Python统计字符出现次数(Counter包)以及txt文件写入
2024-10-19 14:34:48
# -*- coding: utf-8 -*-
#spyder (python 3.7)
1. 统计字符(可以在jieba分词之后使用)
from collections import Counter
from operator import itemgetter # txt_list可以写成函数参数进行导入
txt_list = ['千古','人间','人间','龙','龙','龙','哈哈哈','人才','千古','千古']
c = Counter()
for x in txt_list:
if len(x) >= 1:
if x == '\r\n' or x == '\n' or x == ' ':
continue
else:
c[x] += 1
print('常用词频统计结果: \n')
for (k, v) in c.most_common(4): #打印排名前四位
print('%s%s %s %d' % (' ' * (3 ), k, '*' * 3, v)) # 按照词频数从大到小打印
d = sorted(c.items(),key=itemgetter(1),reverse = True)
for ss,tt in d:
out_words=ss + '\t' + str(tt)
print(out_words)
2. 多次覆盖,循环写入文件
#写入文件,多次写入,后一次覆盖前一次,但是out_words本身是在叠加的
#即:第一次写入的是:千古\t3\n;第二次写入的是:千古\t3\n龙\t3\n,覆盖上一次的数据;
#第三次是:千古\t3\n龙\t3\n人间\t2\n,继续覆盖上一次的数据
out_words = ''
for ss,tt in d:
out_words=out_words + ss + '\t' + str(tt) + '\n'
with open(r".\sss.txt", "w",encoding='utf-8') as f:
f.write(out_words+'\n')
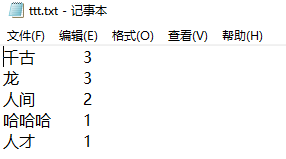
比如,循环两次的结果是:

3. 一次性写入文件,中间不会覆盖和多次写入;但是如果重复运行代码,则会覆盖之前的全部内容,一次性重新写入所有新内容
out_words = ''
for ss,tt in d:
out_words=out_words + ss + '\t' + str(tt) + '\n'
with open(r".\ttt.txt", "w",encoding='utf-8') as f:
f.write(out_words+'\n')
最新文章
- percona教程:MySQL GROUP_CONCAT的使用
- Tarjan应用:求割点/桥/缩点/强连通分量/双连通分量/LCA(最近公共祖先)【转】【修改】
- java调用cmd命令删除文件夹及其所有内容
- [BZOJ2879][Noi2012]美食节(最小费用最大流动态加边)
- WordPress 插件机制的简单用法和原理(Hook 钩子)
- 手机/平板 连接局域网访问局域网电脑Web服务器进行移动端页面测试
- Java——jdk1.5新特性
- 使用模板时 error LNK2019: 无法解析的外部符号
- iOS常见内存泄漏解决
- css如何使背景图片水平居中
- Qt自定义带游标的slider,在滑块正上方显示当前值(非常有意思,继承QSlider之后增加一个QLabel,然后不断移动它)
- 动手学习TCP:数据传输(转)
- 命令行解决mysql中文乱码
- Linux编程之内存池的设计与实现(C++98)
- qml layout
- Ubuntu12.04中的虚拟机安装Ubuntu16.04,并实现远程控制16.04
- Java_13.1.1 字符串的应用
- 别人的Linux私房菜(1)计算机概论
- Linux CentOS 5.5 服务器安装图文教程
- STM32 GPIO fast data transfer with DMA