python15正则表达式
2024-09-03 10:12:07
------------恢复内容开始------------

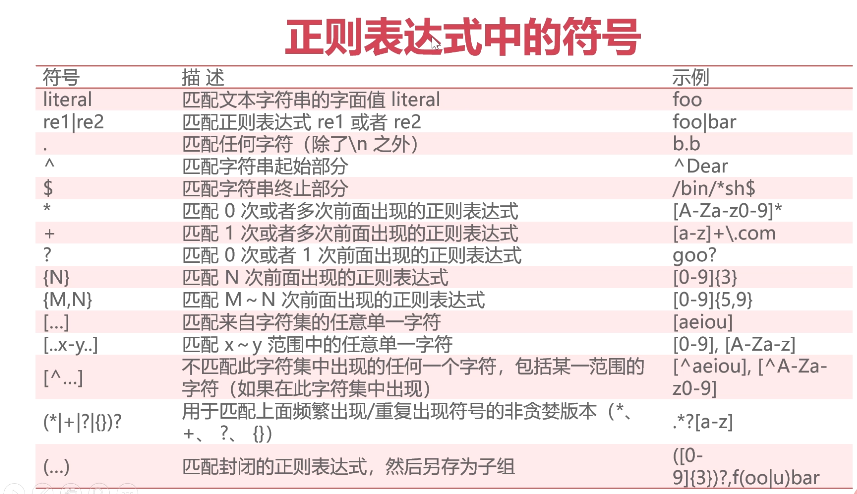


















python实现实现实现实现


import re #将表达式编译,返回一个对象,
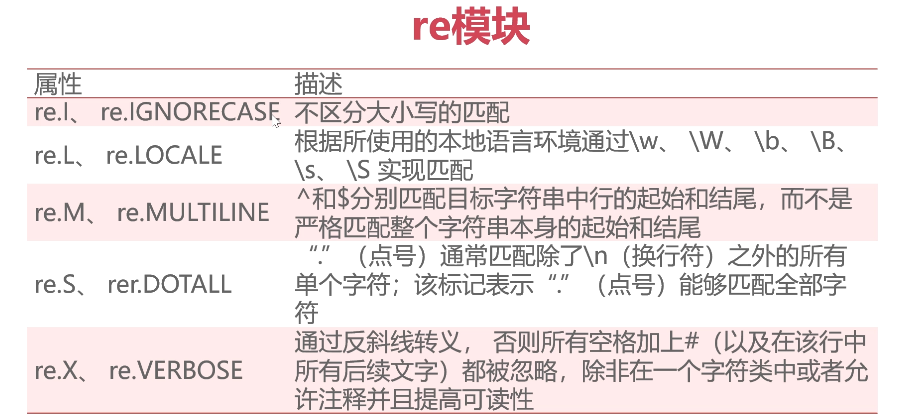
pattern = re.compile(r"hello",re.I)#re.I忽略大小写 print(dir(pattern))
#使用对象的方法,通过match匹配
rest = pattern.match("hellossss")
print(rest)
rest1 = pattern.match("Hellossss")
print(rest1)
print(dir(rest1)) 结果:
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'findall', 'finditer', 'flags', 'fullmatch', 'groupindex', 'groups', 'match', 'pattern',
'scanner', 'search', 'split', 'sub', 'subn']
<re.Match object; span=(0, 5), match='hello'>
<re.Match object; span=(0, 5), match='Hello'>
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__dir__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__',
'__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'end', 'endpos', 'expand', 'group', 'groupdict', 'groups', 'lastgroup', 'lastindex',
'pos', 're', 'regs', 'span', 'start', 'string']

浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中,未匹配成功返回空列表 一旦匹配成,再次匹配,是从前一次匹配成功的,后面一位开始的,也可以理解为匹配成功的字符串,不在参与下次匹配 无分组:匹配所有合规则的字符串,匹配到的字符串放到一个列表中 有分组:只将匹配到的字符串里,组的部分放到列表里返回,相当于groups()方法 多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返 相当于在group()结果里再将组的部分,分别,拿出来放入一个元组,最后将所有元组放入一个列表返回 分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回
import re #使用编译
coent = "Oone1twoT2three3"
p = re.compile(r"[a-z]+",re.I)#r表示其后的字符串按原样表示,不使用转义字符
rest = p.findall(coent) #一列表的额形式返回
print(rest) #不编译直接使用方法
print(re.findall(r"[a-z]+",coent,re.I))
结果:
['Oone', 'twoT', 'three']
['Oone', 'twoT', 'three']

import re
content = "quan zhiqiang"
p = re.compile(r"zhi")
rest = p.search(content)
print(rest) print("QQQQQQQQQQQQQQQQ")
rest1 = p.match(content)
print(rest1)
#因为match从第一个字符开始寻找,第一个字符不匹配直接不寻找了,
#search会继续下一个查找 print("不编译,不编译")
no_rest = re.search("zhi",content)
print(no_rest)
结果:
<re.Match object; span=(5, 8), match='zhi'>
QQQQQQQQQQQQQQQQ
None
不编译,不编译
<re.Match object; span=(5, 8), match='zhi'>

import re def test_g():
content = "quanzhiqiang"
p = re.compile(r"zhi")
rest = p.search(content)
print(rest)#注意,当匹配不到的时候,需要对if rest 进行判断,不然直接
if rest:
#使用group打印会出错
print(rest.group())
#如果前面使用分株,可以group(1)
print(rest.groups())#因为没有进行分组,所以为空的元组 def test_id():
p = re.compile(r"(\d{6})(\d{4})((\d{2})(\d{2}))\d{2}\d{1}([0-9]|X)")
id1 = "440882199904142235"
id2 = "44088219990214228X"
rest1 = p.search(id2)
print(rest1.group(1))
print(rest1.groups())#放回说有的组
print("#######################")
print(rest1.groupdict()) if __name__ == "__main__":
test_g()
test_id() 结果:
<re.Match object; span=(4, 7), match='zhi'>
zhi
()
440882
('440882', '1999', '0214', '02', '14', 'X')
#######################
{}
import re def test_g():
content = "quanzhiqiang"
p = re.compile(r"zhi")
rest = p.search(content)
print(rest)#注意,当匹配不到的时候,需要对if rest 进行判断,不然直接
if rest:
#使用group打印会出错
print(rest.group())
#如果前面使用分株,可以group(1)
print(rest.groups())#因为没有进行分组,所以为空的元组 def test_id():
#p = re.compile(r"(\d{6})(\d{4})((\d{2})(\d{2}))\d{2}\d{1}([0-9]|X)")
p = re.compile(r"(\d{6})(?P<year>\d{4})((?P<month>\d{2})(?P<day>\d{2}))\d{2}\d{1}([0-9]|X)")
id1 = "440882199904142235"
id2 = "44088219990214228X"
rest1 = p.search(id2)
print(rest1.group(1))
print(rest1.groups())#放回说有的组
print("#######################")
print(rest1.groupdict()) if __name__ == "__main__":
test_g()
test_id() 结果;
<re.Match object; span=(4, 7), match='zhi'>
zhi
()
440882
('440882', '1999', '0214', '02', '14', 'X')
#######################
{'year': '1999', 'month': '02', 'day': '14'}

import re s = "one1two2three333four"
p = re.compile(r"\d+")
rest = p.split(s)
print(rest) 结果:
['one', 'two', 'three', 'four']

import re s = "one1two2three333four"
p = re.compile(r"\d+")
rest = p.split(s,2)#只分割前两个
print(rest) 结果:
['one', 'two', 'three333four']
import re s = "one1two2three333four"
#s = "one@two@three@four" p = re.compile(r"\d+")
rest = p.sub("@",s)
print(rest) #原始的替换方法:
print("@@@@@@@@@@@@@@@@@@@@@@@@@@@")
rest1 = s.replace("1","@").replace("2","@").replace("333","@")
print(rest1) #更换位置
s2 = "hello world"
p2 = re.compile(r"(\w+) (\w+)")
rest3 = p2.sub(r"\2 \1",s2)
print(rest3) #使用函数进行替换更换并大写:
def f(m):
return m.group(2).upper() + " " + m.group(1)
print("HHHHHHHHHHHHHHHHHHHHHHH")
rest4 = p2.sub(f,s2)
print(rest4) #使用匿名函数替换
print("QQQQQQQQQQQQQQQQQQQQQQ")
rest6 = p2.sub(lambda m :m.group(2).upper() + " " + m.group(1),s2)
print(rest6) 结果:
one@two@three@four
@@@@@@@@@@@@@@@@@@@@@@@@@@@
one@two@three@four
world hello
HHHHHHHHHHHHHHHHHHHHHHH
WORLD hello
QQQQQQQQQQQQQQQQQQQQQQ
WORLD hello
------------恢复内容结束------------
最新文章
- Atitit.加密算法ati Aes的框架设计
- 利用web工具splinter模拟登陆做自动签到
- iOS-数据解析XML解析的多种平台介绍
- css3实现动画效果
- 无责任Windows Azure SDK .NET开发入门篇二[使用Azure AD 进行身份验证-2.2身份验证开发]
- jenkins 设置 gitlab web hooks
- Codeforces Round #424 (Div. 2, rated, based on VK Cup Finals)
- slowhttptest慢攻击工具介绍
- Spring AOP (二)
- oracle数据库-错误编码大全
- Spark设计理念与基本架构
- 记一次挂马清除经历:处理一个利用thinkphp5远程代码执行漏洞挖矿的木马
- swift -2018 - 创建PCH文件
- 20155334 《网络攻防》Exp4 恶意代码分析
- [LOJ#6039].「雅礼集训 2017 Day5」珠宝[决策单调性]
- 如何在主Form出现之前,弹出密码验证From,Cancel就退出程序,Ok后密码正确才出现主Form
- ACCESS_REFUSED - Login was refused using authentication mechanism PLAIN
- LinuxMint下的Orionode源码安装
- python 读不同编码的文本,传递一个可选的encoding 参数给open() 函数
- 【php】new static的用法