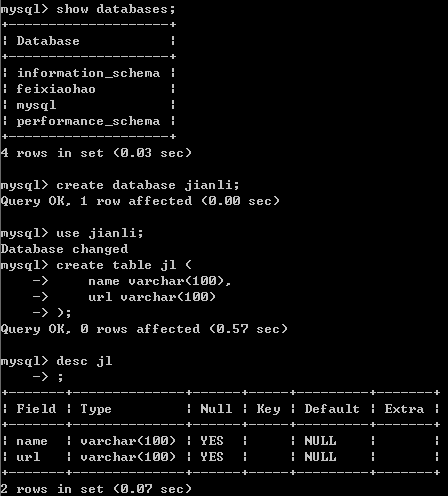
然后编写各个模块
item.py
import scrapy class JianliItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
pipeline.py
import pymysql #导入数据库的类 class JianliPipeline(object):
conn = None
cursor = None def open_spider(self,spider):
print('开始爬虫')
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='jianli') #链接数据库 def process_item(self, item, spider): #编写向数据库中存储数据的相关代码
self.cursor = self.conn.cursor() #1.链接数据库
sql = 'insert into jl values("%s","%s")'%(item['name'],item['url']) #2.执行sql语句 try: #执行事务
self.cursor.execute(sql)
self.conn.commit() except Exception as e:
print(e)
self.conn.rollback() return item def close_spider(self,spider):
print('爬虫结束')
self.cursor.close()
self.conn.close()
spider
# -*- coding: utf-8 -*-
import scrapy
import re
from lxml import etree
from jianli.items import JianliItem class FxhSpider(scrapy.Spider):
name = 'jl'
# allowed_domains = ['feixiaohao.com']
start_urls = ['http://sc.chinaz.com/jianli/free_{}.html'.format(i) for i in range(3)] def parse(self,response):
tree = etree.HTML(response.text)
a_list = tree.xpath('//div[@id="container"]/div/a') for a in a_list:
item = JianliItem (
name=a.xpath("./img/@alt")[0],
url=a.xpath("./@href")[0]
) yield item
settings.py
#USER_AGENT
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
} # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jianli.pipelines.JianliPipeline': 300,
}
查看存储情况
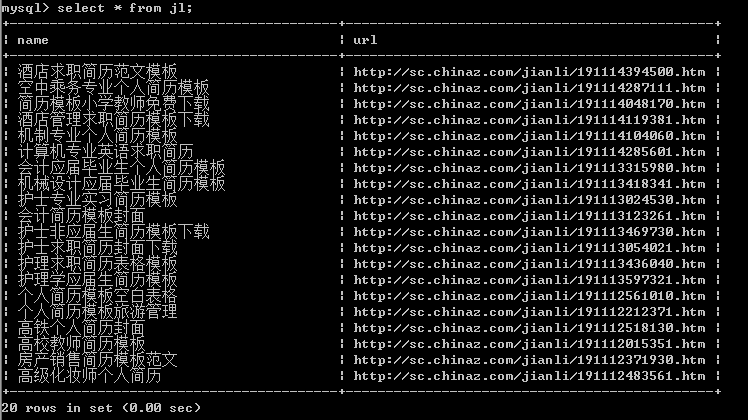
最新文章
- Docker 总结(转载)
- Android Programming: Pushing the Limits -- Chapter 3: Components, Manifests, and Resources
- 机器学习编程语言之争,Python 夺魁【转载+整理】
- 一种读取Exchange的用户未读邮件数方法!
- C#基础练习(时间的三连击)
- 解决TestNG报java.net.SocketException
- ORA-02041: client database did not begin a transaction
- 13个Cat命令管理(显示,排序,建立)文件实例
- 基于jQuery的上下左右无缝滚动应用(单行或多行)
- 排名最重要的三个优化阶段分析 --------------------->>转至(卧牛SEO/武汉SEO http://blog.sina.com.cn/zhengkangseo )
- 【转】常用背景色RGB数值
- PL SQLDEVELOPMENT导出数据库脚本
- 2014年最新的辛星html、css教程打包公布了,免积分,纯PDF(还有PHP奥)
- python第三方扩展库及不同类型的测试需安装相对应的第三方库总结
- 数据结构3——浅谈zkw线段树
- nginx系列10:通过upstream模块选择上游服务器和负载均衡策略round-robin
- mybatis 异常和注意
- poj 1932 XYZZY(spfa最长路+判断正环+floyd求传递闭包)
- tableview中头部信息
- Redis 未授权访问漏洞(附Python脚本)