Yarn 集群环境 HA 搭建
2024-08-27 20:29:12
环境准备
确保主机搭建 HDFS HA 运行环境
步骤一:修改 mapred-site.xml 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 hadoop]# vim mapred-site.xml
<configuration>
<!-- 配置MapReduce程序运行模式 为 yarn(不配置默认为 local 模式) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置 hadoop 路径 -->
<property>
<name>mapreduce.application.classpath</name>
<value>/root/apps/hadoop-3.2.1/etc/hadoop:/root/apps/hadoop-3.2.1/share/hadoop/common/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/common/*:/root/apps/hadoop-3.2.1/share/hadoop/hdfs:/root/apps/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/hdfs/*:/root/apps/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/mapreduce/*:/root/apps/hadoop-3.2.1/share/hadoop/yarn:/root/apps/hadoop-3.2.1/share/hadoop/yarn/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/yarn/*</value>
</property>
</configuration>
步骤二:修改yarn-env.sh 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
[root@node-01 hadoop]# echo 'export JAVA_HOME=${JAVA_HOME}' >> yarn-env.sh
步骤三:修改 yarn-site.xml 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 hadoop]# vim yarn-site.xml
<configuration>
<!-- 配置 NodeManager上运行的附属服务(指定 MapReduce 中 reduce 读取数据方式) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置 yarn 集群标识 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<!-- 启用 yarn HA(高可用) -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 配置 resourcemanager 逻辑 ids 名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置 resourcemanager1 启动主机名-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node-01</value>
</property>
<!-- 配置 resourcemanager2 启动主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node-02</value>
</property>
<!-- 配置 resourcemanager1 web 浏览器地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node-01:8088</value>
</property>
<!-- 配置 resourcemanager2 web 浏览器地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node-02:8088</value>
</property>
<!--配置 zk 集群地址-->
<property>
<name>hadoop.zk.address</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
<!-- 启用 resourcemanager 重启自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 有三种StateStore,分别是基于 zookeeper, HDFS, leveldb, HA 高可用集群必须用 ZKRMStateStore -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置自动检测硬件(默认关闭) -->
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
<!-- 配置 nodemanager 启动要求的最低配置-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
步骤四:scp 这个 yarn-site.xml 到其他节点
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 ~]# scp mapred-site.xml node-02:$PWD
[root@node-01 ~]# scp mapred-site.xml node-03:$PWD
[root@node-01 ~]# scp yarn-env.sh node-02:$PWD
[root@node-01 ~]# scp yarn-env.sh node-03:$PWD
[root@node-01 ~]# scp yarn-site.xml node-02:$PWD
[root@node-01 ~]# scp yarn-site.xml node-03:$PWD
步骤五:启动 yarn 集群
[root@node-01 ~]# start-yarn.sh
stop-yarn.sh :停止 yarn 集群
步骤六:用 jps 检查 yarn 的进程
[root@node-01 ~]# jps
16800 ResourceManager
12050 NameNode
11878 JournalNode
12362 DFSZKFailoverController
11739 QuorumPeerMain
16941 NodeManager
12174 DataNode
[root@node-02 ~]# jps
11616 JournalNode
13492 ResourceManager
11926 DataNode
11803 NameNode
11452 QuorumPeerMain
12046 DFSZKFailoverController
# 手动启动 node-02 和 node-03 nodemanger 进程
[root@node-02 ~]# yarn --daemon start nodemanager
[root@node-03 ~]# yarn --daemon start nodemanager
yarn --daemon stop nodemanager 停止nodemanger进程
步骤七:用 web 浏览器查看 yarn 的网页
node-01:http://192.168.229.21:8088/cluster/cluster
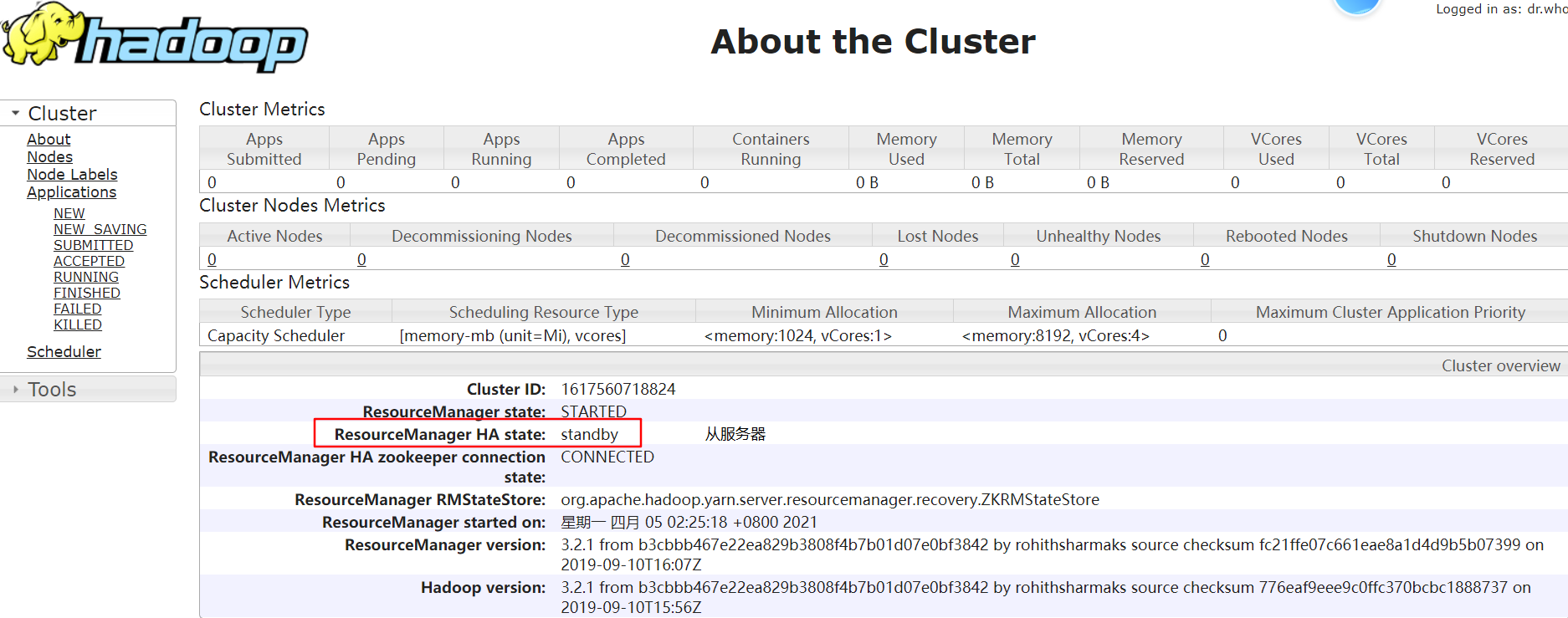
node-02:http://192.168.229.22:8088/cluster/cluster
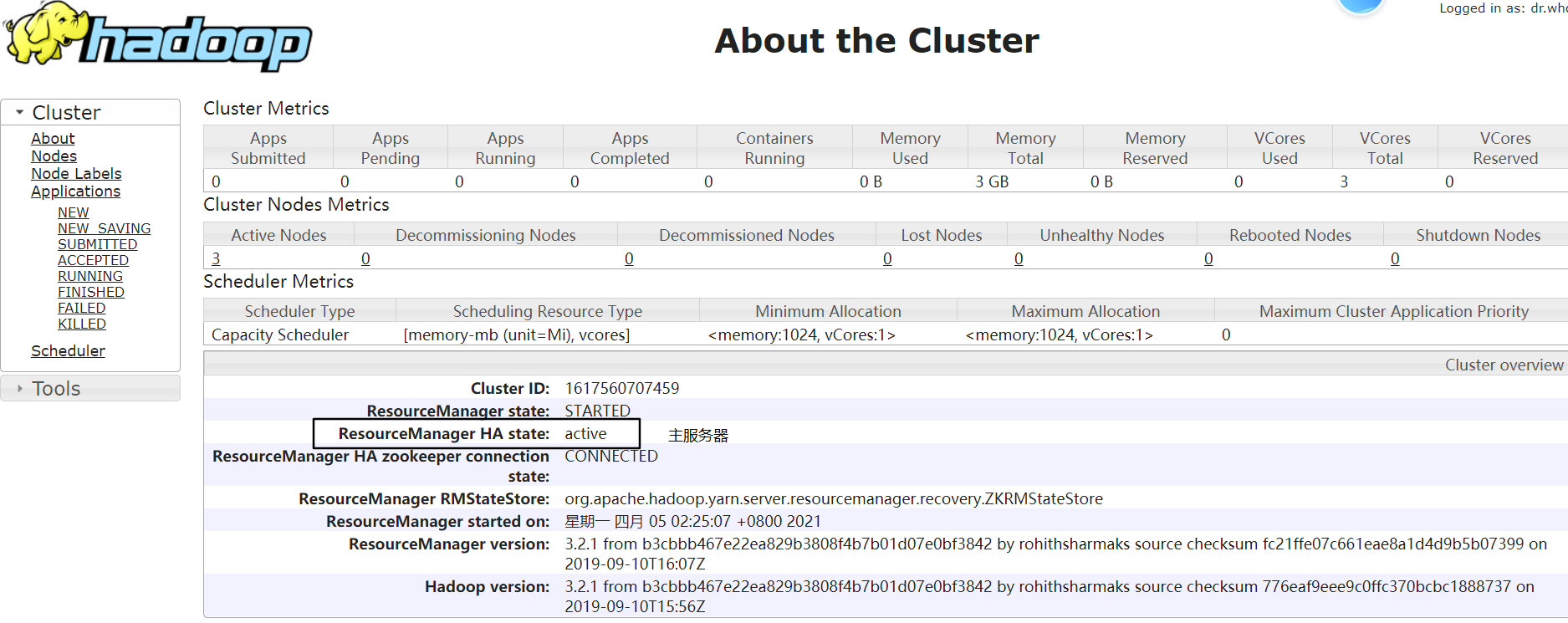
步骤八:测试 ResourceManager 故障转移
# node-02 上关闭 resourcemanager 进程
[root@node-02 logs]# yarn --daemon stop resourcemanager
查看 node-01:http://192.168.229.21:8088/cluster/cluster,发现状态由 standby 变为 active,说明已经进行故障转移
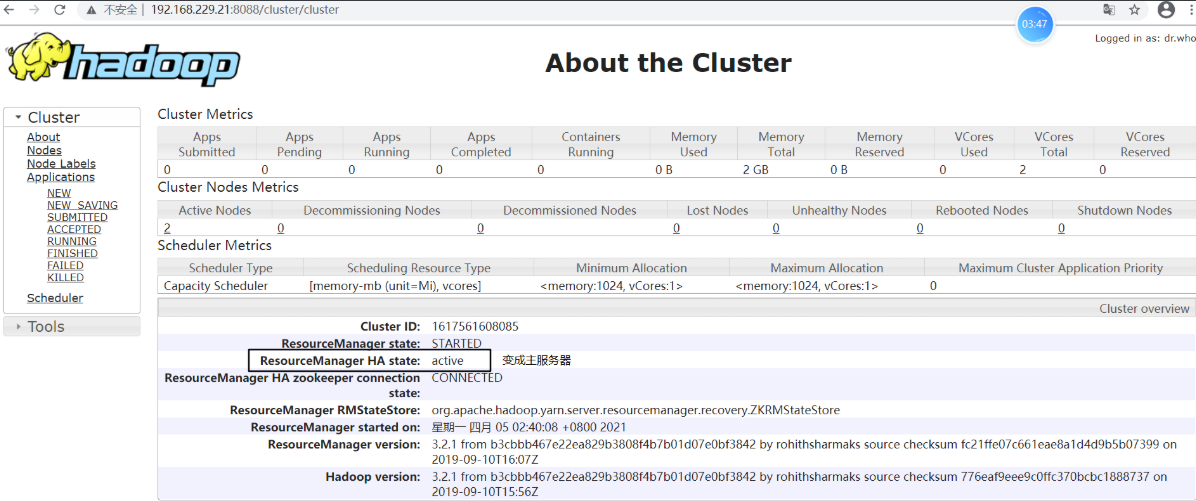
将 node-02 上 resourcemanager 进程再次启动
[root@node-02 logs]# yarn --daemon start resourcemanager
这时,node-02 上的 resourcemanager 则变为 standby 状态,故障转移测试完成:)
步骤九:测试 Yarn 集群运行 wordcount 程序
将 wordcount 程序进行 Jar 打包并上传,执行 wordcount 程序
执行 MapReduce 程序命令格式:hadoop jar xxxx.jar 类全名(main 方法的类名和包名)
[root@node-01 ~]# ll
总用量 138368
drwxr-xr-x. 5 root root 69 4月 4 23:36 apps
-rw-r--r--. 1 root root 6870038 4月 8 13:12 MapReduceDemo-1.0-SNAPSHOT.jar
[root@node-01 hadoop]# hadoop jar MapReduceDemo-1.0-SNAPSHOT.jar wordcount.JobSubmitterLinuxToYarn
2021-04-08 20:00:17,739 INFO mapreduce.Job: Job job_1617883180833_0001 completed successfully #表示 Job 执行成功
最新文章
- web安全之sql注入的防御
- 局域网聊天Chat(马士兵视频改进版)
- 【转】ie8 不支持 position:fixed 的简单解决办法
- POJ 1568 Find the Winning Move(极大极小搜索)
- poj2017简单题
- Swift - 设置网格UICollectionView的单元格间距
- Middleware详解
- 前端学习笔记(zepto或jquery)——对li标签的相关操作(一)
- 基于Quartz.NET框架的WinForm任务计划管理工具
- css中的position
- SSM-Spring-19:Spring中JdbcTemplate
- 🧬 C# 神经网络计算库和问题求解
- JAVA程序错误总结
- MySQL数据库和表名大小写敏感开关的打开办法
- django.core.exceptions.AppRegistryNotReady: Apps aren't loaded yet.
- BZOJ5131: [CodePlus2017年12月]可做题2
- 安装 启动sshd服务:
- lintcode-464-整数排序 II
- Storm框架入门
- stp 零部件 转为 装配图