Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
概
暴力美学, 通过调参探索adversarial training的极限.
主要内容
实验设置
模型主要包括WRN-28-10, WRN-34-10, WRN-34-20, WRN-70-16;
优化器为SGD(nesterov momentum), 1/2, 3/4 epochs处 lr /= 10, weight decay 5e-4;
对抗训练用的是PGD-10, 步长为2/255\(\ell_{\infty}\)和15/255\(\ell_{2}\).
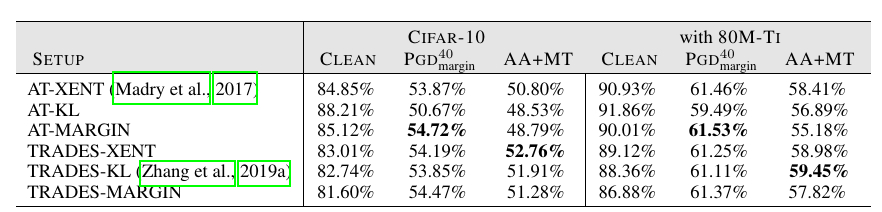
损失的影响
实际上就是比较不同方法的区别(包括外循环的损失和内循环构造对抗样本的损失, TRADES稍优):

额外的数据
有很多方法用了无标签数据作为额外的数据来进行训练并取得了很好的效果.
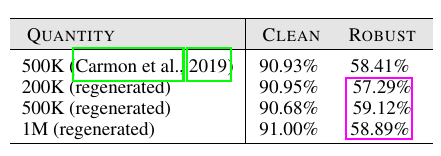
上表作者比较的是无标签数据的量, 显示过多的数据并不能一直增加鲁棒性.
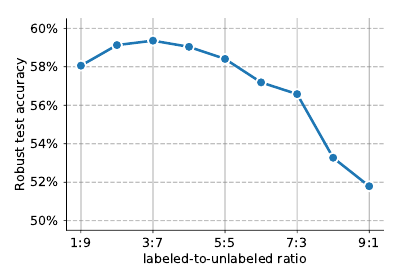
上图关注的是有标签数据和无标签数据之前的比例关系, 显然无标签数据似乎更能带来鲁棒性(这与无监督训练更具鲁棒性是一致的).
网络结构
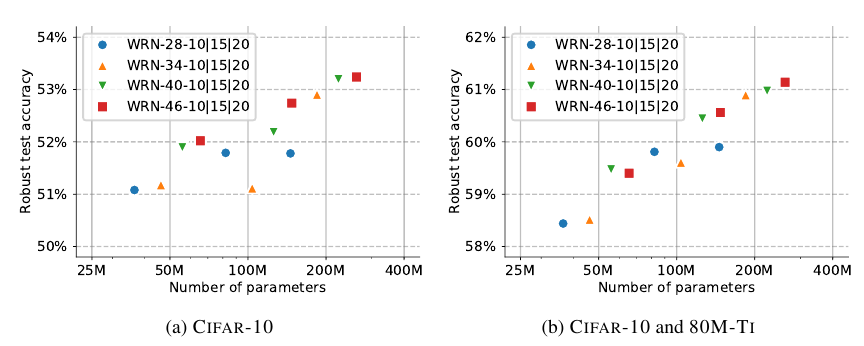
从上图可知, 网络越大鲁棒性越好.
其他的一些tricks
Model Weight Averaging: 作者发现这个对提高鲁棒性很有帮助, 且这方面缺乏研究
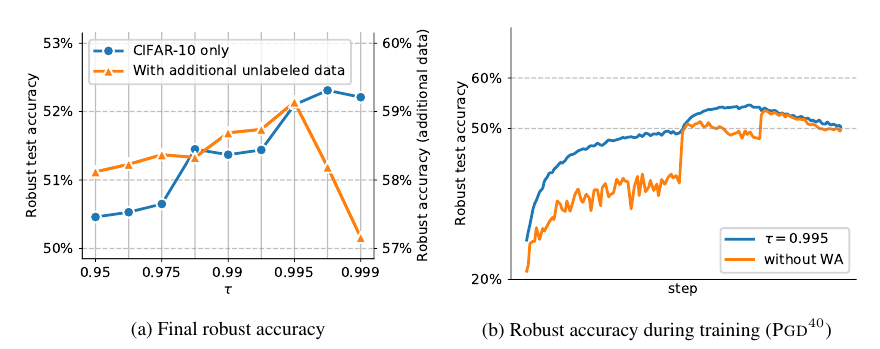
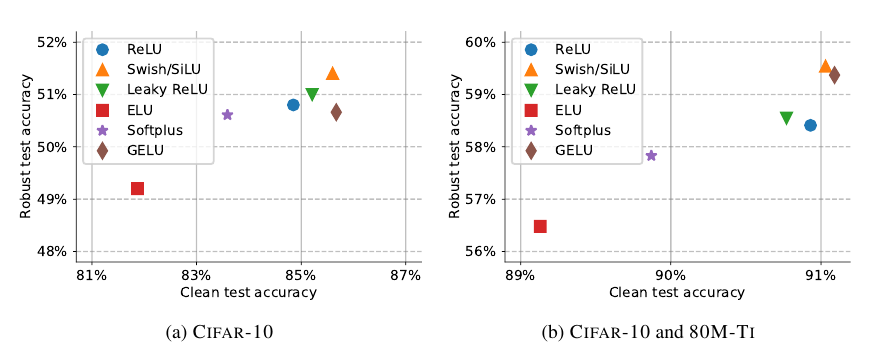
激活函数: Swish/SiLu表现不错, 整体相差不大.
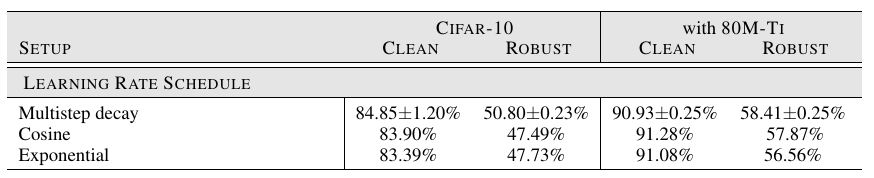
Learning Rate Schedule: 常用的multistep decay表现最好.
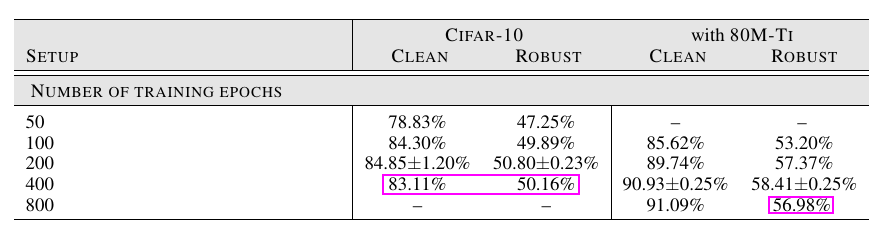
训练次数: 并非越大越好, 实际上已经有最新工作指出对抗训练存在严重的过拟合.
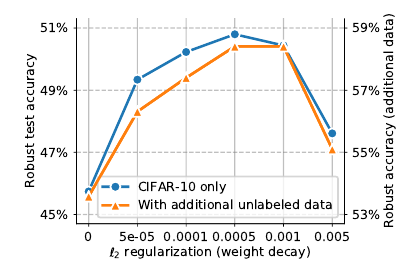
正则化(weight decay): \(\ell_2\)正则化, 即weight decay在对抗训练中有重要作用.
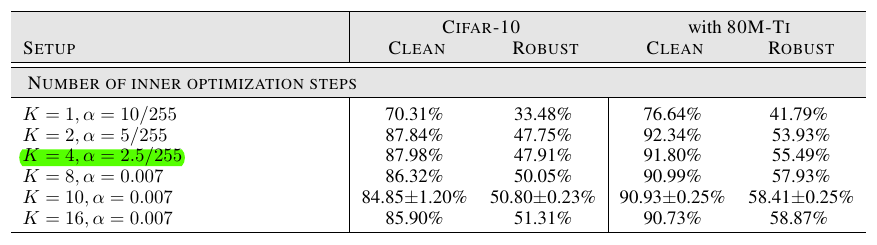
构造对抗样本所需的steps: 步数越多鲁棒性越好, 但是这是一个trade-off, 伴随着干净数据集的正确率下降
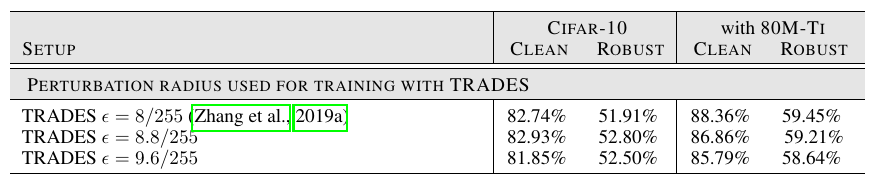
构造对抗样本的epsilon: 有类似上面的结论, 太大了二者都会下降.
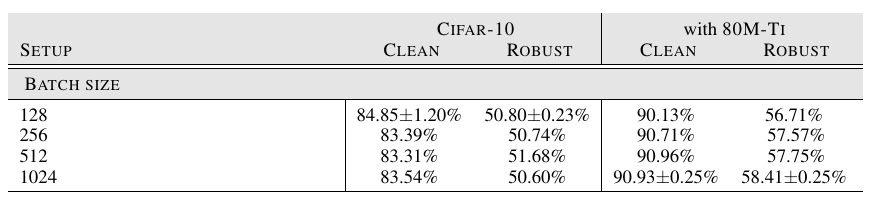
Batch Size: 同样并非越大越好.
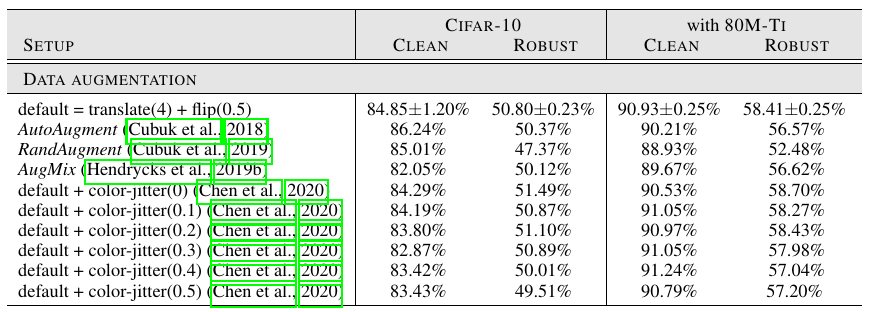
Augmentation: 似乎对于对抗训练意义不大, 但是个人在实验中发现这对防止过拟合有一定效果.
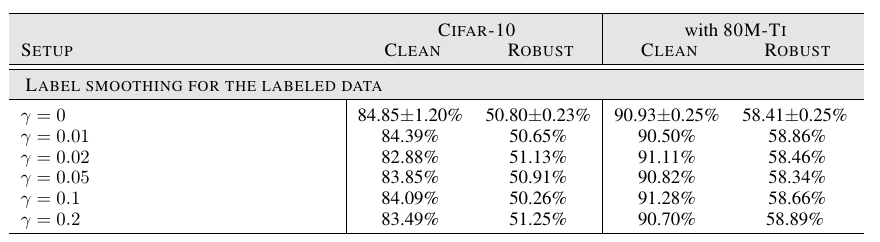
Label Smoothing: 几乎没影响
最新文章
- Toast显示图文界面——Android开发之路1
- php缓冲区详解
- D2js 的邦联式架构
- logistic回归
- jquery的checkbox 全选和全不选
- LSP遇到的问题
- python-面向对象(股票对象举例)
- BZOJ_1628_[Usaco2007_Demo]_City_skyline_(单调栈)
- [Angular 2] Filter items with a custom search Pipe in Angular 2
- 关于document.write()重写页面
- linux高级技巧:rsync同步(一个)
- api的安全问题
- 3361: [Usaco2004 Jan]培根距离
- 配置adb环境变量
- vue入门须知
- Ubuntu Mininet环境搭建
- Spring Boot实战笔记(五)-- Spring高级话题(Spring Aware)
- C# Dictionary 泛型
- iOS .tbd
- Centos7 安装 Redis
热门文章
- C++11的auto自动推导类型
- awk统计命令(求和、求平均、求最大值、求最小值)
- window安装ab压力测试
- SpringMvc分析
- 【划重点】Python遍历列表的四种方法
- 学Java,Java书籍的最佳阅读顺序
- Indirect函数(Excel函数集团)
- java 编程基础 Class对象 反射:动态代理 和AOP:java.lang.reflect.Proxy:(Proxy.newProxyInstance(newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h))
- 同步IO与一部IO、IO多路复用(番外篇)select、poll、epoll三者的区别;blocking和non-blocking的区别 synchronous IO和asynchronous IO的区别
- JAVA发送xml格式的接口请求