Python数据科学手册-机器学习: 决策树与随机森林
2024-08-27 12:31:03
无参数 算法 随机森林
随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果。
导入标准程序库
随机森林的诱因: 决策树
随机森林是建立在决策树 基础上 的集成学习器
建一颗决策树
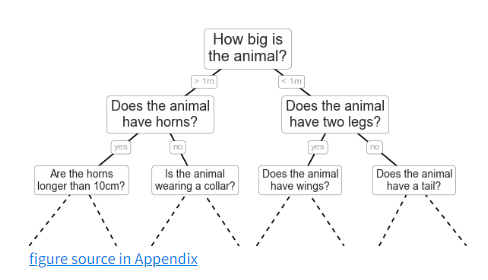
二叉决策树
在一颗合理的决策书中。每个问题基本上都可将种类的可能性减半。
决策树的难点在于如何设计每一步的问题。
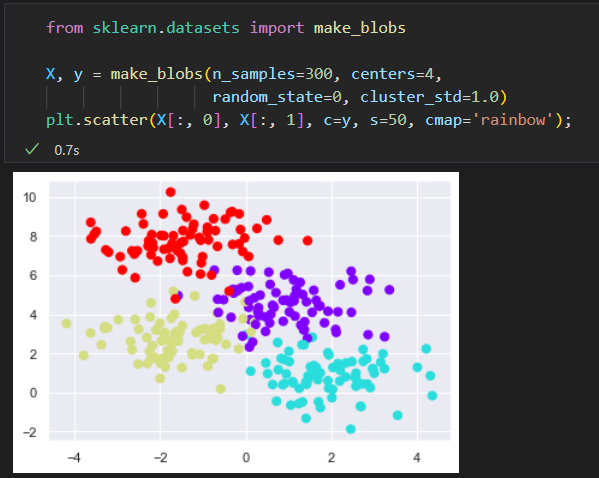
- 创建一颗决策树
原始数据: 四种标签
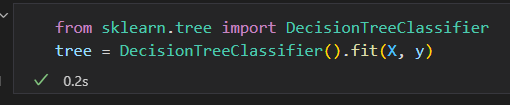
使用DecisionTreeClassifier评估器
辅助函数,分类器结果可视化
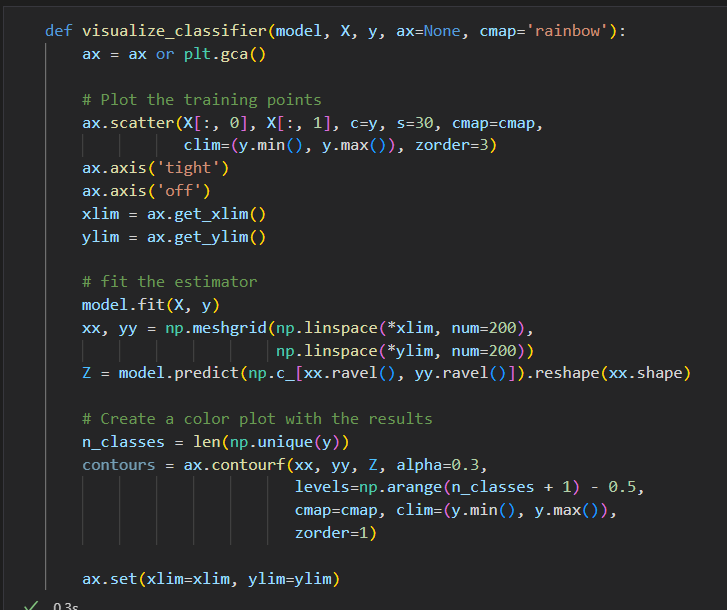
检查决策树分类的结果
在深度为5的时候,在黄色与蓝色区域中间有一个浅紫色区域,这显然不是根据数据本身的分布情况生成的正确分类结果,
而更像是一个特殊的数据样本或数据噪音 形成的干扰结果。 也就是数据出现了 过拟合
- 决策树和过拟合
训练俩颗不同的决策树,每颗树拟合一半数据。
在一些区域,俩颗树产生了一致的结果,将俩颗树的结果组合起来。会获得更好的结果
评估器集成算法: 随机森林
通过组合多个过拟合评估器来降低过拟合 成都的想法其实是一种集成学习方法,称为装袋算法。
每个评估器都对数据过拟合,通过求均值可以获得更好的分类结果。
随机决策树的集成算法 就是 随机森林
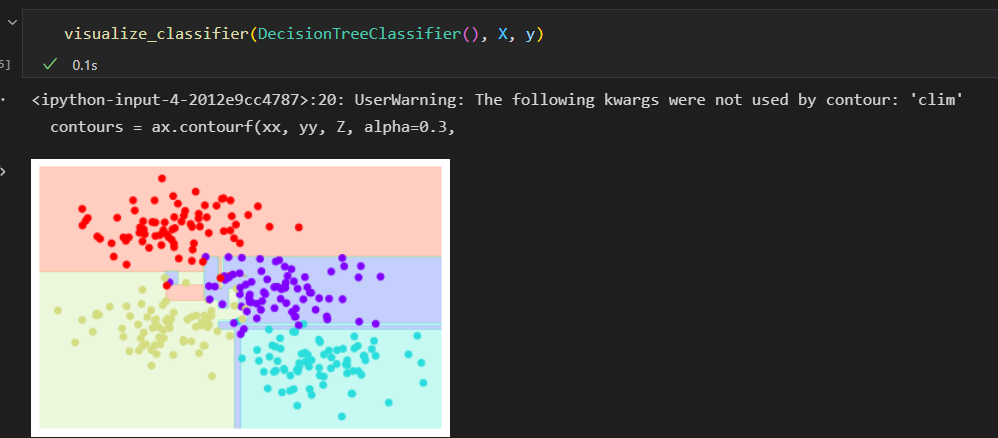
使用BaggingClassifier元评估器来实现这种装袋分类器
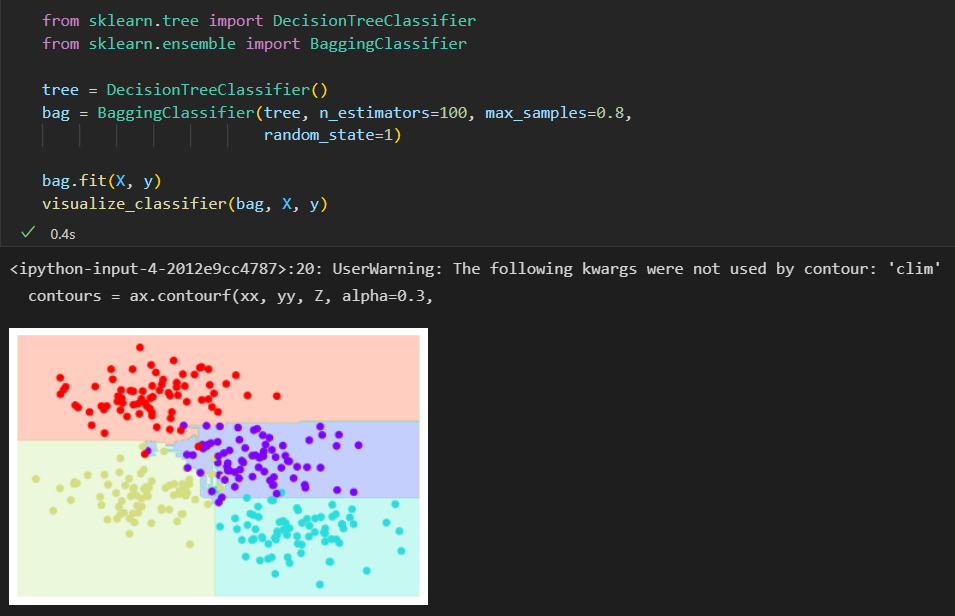
每个评估器拟合样本80%的随机数, 其实如果我们用随机方法确定数据的分割方式,决策树拟合的随机性会更有型。 这样可以让所有数据在每次训练时都被拟合,但拟合的结果 却仍然是随机的。
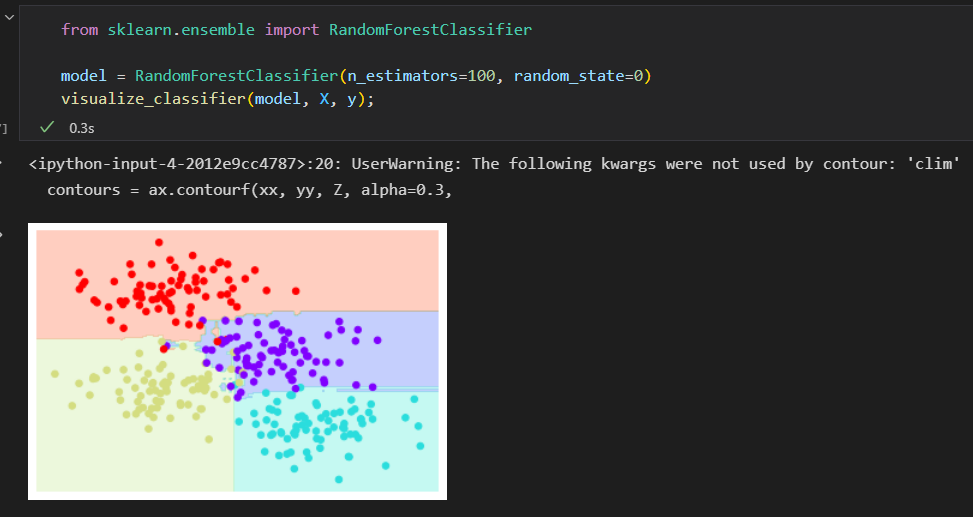
使用RandomForestClassifier评估器,会自动进行随机化决策。
随机森林回归
随机森林可以用作回归,处理连续变量,不是离散变量。
评估器是 RandomForestRegressor .
原始数据:快慢震荡组合
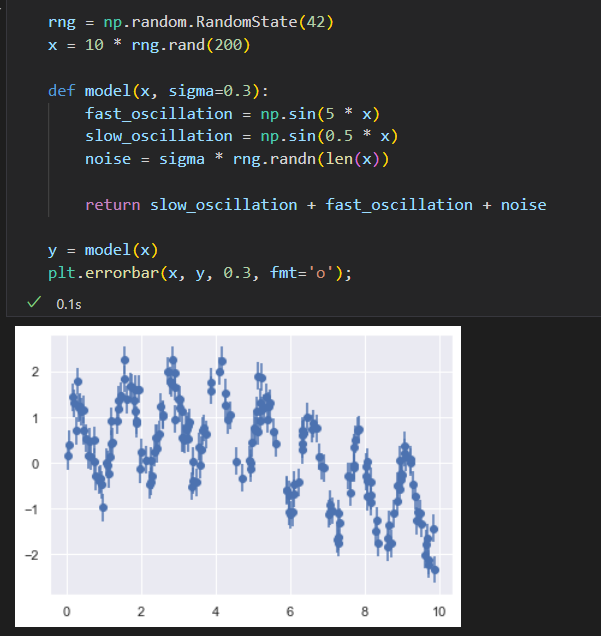
使用随机森林回归器,可以获得下面的最佳拟合曲线
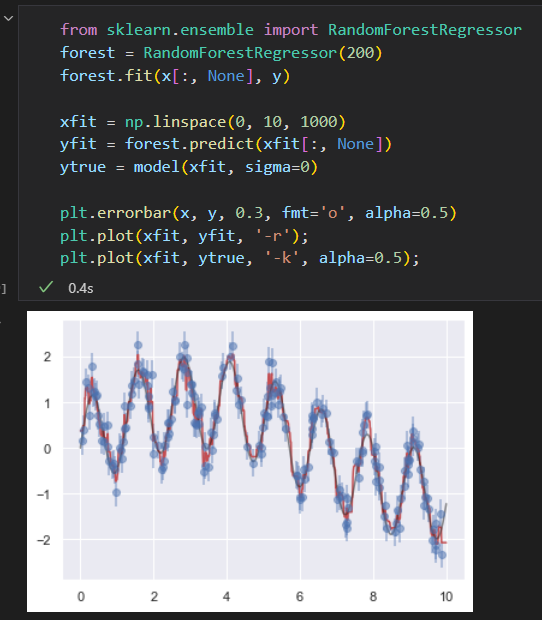
真实模型是平滑曲线。随机森林模型是锯齿线,
案例:用随机森林识别手写数字

用随机森林快速对数字进行分类
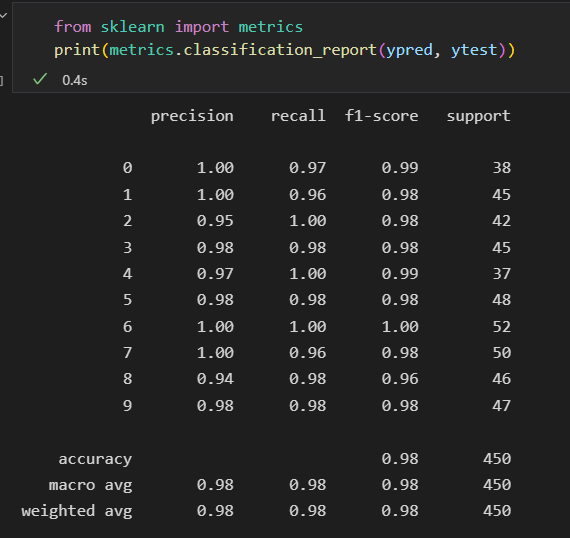
查看分类报告
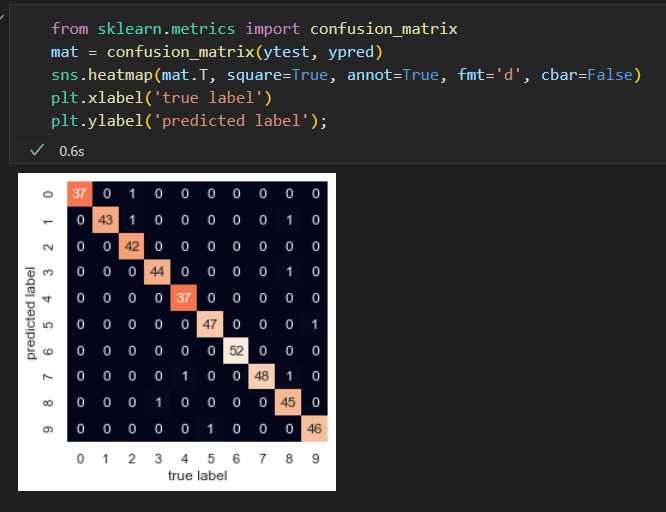
混淆矩阵
最新文章
- Java中文编码小结
- 深入 理解vxlan
- Flex的正则表达式匹配速度与手工代码的比较
- Codeforces Gym 100513G G. FacePalm Accounting
- Spring学习笔记之bean配置
- xp 安装 win7 64
- mysql多表字段名重复的情况
- ES6 let和const命令(3)
- redis基础知识
- haproxy下X-Frame-Options修复方法
- 新手学习之浅析一下c/c++中的指针
- laravel-阿里大于
- 自定义扩展实现相对于addRoutes的removeRoutes方法——vue-router
- PHP 抽象类、接口,traint详解
- 04-模拟String去除空格trim()方法
- Apache Commons Beanutils 一 (使用PropertyUtils访问Bean属性)
- Odoo小数精度及货币精度详解
- hdu5173 How Many Maos Does the Guanxi Worth
- VS2015和SVN合作
- 下载百度网盘破解 获得 所下载视频URL 粘贴到thunder