【Python】容器:列表(list)/字典(dict)/元组(tuple)/集合(set)
三、Python容器:列表(list)/字典(dict)/元组(tuple)/集合(set)
1、列表(list)
1.1 什么是列表
是一个‘大容器’,可以存储N多个元素简单来说就是其他语言中的数组。是一种有序的容器,放入list中的元素,将会按照一定顺序排列。和变量的区别,变量只可以存储一个对象的引用
1.2 创建
① 列表需要使用中括号[],元素之间使用英文的逗号进行分割
② 创建方式一:使用中括号
③ 创建方式二:使用内置函数list()
④ 创建方式三:列表生成式。简称为:生成列表的公式。注意:‘表达列表元素的表达式’中通常包含自定义变量
# 创建方式一
lis1 = ['hello', 'world', 98]
# 创建方式二
lst2 = list(['hello', 'world', 98])
# 创建方式三
lst = [i*i for i in range(1,10)]
print(lst) # ==>[1, 4, 9, 16, 25, 36, 49, 64, 81]
1.3 特点
① 列表元素按顺序有序排列
② 索引映射唯一一个数据
③ 列表可以存储重复数据
④ 任意数据类型混存
⑤ 根据需要动态分配和回收内存
1.4 查询(获取列表中单个元素)
① 获取列表中制定元素的索引
# 获取索引
lis1 = ['hello', 'world', 98, 'hello', 8.6]
# 1、如查列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
print(lis1.index('hello')) # ==>0
# 2、如果查询的元素在列表中不存在,则会抛出ValueError
print(lis1.index('python')) # ==>ValueError
# 3、还可以在指定的start和stop之间查找
print(lis1.index('hello', 1, 4)) # ==>3
② 获取列表中的单个元素
# 获取单个元素
lis1 = ['hello', 'world', 98, 'hello', 8.6]
# 1、正向索引从0到1
print(lis1[2]) # ==>98
# 2、逆向索引从-1开始
print(lis1[-2]) # ==>hello
# 3、指定索引不存在,抛出IndexError
print(lis1[10]) # ==>IndexError
③ 判断元素是否在列表中存在
lst = ['hello', 'world', 10, 'hello', 8.6]
print(10 in lst) # ==>True
print(99 in lst) # ==>False
print(100 not in lst) # ==>True
④ 列表元素的遍历
# 遍历列表
lst = ['hello', 'world', 10, 'hello', 8.6]
for item in lst:
print(item)
1.5 切片(获取列表中多个元素)
① 语法:列表名[start, stop, step]
② 切片的结果:原列表片段的拷贝
③ 切片的范围:[start, stop]
④ step默认为1:简写为[start, stop]
⑤ step为正数:从start开始往后计算切片
[:stop:step]切片的第一个元素默认是列表的第一个元素
[start::stop]切片的最后一个元素默认是列表的最后一个元素
⑥ step为负数:从start开始往前计算切片
[:stop:step]切片的第一个元素默认是列表的最后一个元素;
[start::stop]切片的最后一个元素默认是列表的第一个元素
# 切片练习
lis = [10, 20, 30, 40, 50, 60, 70, 80]
# start=1,stop=6,step=1
print(lis[1:6:1]) # ==>[20, 30, 40, 50, 60]
print(lis[1:6]) # 默认步长为1 (可写,可省略,也可不写) ==>[20, 30, 40, 50, 60]
print(lis[1:6:]) # ==>[20, 30, 40, 50, 60]
# start=1,stop=6,step=2
print(lis[1:6:2]) # ==>[20, 40, 60]
# start为空,stop=6,step=2
print(lis[:6:2]) # start为空,则从0开始 ==>[10, 30, 50]
# start=1,stop为空,step=2
print(lis[1::2]) # stop为空,则从指定位置查到最后一个元素 ==>[20, 40, 60, 80] # step为负数
print('原列表:', lis) # ==>原列表: [10, 20, 30, 40, 50, 60, 70, 80]
print(lis[::-1]) # 将原列表反过来了 # ==>[80, 70, 60, 50, 40, 30, 20, 10]
# start=7,stop省略,step=-1
print(lis[7::-1]) # ==>[80, 70, 60, 50, 40, 30, 20, 10]
# start=6,stop=0,step=-2
print(lis[6:0:-2]) # ==>[70, 50, 30]
1.6 增加操作
① append():在列表的末尾添加一个元素
② extend():在列表的末尾至少添加一个元素
③ insert():在列表的任意位置添加一个元素
④ 切片:在列表的任意位置添加至少一个元素
# 添加元素练习
lst = [10, 20, 30]
lst.append(100)
print(lst) # ==>[10, 20, 30, 100] lst2 = ['hello', 'world']
lst.append(lst2) # 将lst2作为一个元素添加到列表末尾
print(lst) # ==>[10, 20, 30, 100, ['hello', 'world']] lst.extend(lst2) # 将lst2中每个元素添加到列表末尾
print(lst) # ==>[10, 20, 30, 100, ['hello', 'world'], 'hello', 'world'] lst.insert(1, 'python') # 添加到指定索引的位置
print(lst) # ==>[10, 'python', 20, 30, 100, ['hello', 'world'], 'hello', 'world'] lst3 = [True, False, 'hello']
lst[1:] = lst3 # 相当于把切片的内容全部切掉,然后添加新的元素
print(lst) # ==>[10, True, False, 'hello']
1.7 删除操作
① remove():一次只能删除一个,重复元素只删除第一个,元素不存在则报ValueError
② pop():删除一个指定索引位置上的元素,指定索引不存在抛出IndexError,不指定索引时删除列表中最后一个元素
③ 切片:一次至少删除一个元素
④ clear():清空列表
⑤ del:删除列表
# 删除练习
lis = [10, 20, 30, 40, 50, 60, 30]
# 从列表中移除一个元素,如果有重复的移除第一个
lis.remove(30)
print(lis) # ==>[10, 20, 40, 50, 60, 30]
# remove元素不存在报错
lis.remove(100)
print(lis) # ==>ValueError # pop删除指定索引的值
lis.pop(1)
print(lis) # ==>[10, 40, 50, 60, 30]
# pop删除索引不存在会报错
lis.pop(5)
print(lis) # ==>IndexError
# pop不指定参数,删除最后一个
lis.pop()
print(lis) # ==>[10, 40, 50, 60] # 切片:删除至少一个元素,但是会产生新的列表对象
new_lis = lis[1:3]
print('原列表:', lis) # ==>原列表: [10, 40, 50, 60]
print('新列表:', new_lis) # ==>新列表: [40, 50]
# 切片:不产生新的列表对象,而是删除原列表中的内容
lis[1:3] = []
print(lis) # ==>[10, 60] # 清除列表
lis.clear()
print(lis) # ==>[] # del是直接将列表对象删除,这个对象没有了,当前不能调用了
del lis
print(lis) # ==>NameError
1.8 修改操作
① 为指定索引的元素赋予一个新值
② 为指定的切片赋予一个新值
# 修改练习
lst = [10, 20, 30, 40]
lst[2] = 100 # 一次修改一个值
print(lst) # ==>[10, 20, 100, 40] lst[1:3] = [300, 400, 500, 600] # 修改至少一个值
print(lst) # ==>[10, 300, 400, 500, 600, 40]
1.9 排序操作
① sort():列表中所有元素按照从小到大的顺序排序,使用reverse=True,进行降序排列
② 内置函数sorted():可以指定reverse=True,进行降序排列,原列表不发生变化
# 排序操作
lis = [20, 40, 10, 98, 54]
# 调用sort方法,默认是升序,不产生新的列表
lis.sort()
print(lis) # ==>[10, 20, 40, 54, 98]
lis.sort(reverse=True)
print(lis) # ==>[98, 54, 40, 20, 10]
lis.sort(reverse=False)
print(lis) # ==>[10, 20, 40, 54, 98] # 直接使用内置函数排序,默认为升序,会产生新的列表对象
lis2 = [20, 40, 10, 98, 54]
new_lis2 = sorted(lis2)
print('原列表:', lis2) # ==>原列表: [20, 40, 10, 98, 54]
print('新列表:', new_lis2) # ==>新列表: [10, 20, 40, 54, 98]
# 降序排列
new_lis3 = sorted(lis2, reverse=True)
print(new_lis3) # ==>[98, 54, 40, 20, 10]
2、字典(dict)
2.1 什么是字典
python中内置的数据结构之一,与列表一样是一个可变序列。以键值对的方式存储数据,字典是一个无序的序列
2.2 创建
① 创建方式一:使用花括号
② 创建方式二:使用内置函数dict()
③ 创建方式三:使用内置函数zip()
# 使用{}来创建
score = {'张三': 100, '李四': 98, '王五': 45}
print(score)
print(type(score))
# 使用dict()创建
student = dict(name='jack', age=20)
print(student) # ==>{'name': 'jack', 'age': 20}
# 创建一个空字典
d = {}
print(d)
# 使用内置函数zip
items = ['fruits', 'books', 'other']
prices = [98, 78, 67, 100, 102]
d = {item: price for item, price in zip(items, prices)}
print(d) # 使用zip函数时会以短的为基准,多余的忽略 ==>{'fruits': 98, 'books': 78, 'other': 67}# 使用{}来创建
score = {'张三': 100, '李四': 98, '王五': 45}
print(score)
print(type(score))
2.3 特点
① 字典中的所有元素都是一个key-value对,key不允许重复,vlaue可以重复
② 字典中的元素是无序的
③ 字典中的key必须是不可变对象
④ 字典也是可以根据需要动态的伸缩
⑤ 字典会浪费较大的内存,是一种使用空间换时间的数据结构
2.4 元素查询
① []
② get()方法
③ []和get()取值的区别:[]如果字典中不存在指定的key,抛出keyError异常;get()取值,如果字典中不存在指定key,不会拋异常而是返回None,可以通过参数设置默认的vlaue,可以在key不存在时返回
# 元素查询[]方式
score = {'张三': 100, '李四': 98, '王五': 45}
# 方式一:[]方式
print(score['张三'])
print(score['陈六']) # key不存在时会报KeyError # 方式二:get方式
print(score.get('张三'))
print(score.get('陈六')) # ==>None
print(score.get('拉拉', 99)) # ==>99是查找拉拉时如果不存在返回的默认值
2.5 常用操作
① key的判断:in / not in
② 元素的删除:del / clear()
③ 元素的新增:直接指定key对应的值
score = {'张三': 100, '李四': 98, '王五': 45}
# key的判断
print('张三' in score) # ==>True
print('张三' not in score) # ==>False
# 删除元素
del score['张三'] # 删除指定的key-vlaue对
print(score) # ==>{'李四': 98, '王五': 45}
score.clear() # 清空字典中所有元素
print(score) # ==>{}
# 新增元素
score['哈哈'] = 50 # 新增时若key不存在则新增
print(score) # ==>{'李四': 98, '王五': 45, '哈哈': 50}
# 修改元素
score['哈哈'] = 100 # 新增时若key存在则修改key对应的value值
print(score) # ==>{'李四': 98, '王五': 45, '哈哈': 100}
2.6 获取字典视图
① keys():获取字典中所有key
② values():获取字典中所有vlaue值
③ items():获取字典中所有key,vlaue对
score = {'张三': 100, '李四': 98, '王五': 45}
# 获取所有的key
keys = score.keys()
print(keys) # ==>dict_keys(['张三', '李四', '王五'])
print(type(keys)) # ==><class 'dict_keys'>
print(list(keys)) # 将key转化为list列表格式 ==>['张三', '李四', '王五']
# 获取所有的value
values= score.values()
print(values) # ==>dict_values([100, 98, 45])
print(type(values)) # ==><class 'dict_values'>
print(list(values)) # ==>[100, 98, 45]
# 获取所有key-value
items = score.items()
print(items) # ==>dict_items([('张三', 100), ('李四', 98), ('王五', 45)])
print(type(items)) # ==><class 'dict_items'>
print(list(items)) # ==>[('张三', 100), ('李四', 98), ('王五', 45)]
2.7 字典元素的遍历
score = {'张三': 100, '李四': 98, '王五': 45}
# 字典的遍历
for item in score:
print(item) # ==> 输出的是字典中的key
print(score[item]) # ==> 输出的是字典中的value
print(score.get(item)) # ==> 输出的是字典中的value
3、元组(tuple)
3.1 元组:不可变序列
3.2 创建
① 创建方式一:使用小括号
② 创建方式二:使用内置函数tuple()
③ 创建方式三:只包含一个元组的元素需要使用逗号和小括号
# 方式一
t = ('python', 'world', 98)
print(t)
print(type(t))
t2 = 'python', 'world', 98 # 小括号可以省略
print(t2)
print(type(t2)) # 方式二
t1 = tuple(('python', 'world', 98))
print(t1)
print(type(t1)) # 方式三:创建一个元素的元组
t3 = ('python',) # 只有一个元素时必须加上逗号
print(t3)
print(type(t3))
# 空元组创建
t4 = ()
print(t4)
print(type(t4))
t5 = tuple()
print(t5)
print(type(t5))
3.3 为什么元组是不可变序列
① 在多任务环境下,同时操作对象时不需要加锁,因此在程序中尽量使用不可变序列
② 元组中存储的是对象的引用。
③ 如果元组中对象本身不可对象,则不能在引用其他对象
④ 如果元组中的对象是可变对象,则可变对象的引用不允许改变,但是数据可以改变
t = (10, [20, 30], 9)
print(t[0], type(t[0]))
print(t[1], type(t[1]))
print(t[2], type(t[2]))
# 修改t[1]:不允许修改元素type,可以改变列表中的数据
t[1].append(100)
print(t) # ==>(10, [20, 30, 100], 9)
3.4 元组的遍历
① 使用索引:前提是知道有多少个元素,超出索引号则报错
② for-in循环
# 元组遍历
t = ('python', 'world', 98)
# 方式一:使用索引
print(t[0])
print(t[1])
print(t[2])
# 方式二:使用for-in
for item in t:
print(item)
4、集合(set)
4.1 什么是集合
① 内置数据结构
② 属于可变类型的序列
③ 集合是没有vlaue的字典
4.2 创建
① 创建方式一:使用花括号
② 创建方式二:使用内置函数set()
③ 创建方式三:集合生成式
# 集合的创建
# 方式一
s = {1, 2, 3, 4, 5, 4, 3, 6, 7}
print(s) # ==>{1, 2, 3, 4, 5, 6, 7}
# 方式二
s = set(range(6))
print(s) # ==>{0, 1, 2, 3, 4, 5}
# 列表转化集合,同时去掉重复元素
print(set([3, 4, 55, 59, 3])) # ==>{59, 3, 4, 55}
# 元组转化集合
print(set((4, 5, 6, 7))) # ==>{4, 5, 6, 7}
# 字符串转化集合
print(set('python')) # ==>{'h', 'n', 't', 'p', 'o', 'y'}
# 集合转化集合
print(set({9, 8, 7, 6})) # ==>{8, 9, 6, 7}
# 空集合:直接使用{}不行,{}默认是空字典
print(set()) # ==> set()
# 利用生成式
s = {i for i in range(1, 10)}
print(s) # ==>{1, 2, 3, 4, 5, 6, 7, 8, 9}
4.3 特点
① 集合中的元素不能重复,若重复会直接去重
② 集合的元素是无序的
③ 是一个可变序列
4.4 判断操作:in / not in
# 判断操作
s = {10, 20, 30, 40, 50}
print(10 in s) # ==>True
print(100 not in s) # ==>True
print(100 in s) # ==>False
4.5 新增操作
① add():一次添加一个元素
② update():至少添加一个元素
# 新增
s = {10, 20, 30, 40, 50}
s.add(233) # 一次添加一个元素
print(s) # ==>{40, 233, 10, 50, 20, 30}
s.update({99, 88, 77}) # 一次至少添加一个元素
print(s) # ==>{99, 40, 233, 10, 77, 50, 20, 88, 30}
# 这个过程只是叭里面对应的元素加到集合中,而不是叭列表这个对象添加到集合
s.update([100, 101, 102])
print(s) # ==>{99, 100, 101, 102, 40, 233, 10, 77, 50, 20, 88, 30}
s.update((222, 333, 444))
print(s) # ==>{99, 100, 101, 102, 40, 233, 10, 77, 333, 50, 20, 88, 444, 222, 30}
4.6 删除操作
① remove():一次删除一个元素,如果元素不存在则抛出KeyError
② discard():一次删除一个指定元素,如果元素不存在不抛出异常
③ pop():一次至删除一个元素,不能指定参数
④ clear():清空集合
# 删除练习
s = {10, 20, 30, 40, 50}
s.remove(10)
print(s) # ==>{40, 50, 20, 30}
# s.remove(500)
print(s) # 抛出异常:KeyError s.discard(500) # 不会抛出异常
print(s) # ==> {40, 50, 20, 30} s.pop() # 不能指定参数,使用后删除任意一个元素
print(s) s.clear()
print(s) # ==>set()
4.7 集合间的关系
① 判断是否相等:== / !=
② 判断是否是子集:issubset()
③ 判断是否是超集:issuperset()
④ 判断是否没有交集:isdisjoint()
# 集合关系练习
s1 = {10, 20, 30, 40}
s2 = {30, 40, 20, 10}
# 判断集合是否相等:元素相同就相等
print(s1 == s2) # ==>True
print(s1 != s2) # ==>False s1 = {10, 20, 30, 40, 50, 60}
s2 = {10, 20, 30, 40}
s3 = {10, 20, 90}
# 判断是否是子集
print(s2.issubset(s1)) # ==>True
print(s3.issubset(s1)) # ==>False
# 判断是否是超集
print(s1.issuperset(s2)) # ==>True
print(s1.issuperset(s3)) # ==>False
# 判断是否是没有有交集: 没有交集返回True,有交集返回False
print(s1.isdisjoint(s2)) # ==>False
print(s2.isdisjoint(s1)) # ==>False
print(s1.isdisjoint(s3)) # ==>False
print(s2.isdisjoint(s3)) # ==>False
s4 = {100, 200, 300}
print(s4.isdisjoint(s3)) # ==>True
4.8 集合间的数学计算
① 交集:intersection()
② 并集:union()会自己去重操作
③ 差集:difference()
④ 对称差集:symmetric_difference()
# 数学计算
# 交集
s1 = {10, 20, 30, 40}
s2 = {20, 30, 40, 50, 60}
print(s1.intersection(s2)) # ==>{40, 20, 30}
print(s1 & s2) # ==>{40, 20, 30}
# 并集
print(s1.union(s2)) # ==>{40, 10, 50, 20, 60, 30}
print(s1 | s2) # ==>{40, 10, 50, 20, 60, 30}
# 差集:先计算交集,在从当中去除交集元素
print(s1.difference(s2)) # ==>{10}
print(s1 - s2) # ==>{10}
# 对称差集:先计算交集,然后两个集合同时去除交集后的数据的集合
print(s1.symmetric_difference(s2)) # ==>{50, 10, 60}
print(s1 ^ s2) # ==>{50, 10, 60}
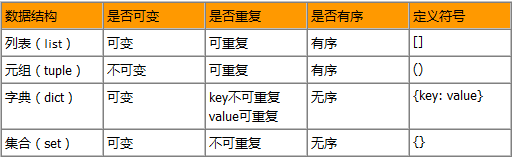
5、列表、字典、元组、集合总结
最新文章
- postgresql 导出数据字典文档
- python 列表生成式
- java static静态方法的并发性
- mysql 查看是否存在某一张表
- UVALive - 6952 Cent Savings dp
- 【Cocos2d-X开发学习笔记】第21期:动画类(CCAnimate)的使用
- 百度:在O(1)空间复杂度范围内对一个数组中前后连段有序数组进行归并排序
- js optimization and performance
- Sysstat LINUX工具包址
- [置顶] ./build_native 时出现please define NDK_ROOT
- 巡逻机器人(BFS)
- Spark1.0.0 属性配置
- 令人无限遐想的各种PCIe加速板卡
- 关于VXLAN的认识-----基础知识
- day67 ORM模型之高阶用法整理,聚合,分组查询以及F和Q用法,附练习题整理
- D - GCD HDU - 1695 -模板-莫比乌斯容斥
- 20145236《网络对抗》Exp7 网络欺诈技术防范
- 【转】mysql8.0 在window环境下的部署与配置
- python 计时器
- ReentrantLock synchronized