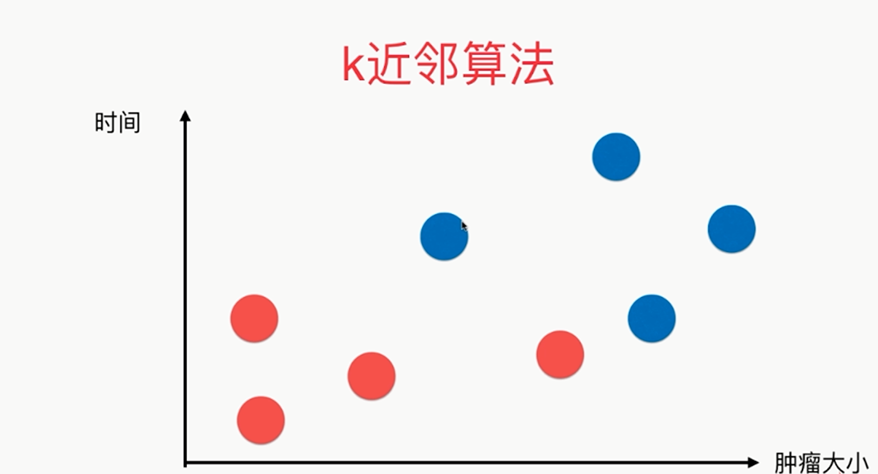
第4章 最基础的分类算法-k近邻算法
2024-09-29 07:17:19
思想极度简单
应用数学知识少
效果好(缺点?)
可以解释机器学习算法使用过程中的很多细节问题
更完整的刻画机器学习应用的流程


distances = []
for x_train in X_train:
d=sqrt(np.sum((x_train-x)**2))
distances.append(d)
distances=[sqrt(np.sum((x_train-x)**2)) for x_train in X_train]
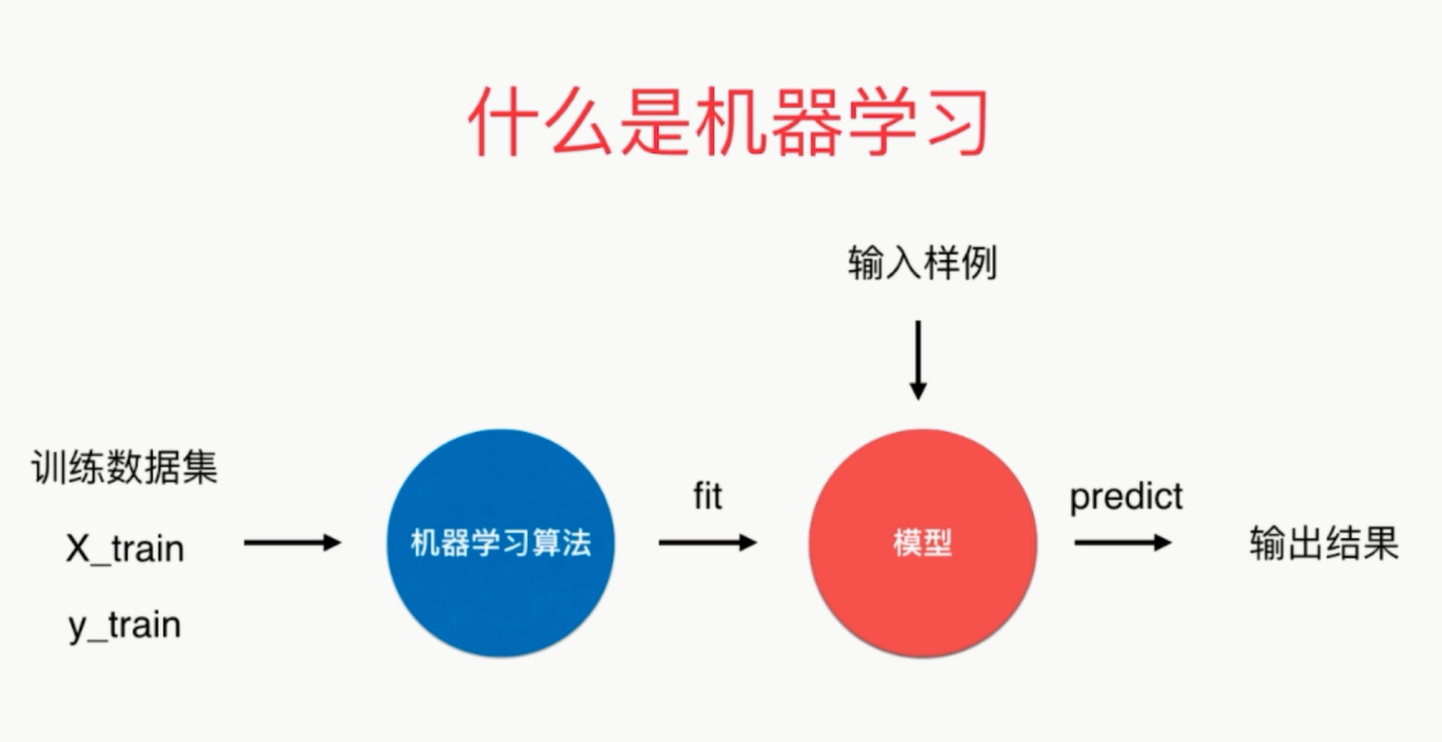
可以说kNN是一个不需要训练过程的算法
K近邻算法是非常特殊的,可以被认为是没有模型的算法
为了和其他算法统一,可以认为训练数据集就是模型本身
kNN:
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier=KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train,y_train)
kNN_classifier.predict(x)
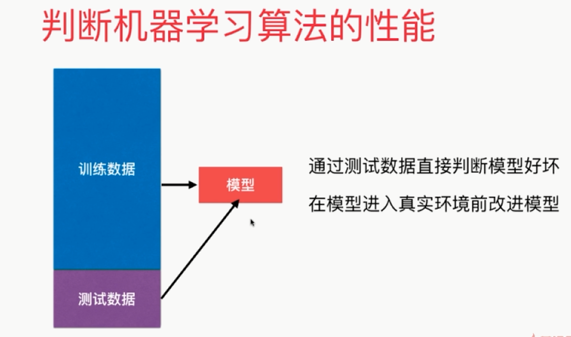
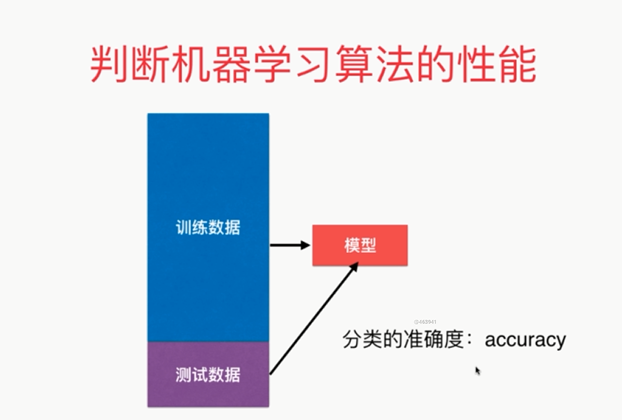
有关K近邻算法
解决分类问题
天然可以解决多分类问题
思想简单,效果强大
使用k近邻算法解决回归问题
KNeighborsRegressor
kNN:
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier=KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train,y_train)
kNN_classifier.predict(x)




须考虑距离的权重!通常是将距离的倒数作为权重





相当于因为距离又获得了一个超参数

寻找最好的k,调参
best_score = 0.0
besk_k = -1
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score>best_score:
best_k=k
best_score=score print('best_k=',best_k)
print('best_score=',best_score) 考虑距离?
best_method = ''
best_score = 0.0
besk_k = -1
for method in ['uniform','distance']:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights=method)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score>best_score:
best_k=k
best_score=score
best_method = method
print('best_k=',best_k)
print('best_score=',best_score)
print('best_method',best_method) 搜索明可夫斯基距离相应的p
%%time
best_p = -1
best_score = 0.0
besk_k = -1
for k in range(1,11):
for p in range(1,6):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights='distance',p = p)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score>best_score:
best_k=k
best_score=score
best_p=p
print('best_k=',best_k)
print('best_score=',best_score)
print('best_p=',best_p)



缺点2:高度数据相关
缺点3:预测的结果不具有可解释性
缺点4:维数灾难
随着维度的增加,‘看似相近’的的两个点之间的距离越来越大

解决方法:降维(PCA)
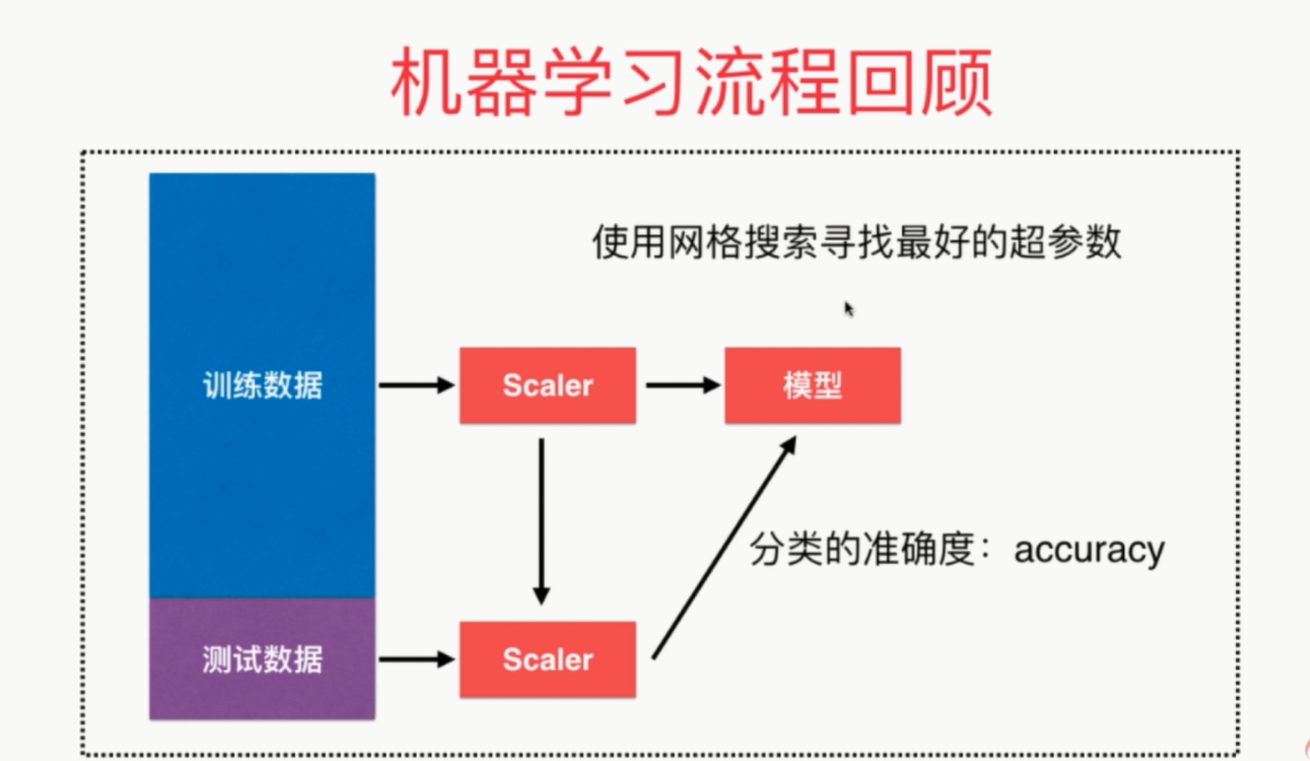
# coding=utf-8
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score # 分类的准确度
from sklearn.model_selection import GridSearchCV iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=666)
standardScaler = StandardScaler() # 创建实例
standardScaler.fit(X_train)
# standardScaler.mean_
# standardScaler.scale_
X_train = standardScaler.transform(X_train) # 使用transform方法进行归一化
X_test_standard = standardScaler.transform(X_test) # 寻找最好的参数K
# param_grid = [
# {
# 'weights': ['uniform'],
# 'n_neighbors': [i for i in range(1, 11)]
# },
# {
# 'weights': ['distance'],
# 'n_neighbors': [i for i in range(1, 11)],
# 'p': [i for i in range(1, 6)]
# }
# ]
# knn_clf = KNeighborsClassifier()
# grid_search = GridSearchCV(knn_clf, param_grid)
# grid_search.fit(X_train, y_train)
# print(grid_search.best_estimator_, grid_search.best_params_, grid_search.best_score_)
# knn_clf.predict(X_test)
# knn_clf.score(X_test, y_test) knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train) # X_train已经进行了归一化
print(knn_clf.score(X_test_standard, y_test))
# 或者
y_predict = knn_clf.predict(X_test_standard)
print(accuracy_score(y_test, y_predict))
knn_clf.score(X_test_standard, y_test)
个人整个流程代码
最新文章
- Unity3D项目开发一点经验
- 宫格布局实例(注意jquery的版本号要统一)2
- C++ STL中vector(向量容器)使用简单介绍
- PHP获取APK的包信息
- hdu 1861-游船出租
- JAVA模块化
- 使用GBK编码请求访问nodejs程序报415错误:Error: unsupported charset at urlencodedParser ...
- github 上传或删除 文件 命令
- sed的选项与命令简要
- 一步一步写算法(之prim算法 中)
- 开源视频平台:MediaCore(MediaDrop)
- UE4中如何使物体始终朝向摄像头?
- Django之路由分发和反向解析
- VS2017用正则表达式替换多行代码
- Docker 二进制安装docker
- 深入理解Java虚拟机之Java内存区域随笔
- JavaSE-基础语法(二)-系统类(java.lang.*)和工具类(java.util.*)
- Android 自定义倒计时控件CountdownTextView
- lightoj 1205 数位dp
- iOS10 推送必看 UNNotificationContentExtension