【python实现卷积神经网络】批量归一化层实现
2024-10-20 05:48:32
代码来源:https://github.com/eriklindernoren/ML-From-Scratch
卷积神经网络中卷积层Conv2D(带stride、padding)的具体实现:https://www.cnblogs.com/xiximayou/p/12706576.html
激活函数的实现(sigmoid、softmax、tanh、relu、leakyrelu、elu、selu、softplus):https://www.cnblogs.com/xiximayou/p/12713081.html
损失函数定义(均方误差、交叉熵损失):https://www.cnblogs.com/xiximayou/p/12713198.html
优化器的实现(SGD、Nesterov、Adagrad、Adadelta、RMSprop、Adam):https://www.cnblogs.com/xiximayou/p/12713594.html
卷积层反向传播过程:https://www.cnblogs.com/xiximayou/p/12713930.html
全连接层实现:https://www.cnblogs.com/xiximayou/p/12720017.html
class BatchNormalization(Layer):
"""Batch normalization.
"""
def __init__(self, momentum=0.99):
self.momentum = momentum
self.trainable = True
self.eps = 0.01
self.running_mean = None
self.running_var = None def initialize(self, optimizer):
# Initialize the parameters
self.gamma = np.ones(self.input_shape)
self.beta = np.zeros(self.input_shape)
# parameter optimizers
self.gamma_opt = copy.copy(optimizer)
self.beta_opt = copy.copy(optimizer) def parameters(self):
return np.prod(self.gamma.shape) + np.prod(self.beta.shape) def forward_pass(self, X, training=True): # Initialize running mean and variance if first run
if self.running_mean is None:
self.running_mean = np.mean(X, axis=0)
self.running_var = np.var(X, axis=0) if training and self.trainable:
mean = np.mean(X, axis=0)
var = np.var(X, axis=0)
self.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * mean
self.running_var = self.momentum * self.running_var + (1 - self.momentum) * var
else:
mean = self.running_mean
var = self.running_var # Statistics saved for backward pass
self.X_centered = X - mean
self.stddev_inv = 1 / np.sqrt(var + self.eps) X_norm = self.X_centered * self.stddev_inv
output = self.gamma * X_norm + self.beta return output def backward_pass(self, accum_grad): # Save parameters used during the forward pass
gamma = self.gamma # If the layer is trainable the parameters are updated
if self.trainable:
X_norm = self.X_centered * self.stddev_inv
grad_gamma = np.sum(accum_grad * X_norm, axis=0)
grad_beta = np.sum(accum_grad, axis=0) self.gamma = self.gamma_opt.update(self.gamma, grad_gamma)
self.beta = self.beta_opt.update(self.beta, grad_beta) batch_size = accum_grad.shape[0] # The gradient of the loss with respect to the layer inputs (use weights and statistics from forward pass)
accum_grad = (1 / batch_size) * gamma * self.stddev_inv * (
batch_size * accum_grad
- np.sum(accum_grad, axis=0)
- self.X_centered * self.stddev_inv**2 * np.sum(accum_grad * self.X_centered, axis=0)
) return accum_grad def output_shape(self):
return self.input_shape
批量归一化的过程:

前向传播的时候按照公式进行就可以了。需要关注的是BN层反向传播的过程。
accm_grad是上一层传到本层的梯度。反向传播过程:
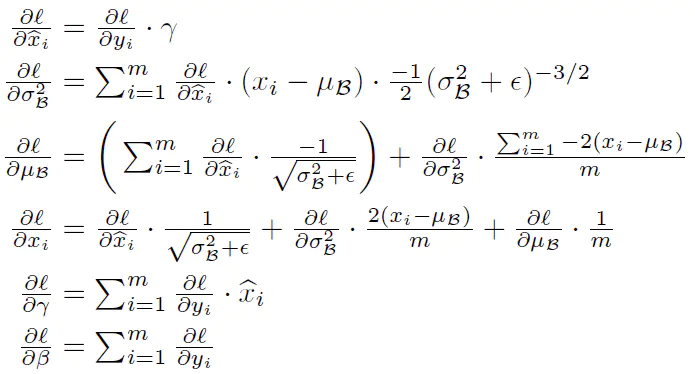
最新文章
- Ajax中get请求和post请求
- Sublime文件夹显示过滤
- 缺少google api密钥,因此chromium的部分功能将无法使用”的解决办法
- WPF中两个窗口的互斥
- VM参数简介
- MySql开启远程访问(Linux)
- sublime text 安装 SFTP
- Ansible6:Playbook简单使用【转】
- iOS开发之App主题切换完整解决方案(Swift版)
- js中一个对象中遇到一个相同的key所对应的value值相加
- es6里面的arr方法
- Chrome自定义滚动条
- python——文件读写
- >>>>>>>> [ovs][libvirt] virt-xml ovs-vsctl
- VS Access DataSet 插入
- 量子猴排(Quantum Bogo sort)
- python匿名函数 高阶函数 内置函数 文件操作
- 【Asp.net入门16】第一个ASP.NET 应用程序-总结
- RHEL6 - 图形化设置IP
- Node.js创建第一个应用
热门文章
- Deep Protein Methylation Profiling by Combined Chemical and Immunoaffinity Approaches Reveals Novel PRMT1 Targets (结合层析法和免疫沉淀法的蛋白甲基化的深度检测技术发现了PRMT1新的靶标蛋白)
- java 获取 list 集合获取指定的 字段 数组
- VMware 虚拟机正在使用中
- hdu4587 Two Nodes 求图中删除两个结点剩余的连通分量的数量
- CF1324F Maximum White Subtree 题解
- 【SQL SERVER重新认识】数据内部存储结构简单探索
- linux bash吧,还有啥Bourne Again Shell
- 一 JVM垃圾回收模型
- TensorBoard中HISTOGRAMS和DISTRIBUTIONS图形的含义
- Jmeter 注册用户获取登录token值