Python elasticsearch 报错及解决方法
2024-10-21 11:30:22
1. ERROR: [1] bootstrap checks failed [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, # discovery.seed_providers, cluster.initial_master_nodes] must be configured
- 意思应该是:需要设置能够被选择为主节点的节点
- 在config/elasticsearch.yml中加入: cluster.initial_master_nodes: ["node-1"]
2. ES 分片失败:UNASSIGNED reason为node_left
- 背景: ES集群中一个节点突然因为运行内存占用大的程序而卡死,导致节点突然脱离集群,在elasticsearch-head中点击灰色分片显示node_lefe
- 原因: NODE_LEFT :由于承载该分片的节点离开集群导致未分配。
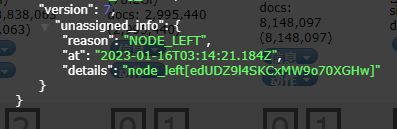
参考文章: https://www.cnblogs.com/whl-jx911/p/14482749.html - 解决办法:创建索引时设置副本数量至少为1,这样即使有一个节点断开,集群也能通过放在其他节点上的副本对分片进行恢复
3.document(s) failed to index... elasticsearch index missing
- 背景:使用elasticsearch的helpers.bulk方法对数据进行批量写入时,出现运行到bulk位置报:缺失对应的索引数据错误
- 原因:
- bulk需要将格式为data = {"_index": "index_name", "_type": "type", "_source": dict}的字典放入一个数组里再批量写入
- 而个人在action数组拼接时错误将action.append(data)写成了action.append(line),也就是拼接错了字典,导致数据对不上
4.Document contains at least one immense term in field="" (whose UTF8 encoding is longer than the max length 32766)
- 翻译过来就是:有一个数据中的某个字段的值太长了,超过了规定的32766限制,field=""会显示是哪个字段的数据过长
- 解决:缩短某个字段的数据长度,或者干脆舍弃掉这部分数据,例如正常为几千的长度突然出现几十万的长度,很可能是乱码的数据
最新文章
- JMS学习之路(一):整合activeMQ到SpringMVC
- mysql乐观锁总结和实践
- iOS 常用设计模式和机制之 KVC
- poj 1625 (AC自动机好模版,大数好模版)
- Qt 文件处理(readLine可以读取char[],并且有qSetFieldWidth qSetPadChar 等全局函数)
- Android开发技巧——去掉TextView中autolink的下划线
- python中的二维数组90度旋转
- Omi实战-QQ附近用户列表Web页
- yii2之数据验证
- JAVAscript学习笔记 js事件 第一节 (原创) 参考js使用表
- 产品研发不等待 i.MX6Q全新推出增强版本 官方店铺下单双重优惠
- lambda从入门到精通
- Java 常见面试题(一)
- 转:百度MySql5.7安装配置
- Oracle数据库--PL/SQL存储过程和函数的建立和调用
- Linux进程ID号--Linux进程的管理与调度(三)
- 【分享】Linux(Ubuntu)下如何自己编译JDK
- js中的deom ready执行的问题
- 【51nod】1559 车和矩形
- 杂谈微服务架构下SSO&OpenAPI访问的方案。