【C# 集合】HashTable .net core 中的Hashtable的实现原理
上一篇我介绍了Hash函数
这篇我来说一下Hash函数在 HashTable中的应用。
HashTable的特性:
1、装载因子:.net core 0.72 ,java 0.75
2、冲突解决方案:Hashtable使用了闭散列法来解决冲突,java采用 开散列法解决冲突.
3、bucket(桶):用来转载hash函数的返回值和建立key和hash返回值的关系
4、Hash函数以及算法
5、HashTable是可以序列化的。是线程安全的。HashTable之所以是线程安全的,是因为方法上都加了synchronized关键字。
6、可枚举
7、在新的开发中不建议使用HashTable,建议使用Dictionary<Tkey,Tvalue>和ConcurrencyDictionary<Tkey,Tvalue>
.net core 中的Hashtable的实现原理
它通过一个结构体bucket来表示哈希表中的单个元素,这个结构体中有三个成员:
private struct Bucket
{
public object? key;
public object? val;
public int hash_coll; // bucket结构体的hash_coll字段所存储的是h(key, i)的值而不是哈希地址
}
(1) key :表示键,即哈希表中的关键字。
(2) val :表示值,即跟关键字所对应值。
(3) hash_coll :它是一个int类型,用于表示键所对应的哈希码,.net core bucket结构体的hash_coll字段所存储的是h(key, i)的值而不是哈希地址 。
int类型占据32个位的存储空间,它的最高位是符号位,为“0”时,表示这是一个正整数;为“1”时表示负整数。hash_coll使用最高位表示当前位置是否发生冲突,为“0”时,也就是为正数时,表示未发生冲突;为“1”时,表示当前位置存在冲突。之所以专门使用一个位用于存放哈希码并标注是否发生冲突,主要是为了提高哈希表的运行效率。关于这一点,稍后会提到。
Hashtable解决冲突使用了双重散列法,但又跟前面所讲的双重散列法稍有不同。它探测地址的方法如下:
h(key, i) = h1(key) + i * h2(key)
其中哈希函数h1和h2的公式如下:
h1(key) = key.GetHashCode()
h2(key) = 1 + (((h1(key) >> 5) + 1) % (hashsize - 1))
由于使用了二度哈希,最终的h(key, i)的值有可能会大于hashsize,所以需要对h(key, i)进行模运算,最终计算的哈希地址为:
哈希地址 = h(key, i) % hashsize
【注意】:bucket结构体的hash_coll字段所存储的是h(key, i)的值而不是哈希地址。
哈希表的所有元素存放于一个名称为buckets(又称为数据桶) 的bucket数组之中,下面演示一个哈希表的数据的插入和删除过程,其中数据元素使用(键,值,哈希码)来表示。注意,本例假设Hashtable的长度为11,即hashsize = 11,这里只显示其中的前5个元素。
(1)插入元素(k1,v1,1)和(k2,v2,2)。
由于插入的两个元素不存在冲突,所以直接使用h1(key) % hashsize的值做为其哈希码而忽略了h2(key)。其效果如图8.6所示。

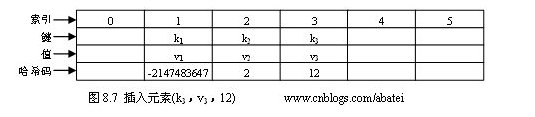
(2) 插入元素(k3,v3,12)
新插入的元素的哈希码为12,由于哈希表长为11,12 % 11 = 1,所以新元素应该插入到索引1处,但由于索引1处已经被k1占据,所以需要使用h2(key)重新计算哈希码。
h2(key) = 1 + (((h1(key) >> 5) + 1) % (hashsize - 1))
h2(key) = 1 + ((12 >> 5) + 1) % (11 - 1)) = 2
新的哈希地址为 h1(key) + i * h2(key) = 1 + 1 * 2 = 3,所以k3插入到索引3处。而由于索引1处存在冲突,所以需要置其最高位为“1”。
(10000000000000000000000000000001)2 = (-2147483647)10
最终效果如图8.7所示。
(3) 插入元素(k4,v4,14)
k4的哈希码为14,14 % 11 = 3,而索引3处已被k3占据,所以使用二度哈希重新计算地址,得到新地址为14。索引3处存在冲突,所以需要置高位为“1”。
(12)10 = (00000000000000000000000000001100)2 高位置“1”后
(10000000000000000000000000001100)2 = (-2147483636)10
最终效果如图8.8所示。

(4) 删除元素k1和k2
Hashtable在删除一个存在冲突的元素时(hash_coll为负数),会把这个元素的key指向数组buckets,同时将该元素的hash_coll的低31位全部置“0”而保留最高位,由于原hash_coll为负数,所以最高位为“1”。
(10000000000000000000000000000000)2 = (-2147483648)10
单凭判断hash_coll的值是否为-2147483648无法判断某个索引处是否为空,因为当索引0处存在冲突时,它的hash_coll的值同样也为-2147483648,这也是为什么要把key指向buckets的原因。这里把key指向buckets并且hash_coll值为-2147483648的空位称为“有冲突空位”。如图8.8所示,当k1被删除后,索引1处的空位就是有冲突空位。
Hashtable在删除一个不存在冲突的元素时(hash_coll为正数),会把键和值都设为null,hash_coll的值设为0。这种没有冲突的空位称为“无冲突空位”,如图8.9所示,k2被删除后索引2处就属于无冲突空位,当一个Hashtable被初始化后,buckets数组中的所有位置都是无冲突空位。

哈希表通过关键字查找元素时,首先计算出键的哈希地址,然后通过这个哈希地址直接访问数组的相应位置并对比两个键值,如果相同,则查找成功并返回;如果不同,则根据hash_coll的值来决定下一步操作。当hash_coll为0或正数时,表明没有冲突,此时查找失败;如果hash_coll为负数时,表明存在冲突,此时需通过二度哈希继续计算哈希地址进行查找,如此反复直到找到相应的键值表明查找成功,如果在查找过程中遇到hash_coll为正数或计算二度哈希的次数等于哈希表长度则查找失败。由此可知,将hash_coll的高位设为冲突位主要是为了提高查找速度,避免无意义地多次计算二度哈希的情况。
最新文章
- 【linux基础】第九周作业
- [转] 多线程 《深入浅出 Java Concurrency》目录
- 天大acm 题号1002 Maya Calendar
- JAVA 基础 重新开始
- CSS选择器的特殊性
- yiic 数据库迁移工具
- GlusterFS常用命令
- Eclipse中快捷键Ctrl + Alt + 向上箭头 或者 Ctrl + Alt + 向下箭头与Windows冲突
- Net core 关于缓存的实现
- myeclipse中的HTML页面在浏览器中显示为乱码
- python之路4-文件操作
- hadoop概念
- mvc 根据模板导出excel,直接导出文件流
- 《Linux及安全》课程实践二
- 数据库中,表一sum得出一个值,赋给表二的某个字段,为null
- hdoj:2029
- 20180322 对DataTable里面的数据进行去重
- [PHP]防止表单重复提交的几种方法
- springMVC学习(10)-上传图片
- /proc/sys目录下各文件参数说明