Spark SQL利器:cacheTable/uncacheTable
2024-10-19 13:18:14
Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个MapReduce的忠实粉丝,能这样说,大家都懂了吧),这在我们的业务场景里真的是非常有用。
假设我们有一个文本文件“datas”,每一行有三列数据,以“\t”分隔,模拟生成文件的代码如下:
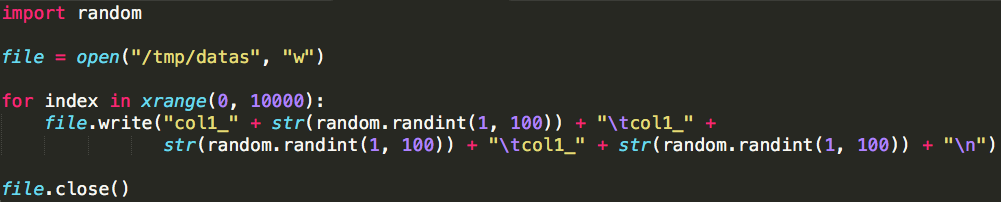
执行该代码之后,文本文件会存储于本地路径:/tmp/datas,它包含1000行测试数据,将其上传至我们的测试Hadoop集群,路径:/user/yurun/datas,命令如下:

查询一下它的状态:

我们通过Spark SQL API将其注册为一张表,代码如下:
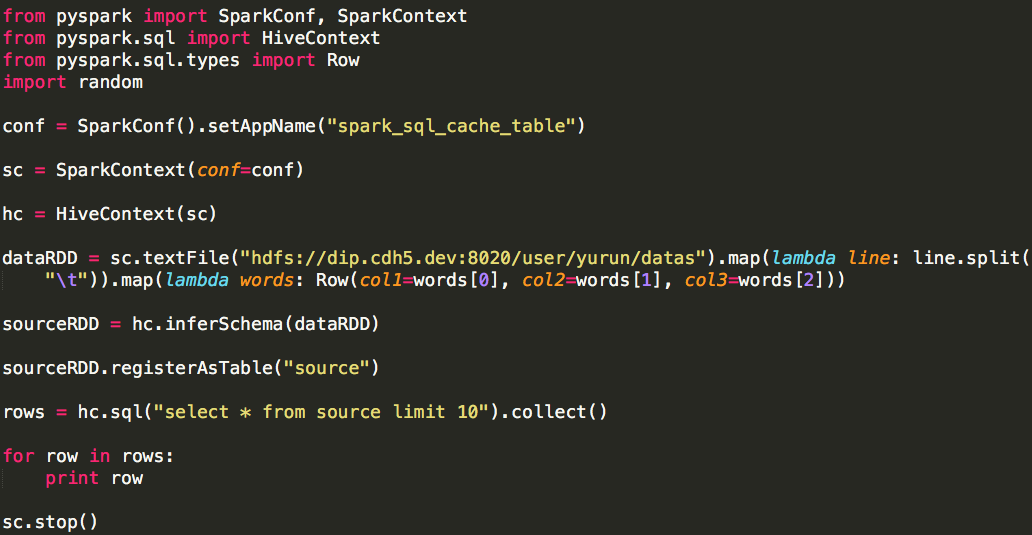
表的名称为source,它有三列,列名分别为:col1、col2、col3,类型都为字符串(str),测试打印其前10行数据:

假设我们的分析需求如下:
(1)过滤条件:col1 = ‘col1_50',以col2为分组,求col3的最大值;
(2)过滤条件:col1 = 'col1_50',以col3为分组,求col2的最小值;
注意:需求是不是很变态,再次注意我们只是模拟。
通过情况下我们可以这么做:

每一个collect()(Action)都会产生一个Spark Job,

因为这两个需求的处理逻辑是类似的,它们都有两个Stage:


可以看出这两个Job的数据输入量是一致的,根据输入量的具体数值,我们可以推断出这两个Job都是直接从原始数据(文本文件)计算的。
这种情况在Hive(MapReduce)的世界里是很难优化的,处理逻辑虽然简单,却无法使用一条SQL语句表述(有的是因为分析逻辑复杂,有的则因为各个处理逻辑的结果需要独立存储),只能一个需求对应一(多)条SQL语句(如上示例),带来的问题就是全量原始数据多次被分析,在海量数据的场景下必然带来集群资源的巨大浪费。
其实这两个需求有一个共同点:过滤条件相同(col1 = 'col1_50'),一个很自然的想法就是将满足过滤条件的数据缓存,然后在缓存数据之上执行计算,Spark为我们做到了这一点。
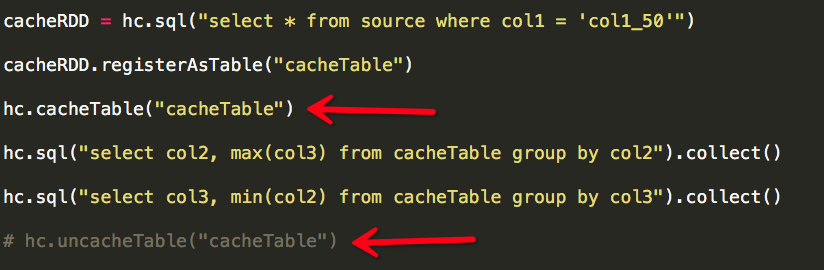
依然是两个Job,每个Job仍然是两个Stage,但这两个Stage的输入数据量(Input)已发生变化:


Job1的Input(数据输入量)仍然是63.5KB,是因为“cacheTable”仅仅在RDD(cacheRDD)第一次被触发计算并执行完成之后才会生效,因此Job1的Input是63.5KB;而Job2执行时“cacheTable”已生效,直接输入缓存中的数据即可,因此Job2的Input减少为3.4KB,而且因为所需缓存的数据量小,可以完全被缓存于内存中,因此效率极高。
我们也可以从Spark相关页面中确认“cache”确实生效:

我们也需要注意cacheTable与uncacheTable的使用时机,cacheTable主要用于缓存中间表结果,它的特点是少量数据且被后续计算(SQL)频繁使用;如果中间表结果使用完毕,我们应该立即使用uncacheTable释放缓存空间,用于缓存其它数据(示例中注释uncacheTable操作,是为了页面中可以清楚看到表被缓存的效果)。
最新文章
- OpenCASCADE Ring Type Spring Modeling
- iOS 推送小记
- 使用Python调用Flickr API抓取图片数据
- Jmeter性能测试入门(链接收藏)
- [Python] Keep efficient by vim in Pycharm
- poj3207 2-SAT入门
- OpenCV show two cameras 同时显示两个摄像头
- C#获取进程的主窗口句柄的实现方法
- POJ 2127 Greatest Common Increasing Subsequence -- 动态规划
- Ubuntu 14.04 配置 Java SE
- WordPress HMS Testimonials 多个跨站脚本漏洞和跨站请求伪造漏洞
- 监控父元素里面子元素内容变化 DOMSubtreeModified
- android浏览器开发小技巧集锦(转)
- 纯CSS3彩色边线3D立体按钮制作教程
- mvc中razor的一个bug
- grid 布局
- SQL Server 2016 行级别权限控制
- 贼有意思[最长上升公共子序列](SAC大佬测试题)
- kettle使用记录
- QT中pro文件编写的详细说明