python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
2024-09-05 07:59:23
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架
跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为这一卷的案例,不用想有图,有字
第一步:
创建爬虫文件:

现在切换到scrapy_test的根目录下:

我们现在创建了爬虫文件,这个网页正常情况下就可以直接抓取,不像糗事啊,天猫啊需要到SETTING里去设置对抗ROBOT cookie user-AGENT这样的反爬手段
现在开始创建代码

现在在终端切换到爬虫文件的目录中
执行命令:
scrapy crawl crawler1 --nolog
--nolog是为了隐藏日志文件时我添加的命令语句,因为这个网页过于简单,所以为了方便数据的展示,我加了这句语句,但是如果抓取复杂的网站时我建议添加,一旦出问题可以立马发现问题的所在:
现在看下结果:
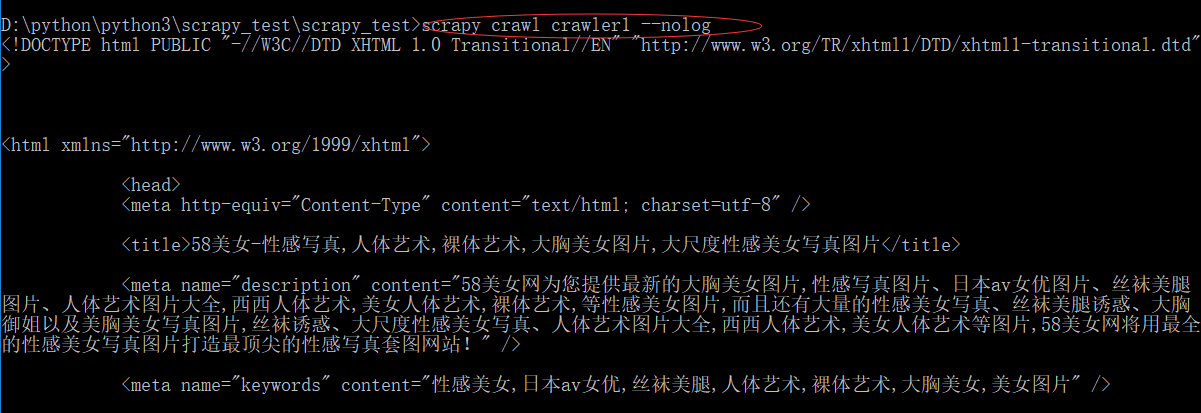
这样这个网页就爬了下来,但是数据内容不精准,我相信没有人会把别让人的所有网页代码拿来用,要用的是其中的数据,图片,视频,音频等内容
最新文章
- 2016huasacm暑假集训训练四 数论_A
- Js控制iFrame切换加载网址
- 第四课 Activity
- Notes of the scrum meeting(12.7)
- html-----004
- 生产者、消费者 C源码,gcc编译通过
- apache-maven-3.2.1设备
- Weka初步
- Zepto源码分析-event模块
- Head First设计模式之状态模式
- MySQL/MariaDB数据库忘掉密码解决办法--技术流ken
- Windows SFTP 的安装
- 采用ftpServer构建嵌入式ftp服务器时设置pass功能
- mybatis异常解决:class path resource [SqlMapConfig.xml] cannot be opened because it does not exist
- iOS UI布局-VFL语言
- 定时释放Linux/CentOS缓存
- [UE4]继承标准控件
- Run ASP.NET MVC site on mac (mono/xamarin studio)
- ftp协议及vsftpd的基本应用
- python列表推导式详解 列表推导式详解 字典推导式 详解 集合推导式详解 嵌套列表推导式详解