Lucene 索引功能
Lucene 数据建模
基本概念
文档(doc): 文档是 Lucene 索引和搜索的原子单元,文档是一个包含多个域的容器。
域(field): 域包含“真正的”被搜索的内容,每一个域都有一个标识名称,而“域值”则是实际被搜索的对象。
词元(term): 每个域的域值可能为一个复合字符串,通过分析器的各种处理,能将其分解为可以被搜索的词元。例如:"中国人China",其中包含的词元有:"中"、"国"、"人"、"china"。
与数据库的比较
灵活的架构: Lucene 没有一个确定的全局模式,加入索引的每一个文档都是独立的,与之前加入的文档没有任何关系。
反向规格化: Lucene 需要解决文档真实结构和 Lucene 表示能力之间的不匹配问题。因为 Lucene 文档都是单一文档,互相没有关系。无法像数据库中通过键将不同的表关联起来。
索引过程
流程示意

- 提取文本和创建文档:从各种原始数据,比如 XML 文档、syslog 日志、网络数据包等提取出预想的文本信息并建立起对应的、包含各个域的文档。
- 分析文档:将文本数据分割为词汇单元串,然后执行一些可选操作(转小写、去掉 a/an/the/on/in 等),得到能够被搜索的词元(term)。
- 向索引添加文档:对输入数据分析完毕后就可以将分析结果写入索引文件中。
- Lucene 的索引是倒排索引,倒排索引回答"哪些文档包含XXX词元"这样的问题,而不是回答"XXX文档包含有哪些词元"。
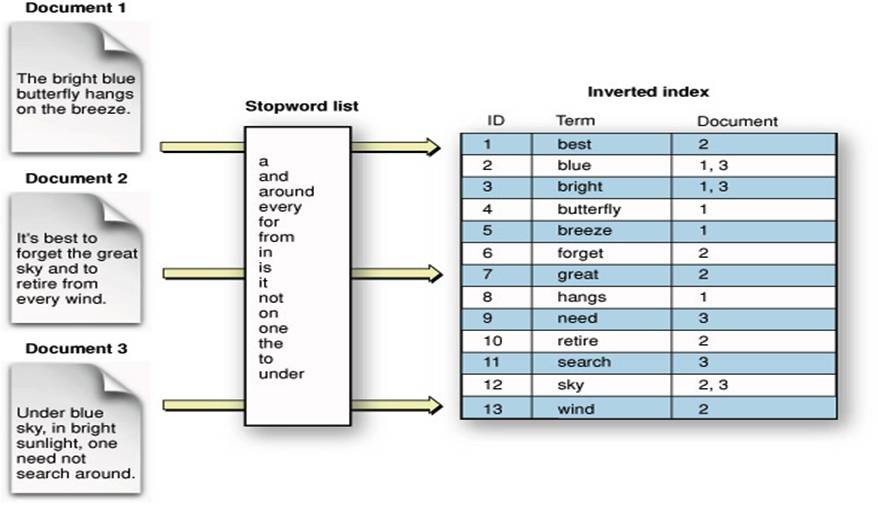
倒排索引
分词:
为了创建倒排索引,需要先将各文档(docs)中域(field)的值切分为独立的单词(term),而后将之创建为一个无重复的有序单词列表。这个过程称之为“分词(tokenization)”。
标准化:
为了实现 full-text 域的搜索,倒排索引中的数据还需进行“标准化(normalization)”为标准格式,才能评估其与用户搜索请求字符串的相似度。
例如,将所有大写字符转换为小写,将复数统一为单数,将同义词统一进行索引,去掉类似 the/is/a/ 等这样的 "停用词(stopword)" 等。
分析:
“分词” 和 “正规化” 过程被称为分析,由 Analyzer 完成。
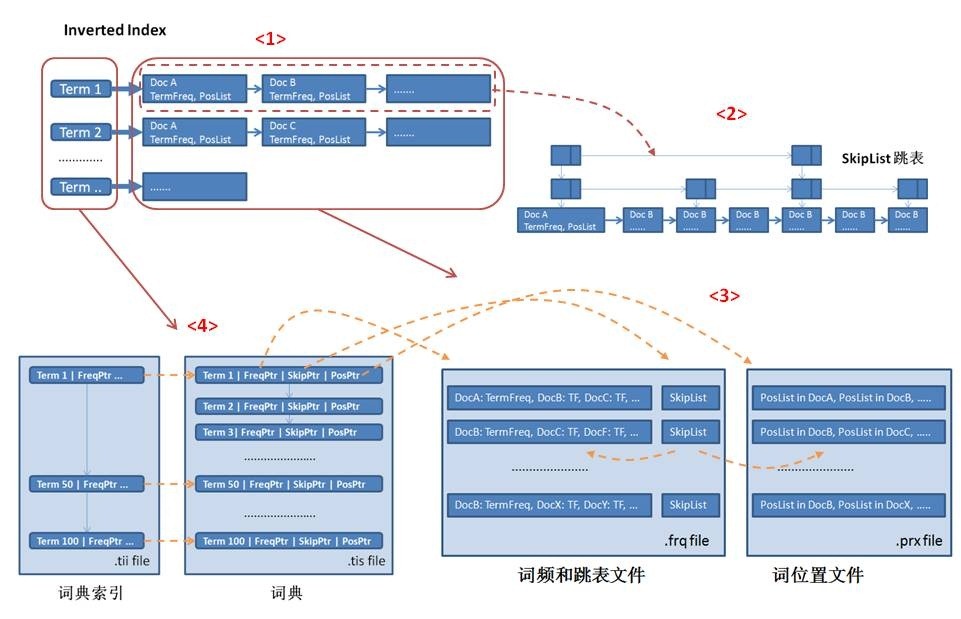
索引结构:
index:一个索引存放在一个目录中。
segment:一个索引中可以有多个段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段。
document:文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档。
field:域,一个文档包含不同类型的信息,可以拆分开索引。
term:词,索引的最小单位,是经过词法分析和语言处理后的数据。
索引正向信息:
按照层次依次保存了从索引到词的包含关系:
index-->segment-->document-->field-->term。
索引反向信息
反向信息保存了词典的倒排表映射:
term-->document
索引结构图:
基本索引操作
向索引添加文档:
- addDocument(Document) ————使用默认分析器添加文档,该分析器在创建IndexWriter对象时指定,用于词汇单元化操作
- addDocument(Document, Analyzer) ————使用指定的分析器添加文档和词汇单元化操作
删除索引中的文档:
- deleteDocuments(Term) ————删除包含 term 的所有文档
- deleteDocuments(Term[]) ————删除包含 term 数组任意元素的所有文档
- deleteDocuments(Query) ————删除匹配查询语句的所有文档
- deleteDocuments(Query[]) ————删除匹配查询语句数组任意元素的所有文档
- deleteAll(term) ————删除索引中所有文档
跟更新索引中的文档:
Lucene 只能删除整个旧文档再重新添加新文档,即便是更新 API 实际执行的操作也是如此。
- updateDocument(Term, Document) ————先删除包含 term 变量的文档,在使用 writer 的默认分析器添加新文档
- updateDocument(Term, Document, Analyzer) ————功能与上面一致,不过可以指定分析器
域选项
域索引选项:
通过倒排索引来控制域文本是否可以被搜索。
- Index.ANALYZED ————使用分析器将域值分解成独立的词汇单元流
- Index.ANALYZED_NO_NORMS ————同上,不过不在索引中存储 norems 信息,可节省内存
- Index.NOT_ANALYZED ——————不对 string 进行分析,将域值作为单一次元进行索引
- Index.NOT_ANALYZED_NO_NORMS ——————同上,不过不在索引中存储norems信息,可节省内存
- Index.NO ——————使得对应域不可搜索
域存储选项:
用来确定是否需要存储域的真实值以便后续搜索时能恢复这个值。
- Store.YES————指定存储域值,原始的字符串值全部被保存在索引中
- Store.NO——————指定不存储域值
域的项向量选项:
Reader、TokenStream、byte[]域值:
域排序选项:
多值域:
对文档和域进行加权操作
当改变一个文档或域的加权因子时,必须完全删除并创建对应的文档,或者使用 updateDocument(起始也是删除再新建)方法。
文档加权操作:
通过文档加权因子,能够指示Lucene在计算相关性时考虑该文档针对索引中其它文档的重要程度。
- Document 的 setBoost(float) 方法
域加权操作:
通过域加权因子,能够指示Lucene在计算相关性时考虑该文档针对索引中其它文档的重要程度
- Field 的 setBoost(float) 方法
加权基准(Norms):
索引数字、日期和时间
索引数字:
- 在字符串中包含数字:通过选择分析器(有些分析器会把"It is a long time from 1900"中的数字去掉,不解析为词元)来保证字符串中的数字不被丢弃,而被当成一个 string 类型的词元(term)
- 只包含数字的域:要实现对数字域的范围搜索和排序,需要 NumericField 的 set 方法设置域类型为 long/int/float 之一
索引日期和时间:
- Lucene 首先将他们转换为数值类型(Unix 时间戳)再进行索引
域截取
对一些文档,比如二进制数据,解析失败可能会导致在索引创建大量的无用的域,域截取可以加以控制,以下为2个默认实例。
- MaxFieldLength.UNLIMITED ————不采取截取
- MaxFieldLength.LIMITED ————截取前1000项
其它 Directory 子类
Lucene 的抽象类 Directory 提供了一个简单的文件存储 API,当操作索引文件进行读写时候,需要调用 Directory 子类的对应方法来进行。
子类负责从文件系统中读写文件,都是继承于抽象基类 FSDirectory。
- SimpleFSDirectory ————使用 java.io.* API 将文件存入文件系统
- NIOFSDirectory ————使用 java.nio.* API 将文件保存至文件系统
- MMapDirectory ————使用内存映射 I/O 进行文件访问
- RAMDirectory ————将所有文件都存入 RAM
- FileSwitchDirectory ————使用两个文件目录,根据文件扩展名在两个目录之间进行切换
高级索引话题
一些未细化讨论的Lucene索引的高级概念。包括:
- 用IndexReader删除文档
- 回收被删除文档的磁盘空间
- 缓冲和刷新
- 索引提交
- ACID事务和索引连续性
- 合并段
最新文章
- NPOI读取Excel 数据 转。。。
- Android根据文件路径加载指定文件
- js6类和对象
- struts (二)
- php 安全处理方案
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
- UVA 1658 Admiral 海上将军(最小费用流,拆点)
- 存储过程&Function
- iOS开发——C篇&动态内存分析
- Gamma网址
- 浅析NopCommerce的多语言方案
- STL(set_pair)运用 CF#Pi D. One-Dimensional Battle Ships
- Spring Cloud学习笔记-008
- zuul源码(2)
- TCP与UDP区别小结
- class ObjectOutputStream也是过滤流,使节点流直接获得输出对象。
- Vue插件写、用详解(附demo)
- 20135202闫佳歆--week7 可执行程序的装载--学习笔记
- java并发基础(六)--- 活跃性、性能与可伸缩性
- thuwc2019总结