.NET Core/.NET之Stream简介 Rx.NET 简介
.NET Core/.NET之Stream简介
之前写了一篇C#装饰模式的文章提到了.NET Core的Stream, 所以这里尽量把Stream介绍全点. (都是书上的内容)
.NET Core/.NET的Streams
首先需要知道, System.IO命名空间是低级I/O功能的大本营.
Stream的结构
.NET Core里面的Stream主要是三个概念: 存储(backing stores 我不知道怎么翻译比较好), 装饰器, 适配器.
backing stores是让输入和输出发挥作用的端点, 例如文件或者网络连接. 就是下面任意一点或两点:
- 一个源, 从它这里字节可以被顺序的读取
- 一个目的地, 字节可以被连续的写入.
程序员可以通过Stream类来发挥backing store的作用. Stream类有一套方法, 可以进行读取, 写入, 定位等操作. 个数组不同的是, 数组是把所有的数据都一同放在了内存里, 而stream则是顺序的/连续的处理数据, 要么是一次处理一个字节, 要么是一次处理特定大小(不能太大, 可管理的范围内)的数据.
于是, stream可以用比较小的固定大小的内存来处理无论多大的backing store.
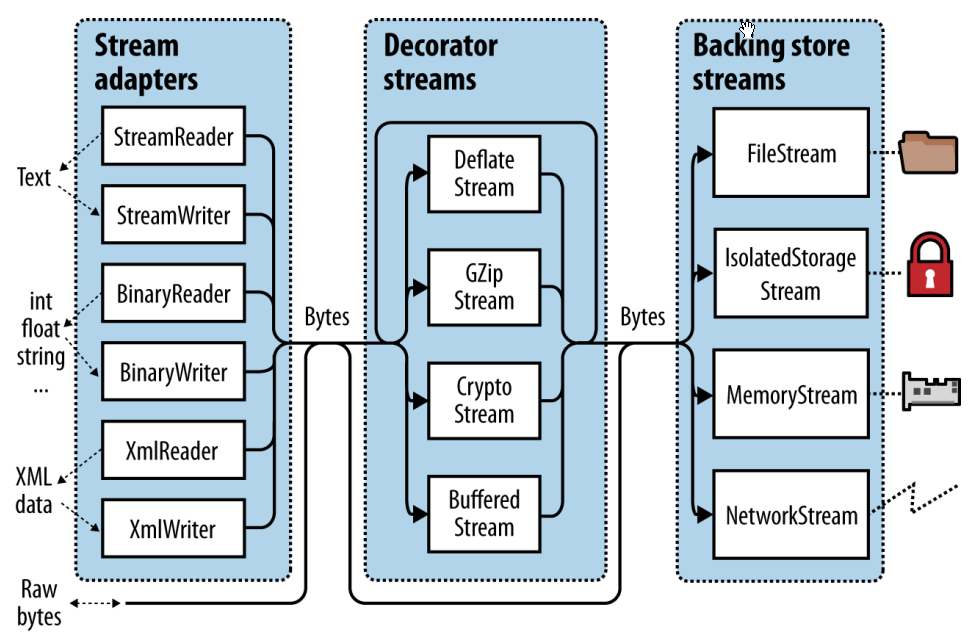
中间的那部分就是装饰器Stream. 它符合装饰模式.
从图中可以看到, Stream又分为两部分:
- Backing Store Streams: 硬连接到特定类型的backing store, 例如FileStream和NetworkStream
- Decorator Streams 装饰器Stream: 使用某种方式把数据进行了转化, 例如DeflateStream和CryptoStream.
装饰器Stream有如下结构性的优点(参考装饰模式):
- 无需让backing store stream去实现例如压缩, 加密等功能.
- 装饰的时候接口(interface)并没有变化
- 可以在运行时进行装饰
- 可以串联装饰(先后进行多个装饰)
backing store和装饰器stream都是按字节进行处理的. 尽管这很灵活和高效, 但是程序一般还是采用更高级别的处理方式例如文字或者xml.
适配器通过使用特殊化的方法把类里面的stream进行包装成特殊的格式. 这就弥合了上述的间隔.
例如 text reader有一个ReadLine方法, XML writer又WriteAttributes方法.
注意: 适配器包装了stream, 这点和装饰器一样, 但是不一样的是, 适配器本身并不是stream, 它一般会把所有针对字节的方法都隐藏起来. 所以本文就不介绍适配器了.
总结一下:
backing store stream 提供原始数据, 装饰器stream提供透明的转换(例如加密); 适配器提供方法来处理高级别的类型例如字符串和xml.
想要连成串的话, 秩序把对象传递到另一个对象的构造函数里.
使用Stream
Stream抽象类是所有Stream的基类.
它的方法和属性主要分三类基本操作: 读, 写, 寻址(Seek); 和管理操作: 关闭(close), 冲(flush)和设定超时:
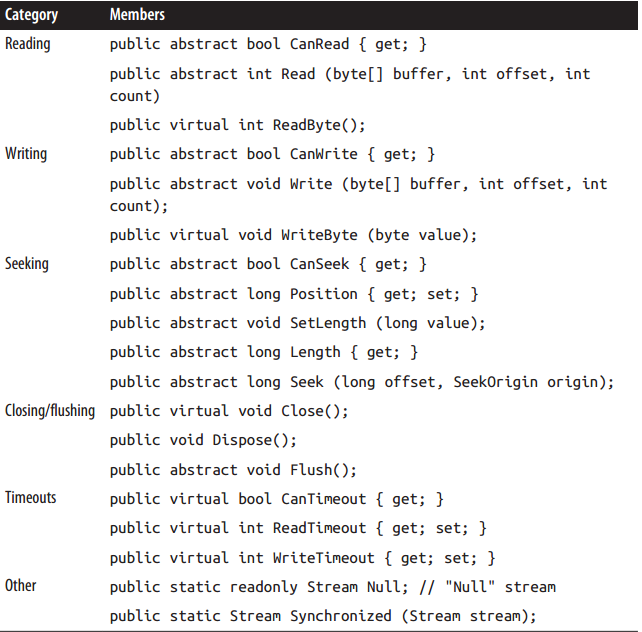
这些方法都有异步的版本, 加async, 返回Task即可.
一个例子:

using System;
using System.IO;
namespace Test
{
class Program
{
static void Main(string[] args)
{
// 在当前目录创建按一个 test.txt 文件
using (Stream s = new FileStream("test.txt", FileMode.Create))
{
Console.WriteLine(s.CanRead); // True
Console.WriteLine(s.CanWrite); // True
Console.WriteLine(s.CanSeek); // True
s.WriteByte(101);
s.WriteByte(102);
byte[] block = { 1, 2, 3, 4, 5 };
s.Write(block, 0, block.Length); // 写 5 字节
Console.WriteLine(s.Length); // 7
Console.WriteLine(s.Position); // 7
s.Position = 0; // 回到开头位置
Console.WriteLine(s.ReadByte()); // 101
Console.WriteLine(s.ReadByte()); // 102
// 从block数组开始的地方开始read:
Console.WriteLine(s.Read(block, 0, block.Length)); // 5
// 假设最后一次read返回 5, 那就是在文件结尾, 所以read会返回0:
Console.WriteLine(s.Read(block, 0, block.Length)); // 0
}
}
}
}
运行结果:
异步例子:
using System;
using System.IO;
using System.Threading.Tasks;
namespace Test
{
class Program
{
static void Main(string[] args)
{
Task.Run(AsyncDemo).GetAwaiter().GetResult();
}
async static Task AsyncDemo()
{
using (Stream s = new FileStream("test.txt", FileMode.Create))
{
byte[] block = { 1, 2, 3, 4, 5 };
await s.WriteAsync(block, 0, block.Length);
s.Position = 0;
Console.WriteLine(await s.ReadAsync(block, 0, block.Length));
}
}
}
}

异步版本比较适合慢的stream, 例如网络的stream.
读和写
CanRead和CanWrite属性可以判断Stream是否可以读写.
Read方法把stream的一块数据写入到数组, 返回接受到的字节数, 它总是小于等于count这个参数. 如果它小于count, 就说明要么是已经读取到stream的结尾了, 要么stream给的数据块太小了(网络stream经常这样).
一个读取1000字节stream的例子:
// 假设s是某个stream
byte[] data = new byte[1000];
// bytesRead 的结束位置肯定是1000, 除非stream的长度不足1000
int bytesRead = 0;
int chunkSize = 1;
while (bytesRead < data.Length && chunkSize > 0)
bytesRead +=
chunkSize = s.Read(data, bytesRead, data.Length - bytesRead);
ReadByte方法更简单一些, 一次就读一个字节, 如果返回-1表示读取到stream的结尾了. 返回类型是int.
Write和WriteByte就是相应的写入方法了. 如果无法写入某个字节, 那就会抛出异常.
上面方法签名里的offset参数, 表示的是缓冲数组开始读取或写入的位置, 而不是指stream里面的位置.
寻址 Seek
CanSeek为true的话, Stream就可以被寻址. 可以查询和修改可寻址的stream(例如文件stream)的长度, 也可以随时修改读取和写入的位置.
Position属性就是所需要的, 它是相对于stream开始位置的.
Seek方法就允许你移动到当前位置或者stream的尾部.
注意改变FileStream的Position会花去几微秒. 如果是在大规模循环里面做这个操作的话, 建议使用MemoryMappedFile类.
对于不可寻址的Stream(例如加密Stream), 想知道它的长度只能是把它读完. 而且你要是想读取前一部分的话必须关闭stream, 然后再开始一个全新的stream才可以.
关闭和Flush
Stream用完之后必须被处理掉(dispose)来释放底层资源例如文件和socket处理. 通常使用using来实现.
- Dispose和Close方法功能上是一样的.
- 重复close和flush一个stream不会报错.
关闭装饰器stream的时候会同时关闭装饰器和它的backing store stream.
针对一连串的装饰器装饰的stream, 关闭最外层的装饰器就会关闭所有.
有些stream从backing store读取/写入的时候有一个缓存机制, 这就减少了实际到backing store的往返次数以达到提高性能的目的(例如FileStream).
这就意味着你写入数据到stream的时候可能不会立即写入到backing store; 它会有延迟, 直到缓冲被填满.
Flush方法会强制内部缓冲的数据被立即的写入. Flush会在stream关闭的时候自动被调用. 所以你不需要这样写: s.Flush(); s.Close();
超时
如果CanTimeout属性为true的话, 那么该stream就可以设定读或写的超时.
网络stream支持超时, 而文件和内存stream则不支持.
支持超时的stream, 通过ReadTimeout和WriteTimeout属性可以设定超时, 单位毫秒. 0表示无超时.
Read和Write方法通过抛出异常的方式来表示超时已经发生了.
线程安全
stream并不是线程安全的, 也就是说两个线程同时读或写一个stream的时候就会报错.
Stream通过Synchronized方法来解决这个问题. 该方法接受stream为参数, 返回一个线程安全的包装结果.
这个包装结果在每次读, 写, 寻址的时候会获得一个独立锁/排他锁, 所以同一时刻只有一个线程可以执行操作.
实际上, 这允许多个线程同时为同一个数据追加数据, 而其他类型的操作(例如同读)则需要额外的锁来保证每个线程可以访问到stream相应的部分.
Backing Store Stream
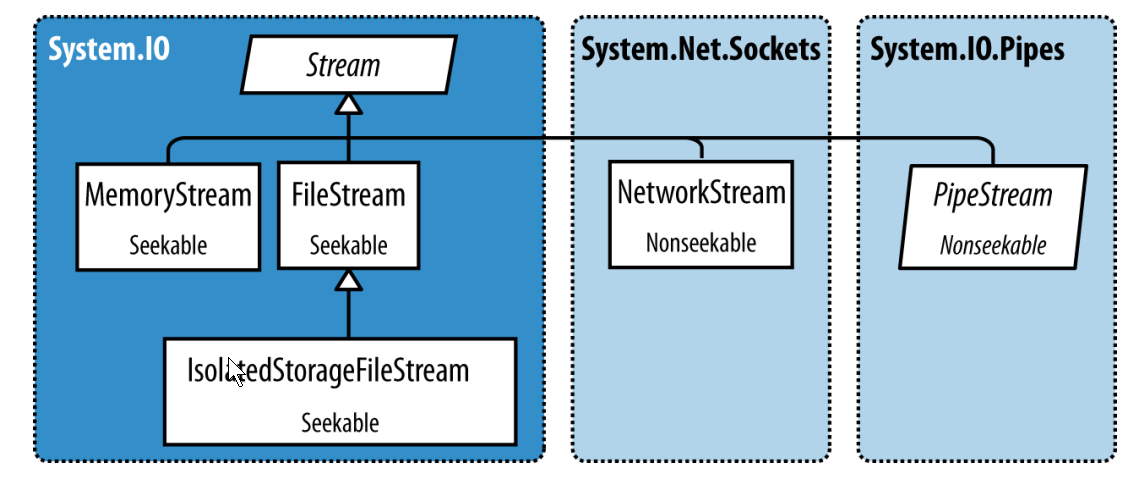
FileStream
文件流
构建一个FileStream:
FileStream fs1 = File.OpenRead("readme.bin"); // Read-only
FileStream fs2 = File.OpenWrite(@"c:\temp\writeme.tmp"); // Write-only
FileStream fs3 = File.Create(@"c:\temp\writeme.tmp"); // Read/write
OpenWrite和Create对于已经存在的文件来说, 它的行为是不同的.
Create会把现有文件的内容清理掉, 写入的时候从头开写.
OpenWrite则是完整的保存着现有的内容, 而stream的位置定位在0. 如果写入的内容比原来的内容少, 那么OpenWrite打开并写完之后的内容是原内容和新写入内容的混合体.
直接构建FileStream:
var fs = new FileStream ("readwrite.tmp", FileMode.Open); // Read/write
其构造函数里面还可以传入其他参数, 具体请看文档.
File类的快捷方法:
下面这些静态方法会一次性把整个文件读进内存:
- File.ReadAllText(返回string)
- File.ReadAllLines(返回string数组)
- File.ReadAllBytes(返回byte数组)
下面的方法直接写入整个文件:
- File.WriteAllText
- File.WriteAllLines
- File.WriteAllBytes
- File.AppendAllText (很适合附加log文件)
还有一个静态方法叫File.ReadLines: 它有点想ReadAllLines, 但是它返回的是一个懒加载的IEnumerable<string>. 这个实际上效率更高一些, 因为不必一次性把整个文件都加载到内存里. LINQ非常适合处理这个结果. 例如:
int longLines = File.ReadLines ("filePath").Count (l => l.Length > 80);
指定的文件名:
可以是绝对路径也可以是相对路径.
可已修改静态属性Environment.CurrentDirectory的值来改变当前的路径. (注意: 默认的当前路径不一定是exe所在的目录)
AppDomain.CurrentDomain.BaseDirectory会返回应用的基目录, 它通常是包含exe的目录.
指定相对于这个目录的地址最好使用Path.Combine方法:
string baseFolder = AppDomain.CurrentDomain.BaseDirectory;
string logoPath = Path.Combine(baseFolder, "logo.jpg");
Console.WriteLine(File.Exists(logoPath));
通过网络对文件读写要使用UNC路径:
例如: \\JoesPC\PicShare \pic.jpg 或者 \\10.1.1.2\PicShare\pic.jpg.
FileMode:
所有的FileStream的构造器都会接收一个文件名和一个FileMode枚举作为参数. 如果选择FileMode请看下图:
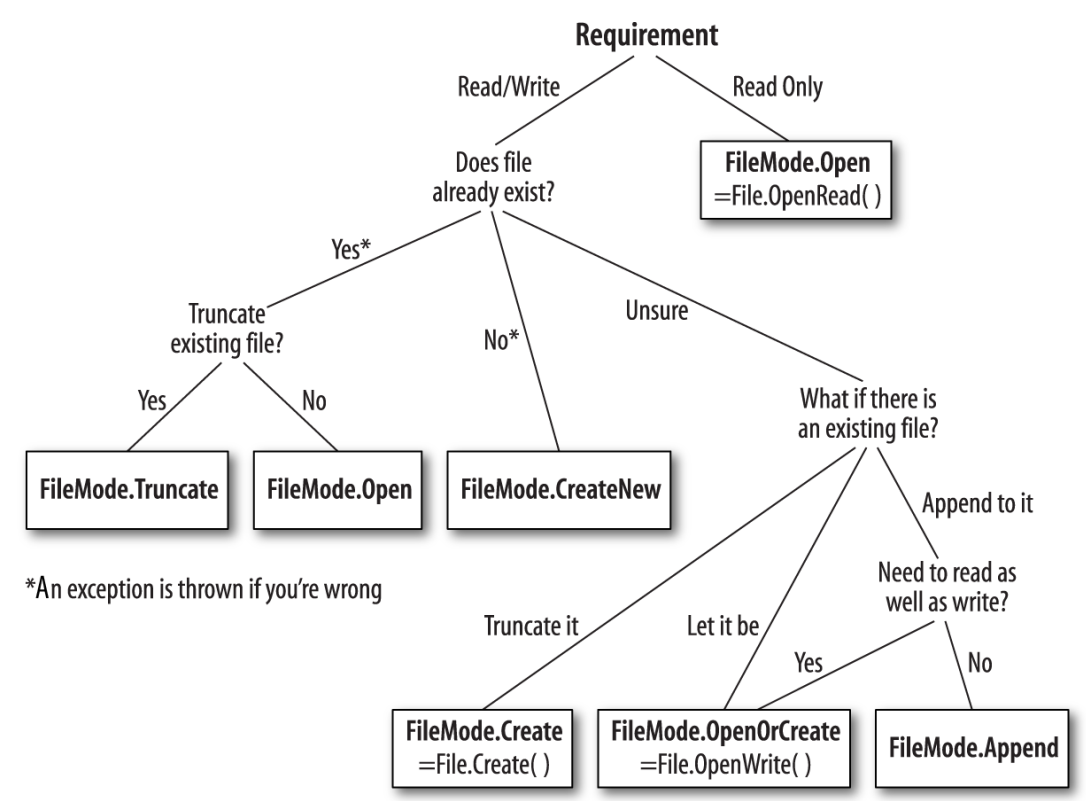
其他特性还是需要看文档.
MemoryStream
MemoryStream在随机访问不可寻址的stream时就有用了.
如果你知道源stream的大小可以接受, 你就可以直接把它复制到MemoryStream里:
var ms = new MemoryStream();
sourceStream.CopyTo(ms);
可以通过ToArray方法把MemoryStream转化成数组.
GetBuffer方法也是同样的功能, 但是因为它是直接把底层的存储数组的引用直接返回了, 所以会更有效率. 不过不幸的是, 这个数组通常比stream的真实长度要长.
注意: Close和Flush 一个MemoryStream是可选的. 如果关闭了MemoryStream, 你就再也不能对它读写了, 但是仍然可以调用ToArray方法来获取其底层的数据.
Flush则对MemoryStream毫无用处.
PipeStream
PipeStream通过Windows Pipe 协议, 允许一个进程(process)和另一个进程通信.
分两种:
- 匿名进程(快一点), 允许同一个电脑内的父子进程单向通信.
- 命名进程(更灵活), 允许同一个电脑内或者同一个windows网络内的不同电脑间的任意两个进程间进行双向通信
pipe很适合一个电脑上的进程间交互(IPC), 它并不依赖于网络传输, 这也意味着没有网络开销, 也不在乎防火墙.
注意: pipe是基于Stream的, 一个进程等待接受一串字符的同时另一个进程发送它们.
PipeStream是抽象类.
具体的实现类有4个:
匿名pipe:
- AnonymousePipeServerStream
- AnonymousePipeClientStream
命名Pipe:
- NamedPipeServerStream
- NamePipeClientStream
命名Pipe
命名pipe的双方通过同名的pipe进行通信. 协议规定了两个角色: 服务器和客户端. 按照下述方式进行通信:
- 服务器实例化一个NamedPipeServerStream然后调用WaitForConnection方法.
- 客户端实例化一个NamedPipeClientStream然后调用Connect方法(可以设定超时).
然后双方就可以读写stream来进行通信了.
例子:
using System;
using System.IO;
using System.IO.Pipes;
using System.Threading.Tasks;
namespace Test
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(DateTime.Now.ToString());
using (var s = new NamedPipeServerStream("pipedream"))
{
s.WaitForConnection();
s.WriteByte(100); // Send the value 100.
Console.WriteLine(s.ReadByte());
}
Console.WriteLine(DateTime.Now.ToString());
}
}
}
using System;
using System.IO.Pipes;
namespace Test2
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(DateTime.Now.ToString());
using (var s = new NamedPipeClientStream("pipedream"))
{
s.Connect();
Console.WriteLine(s.ReadByte());
s.WriteByte(200); // Send the value 200 back.
}
Console.WriteLine(DateTime.Now.ToString());
}
}
}

命名的PipeStream默认情况下是双向的, 所以任意一方都可以进行读写操作, 这也意味着服务器和客户端必须达成某种协议来协调它们的操作, 避免同时进行发送和接收.
还需要协定好每次传输的长度.
在处理长度大于一字节的信息的时候, pipe提供了一个信息传输的模式, 如果这个启用了, 一方在调用read的时候可以通过检查IsMessageComplete属性来知道消息什么时候结束.
例子:
static byte[] ReadMessage(PipeStream s)
{
MemoryStream ms = new MemoryStream();
byte[] buffer = new byte[0x1000]; // Read in 4 KB blocks
do { ms.Write(buffer, 0, s.Read(buffer, 0, buffer.Length)); }
while (!s.IsMessageComplete); return ms.ToArray();
}
注意: 针对PipeStream不可以通过Read返回值是0的方式来它是否已经完成读取消息了. 这是因为它和其他的Stream不同, pipe stream和network stream没有确定的终点. 在两个信息传送动作之间, 它们就干等着.
这样启用信息传输模式, 服务器端 :
using (var s = new NamedPipeServerStream("pipedream", PipeDirection.InOut, 1, PipeTransmissionMode.Message))
{
s.WaitForConnection();
byte[] msg = Encoding.UTF8.GetBytes("Hello");
s.Write(msg, 0, msg.Length);
Console.WriteLine(Encoding.UTF8.GetString(ReadMessage(s)));
}
客户端:
using (var s = new NamedPipeClientStream("pipedream"))
{
s.Connect();
s.ReadMode = PipeTransmissionMode.Message;
Console.WriteLine(Encoding.UTF8.GetString(ReadMessage(s)));
byte[] msg = Encoding.UTF8.GetBytes("Hello right back!");
s.Write(msg, 0, msg.Length);
}
匿名pipe:
匿名pipe提供父子进程间的单向通信. 流程如下:
- 服务器实例化一个AnonymousPipeServerStream, 并指定PipeDirection是In还是Out
- 服务器调用GetClientHandleAsString方法来获取一个pipe的标识, 然后会把它传递给客户端(通常是启动子进程的参数 argument)
- 子进程实例化一个AnonymousePipeClientStream, 指定相反的PipeDirection
- 服务器通过调用DisposeLocalCopyOfClientHandle释放步骤2的本地处理,
- 父子进程间通过读写stream进行通信
因为匿名pipe是单向的, 所以服务器必须创建两份pipe来进行双向通信
例子:
server:
using System;
using System.Diagnostics;
using System.IO;
using System.IO.Pipes;
using System.Text;
using System.Threading.Tasks;
namespace Test
{
class Program
{
static void Main(string[] args)
{
string clientExe = @"D:\Projects\Test2\bin\Debug\netcoreapp2.0\win10-x64\publish\Test2.exe";
HandleInheritability inherit = HandleInheritability.Inheritable;
using (var tx = new AnonymousPipeServerStream(PipeDirection.Out, inherit))
using (var rx = new AnonymousPipeServerStream(PipeDirection.In, inherit))
{
string txID = tx.GetClientHandleAsString();
string rxID = rx.GetClientHandleAsString();
var startInfo = new ProcessStartInfo(clientExe, txID + " " + rxID);
startInfo.UseShellExecute = false; // Required for child process
Process p = Process.Start(startInfo);
tx.DisposeLocalCopyOfClientHandle(); // Release unmanaged
rx.DisposeLocalCopyOfClientHandle(); // handle resources.
tx.WriteByte(100);
Console.WriteLine("Server received: " + rx.ReadByte());
p.WaitForExit();
}
}
}
}
client:
using System;
using System.IO.Pipes;
namespace Test2
{
class Program
{
static void Main(string[] args)
{
string rxID = args[0]; // Note we're reversing the
string txID = args[1]; // receive and transmit roles.
using (var rx = new AnonymousPipeClientStream(PipeDirection.In, rxID))
using (var tx = new AnonymousPipeClientStream(PipeDirection.Out, txID))
{
Console.WriteLine("Client received: " + rx.ReadByte());
tx.WriteByte(200);
}
}
}
}
最好发布一下client成为独立运行的exe:
dotnet publish --self-contained --runtime win10-x64
运行结果:
匿名pipe不支持消息模式, 所以你必须自己来为传输的长度制定协议. 有一种做法是: 在每次传输的前4个字节里存放一个整数表示消息的长度, 可以使用BitConverter类来对整型和长度为4的字节数组进行转换.
BufferedStream
BufferedStream对另一个stream进行装饰或者说包装, 让它拥有缓冲的能力.它也是众多装饰stream类型中的一个.
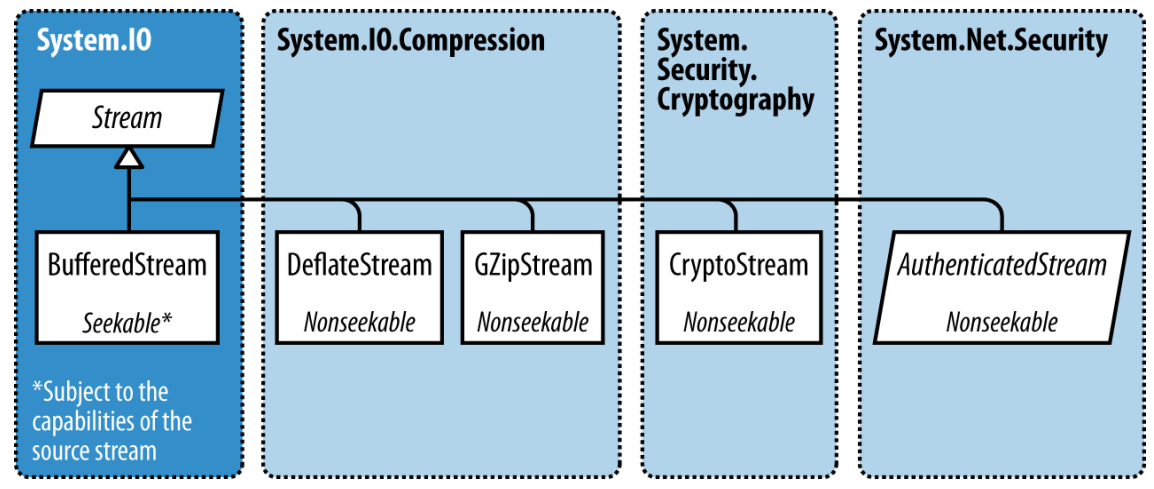
缓冲肯定会通过减少往返backing store的次数来提升性能.
下面这个例子是把一个FileStream装饰成20k的缓冲stream:
// Write 100K to a file:
File.WriteAllBytes("myFile.bin", new byte[100000]);
using (FileStream fs = File.OpenRead("myFile.bin"))
using (BufferedStream bs = new BufferedStream(fs, 20000)) //20K buffer
{
bs.ReadByte();
Console.WriteLine(fs.Position); // 20000
}
}
通过预读缓冲, 底层的stream会在读取1字节后, 直接预读了20000字节, 这样我们在另外调用ReadByte 19999次之后, 才会再次访问到FileStream.
这个例子是把BufferedStream和FileStream耦合到一起, 实际上这个例子里面的缓冲作用有限, 因为FileStream有一个内置的缓冲. 这个例子也只能扩大一下缓冲而已.
关闭BufferedStream就会关闭底层的backing store stream..
Stream适配器
Stream只按字节处理, 对string, 整型, xml等都是通过字节进行读写的, 所以必须插入一个适配器.
.NET Core提供了这些文字适配器:
- TextReader, TextWriter
- StreamReader, StreamWriter
- StringReader, StringWriter
二进制适配器(适用于原始类型例如int bool string float等):
- BinaryReader, BinaryWriter
XML适配器:
- XmlReader, XmlWiter
这些适配器的关系图:

文字适配器
TextReader 和 TextWriter是文字适配器的基类. 它俩分别对应两套实现:
- StreamReader/StreamWriter: 使用Stream作为原始数据存储, 把stream的字节转化成字符或字符串
- StringReader/StringWriter: 使用的是内存中的字符串
TextReader:

Peek方法会返回下一个字符而不改变当前(可以看作是索引)的位置.
在Stream读取到结束点的时候Peek和无参数的Read方法都会返回-1, 否则它们会返回一个可以被转换成字符的整型.
Read的重载方法(接受char[]缓冲参数)在功能上和ReadBlock方法是一样的.
ReadLine方法会一直读取直到遇到了CR或LF或CR+LF对(以后再介绍), 然后会放回字符串, 但是不包含CR/LF等字符.
注意: C#应该使用"\r\n"来还行, 顺序写反了可能会不换行患者换两行.
TextWriter:

方法与TextReader类似.
Write和WriteLine有几个重载方法可以接受所有的原始类型, 还有object类型. 这些方法会调用被传入参数的ToString方法. 另外也可以在构造函数或者调用方法的时候通过IFormatProvider进行指定.
WriteLine会在给定的文字后边加上CR+LF, 您可以通过修改NewLine属性来改变这个行为(尤其是与UNIX文件格式交互的时候).
上面讲的这些方法, 都有异步版本的
StreamReader和StreamWriter
直接看例子即可:
using (FileStream fs = File.Create("test.txt"))
using (TextWriter writer = new StreamWriter(fs))
{
writer.WriteLine("Line 1");
writer.WriteLine("Line 2");
}
using (FileStream fs = File.OpenRead("test.txt"))
using (TextReader reader = new StreamReader(fs))
{
Console.WriteLine(reader.ReadLine());
Console.WriteLine(reader.ReadLine());
}

由于文字适配器经常要处理文件, 所以File类提供了一些静态方法例如: CreateText, AppendText, OpenText来做快捷操作:
上面的例子可以写成:
using (TextWriter writer = File.CreateText("test.txt"))
{
writer.WriteLine("Line1");
writer.WriteLine("Line2");
}
using (TextWriter writer = File.AppendText("test.txt"))
writer.WriteLine("Line3");
using (TextReader reader = File.OpenText("test.txt"))
while (reader.Peek() > -1)
Console.WriteLine(reader.ReadLine());
代码中可以看到, 如何知道是否读取到了文件的结尾(通过reader.Peek()). 另一个方法是使用reader.ReadLine方法读取直到返回null.
也可以读取其他的类型, 例如int(因为TextWriter会调用ToString方法), 但是读取的时候想要变成原来的类型就得进行解析字符串操作了.
字符串编码
TextReader和TextWriter是抽象类, 跟sream或者backing store没有连接. StreamReader和StreamWriter则连接着一个底层的字节流, 所以它们必须对字符串和字节进行转换. 它们通过System.Text.Encoding类来做这些工作, 也就是构建StreamReader或StreamWriter的时候选择一个Encoding. 如果你没选那么就是UTF-8了.
注意: 如果你明确指定了一个编码, 那么StreamWriter默认会在流的前边加一个前缀, 这个前缀是用来识别编码的. 如果你不想这样做的话, 那么可以这样做:
var encoding = new UTF8Encoding(
encoderShouldEmitUTF8Identifier: false,
throwOnInvalidBytes: true
);
第二个参数是告诉StreamWriter, 如果遇到了本编码下的非法字符串, 那就抛出一个异常. 如果不指定编码的情况下, 也是这样的.
最简单的编码是ASCII, 每一个字符通过一个字节来表示. ASCII对Unicode的前127个字符进行了映射, 包含了US键盘上面所有的键. 而其他的字符, 例如特殊字符和非英语字符等无法被表达的字符则会显示成□. 默认的UTF-8编码影射了所有的Unicode字符, 但是它更复杂. 前127个字节使用单字节, 这是为了和ASCII兼容; 而剩下的字节编码成了不定长的字节数(通常是2或者3字节).
UTF-8处理西方语言的文字还不错, 但是在stream里面搜索/寻址就会遇到麻烦了, 这时可以使用UTF-16这个候选(Encoding类里面叫Unicode).
UTF-16针对每个字符使用2个或4个字节, 但是由于C#的char类型是16bit的, 所以针对.NET的char, UTF-16正好使用两个字节. 这样在stream里面找到特定字符的索引就方便多了.
UTF-16会使用一个2字节长的前缀, 来识别字节对是按little-endian还是big-endian的顺序存储的. windows系统默认使用little-endian.
StringReader和StringWriter
这两个适配器根本不包装stream; 它们使用String或StringBuilder作为数据源, 所以不需要字节转换.
实际上这两个类存在的主要优势就是: 它们和StreamReader/StreamWriter具有同一个父类.
例如有一个含有xml的字符串, 我想把它用XmlReader进行解析, XmlReader.Create方法可以接受下列参数:
- URI
- Stream
- TextReader
因为StringReader是TextReader的子类, 所以我就可以这样做:
XmlReader reader = XmlReader.Create(new StringReader("...xml string..."));
二进制适配器
BinaryReader和BinaryWriter可以读取/写入下列类型: bool, byte, char, decimal, float, double, short, int, long, sbyte, ushort, uint, ulong 以及string和由原始类型组成的数组.
和StreamReader/StreamWriter不同的是, 二进制适配器对原始数据类型的存储效率是非常高的, 因为都是在内存里.
int使用4个字节, double 8个字节......
string则是通过文字编码(就像StreamReader和StreamWriter), 但是长度是固定的, 以便可以对string回读, 而不需要使用分隔符.
举个例子:
public class Person
{
public string Name;
public int Age;
public double Height;
public void SaveData(Stream s)
{
var w = new BinaryWriter(s);
w.Write(Name);
w.Write(Age);
w.Write(Height);
w.Flush();
}
public void LoadData(Stream s)
{
var r = new BinaryReader(s);
Name = r.ReadString();
Age = r.ReadInt32();
Height = r.ReadDouble();
}
}
这个例子里, Person类使用SaveData和LoadData两个方法把它的数据写入到Stream/从Stream读取出来, 里面用的是二进制适配器.
由于BinaryReader可以读取到字节数组, 所以可以把要读取的内容转化成可寻址的stream:
byte[] data = new BinaryReader(s).ReadBytes((int)sbyte.Length);
关闭和清理Stream适配器
有四种做法可以把stream适配器清理掉:
- 只关闭适配器
- 关闭适配器, 然后关闭stream
- (对于Writers), Flush适配器, 然后关闭Stream.
- (对于Readers), 关闭Stream.
注意: Close和Dispose对于适配器来说功能是一样的, 这点对Stream也一样.
上面的前两种写法实际上是一样的, 因为关闭适配器的话会自动关闭底层的Stream. 当嵌套使用using的时候, 就是隐式的使用方法2:
using (FileStream fs = File.Create("test.txt"))
using (TextWriter writer = new StreamWriter(fs))
{
writer.WriteLine("Line");
}
这是因为嵌套的dispose是从内而外的, 适配器先关闭, 然后是Stream. 此外, 如果在适配器的构造函数里发生异常了, 这个Stream仍然会关闭, 嵌套使用using是很难出错的.
注意: 不要在关闭或flush stream的适配器writer之前去关闭stream, 那会截断在适配器缓冲的数据.
第3, 4中方法之所以可行, 是因为适配器是比较另类的, 它们是可选disposable的对象. 看下面的例子:
using (FileStream fs = new FileStream("test.txt", FileMode.Create))
{
StreamWriter writer = new StreamWriter(fs);
writer.WriteLine("Hello");
writer.Flush();
fs.Position = 0;
Console.WriteLine(fs.ReadByte());
}
这里, 我对一个文件进行了写入动作, 然后重定位stream, 读取第一个字节. 我想把Stream开着, 因为以后还要用到.
这时, 如果我dispose了StreamWriter, 那么FileStream就被关闭了, 以后就无法操作它了. 所以没有调用writer的dispose或close方法.
但是这里需要flush一下, 以确保StreamWriter的缓存的内容都写入到了底层的stream里.
注意: 鉴于适配器的dispose是可选的, 所以不再使用的适配器就可以躲开GC的清理操作.
.net 4.5以后, StreamReader/StreamWriter有了一个新的构造函数, 它可以接受一个参数, 来指定在dispose之后是否让Stream保持开放:
using (var fs = new FileStream("test.txt", FileMode.Create))
{
using (var writer = new StreamWriter(fs, new UTF8Encoding(false, true),
0x400, true))
writer.WriteLine("Hello");
fs.Position = 0; Console.WriteLine(fs.ReadByte());
Console.WriteLine(fs.Length);
}
压缩Stream
在System.IO.Compression下有两个压缩Stream: DeflateStream和GZipStream. 它们都使用了一个类似于ZIP格式的压缩算法. 不同的是GZipStream会在开头和结尾写入额外的协议--包括CRC错误校验.GZipStream也符合其他软件的标准.
这两种Stream在读写的时候有这两个条件:
- 写入Stream的时候是压缩
- 读取Stream的时候是解压缩
DeflateStream和GZipStream都是装饰器(参考装饰设计模式); 它们会压缩/解压缩从构造函数传递进来的Stream. 例如:
using (Stream s = File.Create("compressed.bin"))
using (Stream ds = new DeflateStream(s, CompressionMode.Compress))
for (byte i = 0; i < 100; i++)
ds.WriteByte(i);
using (Stream s = File.OpenRead("compressed.bin"))
using (Stream ds = new DeflateStream(s, CompressionMode.Decompress))
for (byte i = 0; i < 100; i++)
Console.WriteLine(ds.ReadByte()); // Writes 0 to 99
上面这个例子里, 即使是压缩的比较小的, 文件在压缩后也有241字节长, 比原来的两倍还多....这是因为, 压缩算法对于这种"稠密"的非重复的二进制数据处理的很不好(加密的数据更完), 但是它对文本类的文件还是处理的很好的.
Task.Run(async () =>
{
string[] words = "The quick brown fox jumps over the lazy dog".Split();
Random rand = new Random();
using (Stream s = File.Create("compressed.bin"))
using (Stream ds = new DeflateStream(s, CompressionMode.Compress))
using (TextWriter w = new StreamWriter(ds))
for (int i = 0; i < 1000; i++)
await w.WriteAsync(words[rand.Next(words.Length)] + " ");
Console.WriteLine(new FileInfo("compressed.bin").Length);
using (Stream s = File.OpenRead("compressed.bin"))
using (Stream ds = new DeflateStream(s, CompressionMode.Decompress))
using (TextReader r = new StreamReader(ds))
Console.Write(await r.ReadToEndAsync());
}).GetAwaiter().GetResult();

压缩后的长度是856!
在内存中压缩
有时候需要把整个压缩都放在内存里, 这就要用到MemoryStream:
byte[] data = new byte[1000]; // 对于空数组, 我们可以期待一个很好的压缩比率!
var ms = new MemoryStream();
using (Stream ds = new DeflateStream(ms, CompressionMode.Compress))
ds.Write(data, 0, data.Length);
byte[] compressed = ms.ToArray();
Console.WriteLine(compressed.Length); // 14
// 解压回数组:
ms = new MemoryStream(compressed);
using (Stream ds = new DeflateStream(ms, CompressionMode.Decompress))
for (int i = 0; i < 1000; i += ds.Read(data, i, 1000 - i)) ;

这里第一个using走完的时候MemoryStream会被关闭, 所以只能使用ToArray方法来提取它的数据.
下面是另外一种异步的做法, 可以避免关闭MemoryStream:
Task.Run(async () =>
{
byte[] data = new byte[1000];
MemoryStream ms = new MemoryStream();
using (Stream ds = new DeflateStream(ms, CompressionMode.Compress, true))
await ds.WriteAsync(data, 0, data.Length);
Console.WriteLine(ms.Length);
ms.Position = 0;
using (Stream ds = new DeflateStream(ms, CompressionMode.Decompress))
for (int i = 0; i < 1000; i += await ds.ReadAsync(data, i, 1000 - i)) ;
}).GetAwaiter().GetResult();
注意DeflateStream的最后一个参数.
ZIP文件操作
.NET 4.5之后, 通过新引入的ZpiArchive和ZipFile类(System.IO.Compression下, Assembly是System.IO.Compression.FileSytem.dll), 我们就可以直接操作zip文件了.
zip格式相对于DelfateStream和GZipStream的优势是, 它可以作为多个文件的容器.
ZipArchive配合Stream进行工作, 而ZipFile则是更多的和文件打交道.(ZipFile是ZipArchive的一个Helper类).
ZipFIle的CreateFromDirectory方法会把指定目录下的所有文件打包成zip文件:
ZipFile.CreateFromDirectory (@"d:\MyFolder", @"d:\compressed.zip");
而ExtractToDirectory则是做相反的工作:
ZipFile.ExtractToDirectory (@"d:\compressed.zip", @"d:\MyFolder");
压缩的时候, 可以指定是否对文件的大小, 压缩速度进行优化, 也可以指定压缩后是否包含源目录.
ZipFile的Open方法可以用来读写单独的条目, 它会返回一个ZipArchive对象(你也可以通过使用Stream对象初始化ZipArchive对象得到). 调用Open方法的时候, 你可以指定文件名和指定想要进行的动作: 读, 写, 更新. 你可以通过Entries属性遍历所有的条目, 想找到特定的条目可以使用GetEntry方法:
using (ZipArchive zip = ZipFile.Open (@"d:\zz.zip", ZipArchiveMode.Read))
foreach (ZipArchiveEntry entry in zip.Entries)
Console.WriteLine (entry.FullName + " " + entry.Length);
ZipArchiveEntry还有一个Delete方法和一个ExtractToFile(这个其实是ZipFIleExtensions里面的extension方法)方法, 还有个Open方法返回可读写的Stream. 你可以通过调用CreateEntry方法(或者CreateEntryFromFile这个extension方法)在ZipArchive上创建新的条目.
例子:
byte[] data = File.ReadAllBytes (@"d:\foo.dll");
using (ZipArchive zip = ZipFile.Open (@"d:\zz.zip", ZipArchiveMode.Update))
zip.CreateEntry (@"bin\X64\foo.dll").Open().Write (data, 0, data.Length);
上面例子里的操作完全可以在内存中实现, 使用MemoryStream即可.
Rx.NET 简介
它支持基本所有的主流语言.
这里我简单介绍一下Rx.NET.
之前我写了几篇关于RxJS的文章, 概念性的东西推荐看这些:
http://www.cnblogs.com/cgzl/p/8641738.html
http://www.cnblogs.com/cgzl/p/8649477.html
http://www.cnblogs.com/cgzl/p/8662625.html
基本概念和RxJS是一样的.
下面开始切入正题.
Rx.NET总览
Rx.NET总体上看可以分为三个部分:
- 核心部分: Observables, Observers和Subjects
- LINQ和扩展, 用于查询和过滤Observables
- 并发和调度的支持
.NET Core的Events
.net core里面的event是通过委托对观察者模式的实现.
但是event在.net core里面并不是头等公民:
- 人们对它的语法+=评价是褒贬不一的.
- 很难进行传递和组合
- 很难进行event的连串(chaining)和错误处理(尤其是同一个event有多个handler的时候)
- event并没有历史记录
举个例子:
鼠标移动这个事件(event), 鼠标移动的时候会触发该事件, 这些事件会进入某个管道并记录该鼠标的坐标, 这样就会产生一个数据的集合/序列/流.
这里我们就是构建了一个基于时间线的鼠标坐标的序列, 每一次触发事件就会在这个管道上产生一个新的值. 在另一端, 一旦管道上有了新的值, 那么管道的观察者就会得到通知, 这些观察者通过提供回调函数的方式来注册到该管道上. 管道每次更新的时候, 这些回调函数就会被调用, 从而刷新了观察者的数据.
这个例子里, Observable就是管道, 一系列的值在这里被生成. Observer(观察者)在Observable有新的值的时候会被通知.
核心接口
IObservable:
- Subscribe(IObserver<T> observer)
IObserver
- void OnNext<T>(T value), 序列里有新的值的时候会调用这个
- void OnCompleted(), 序列结束的时候调用这个
- void OnError(Exception ex), 发生错误的时候调用这个
这个和RxJS基本是一样的.
Marble图
可以通过marble图来理解Rx
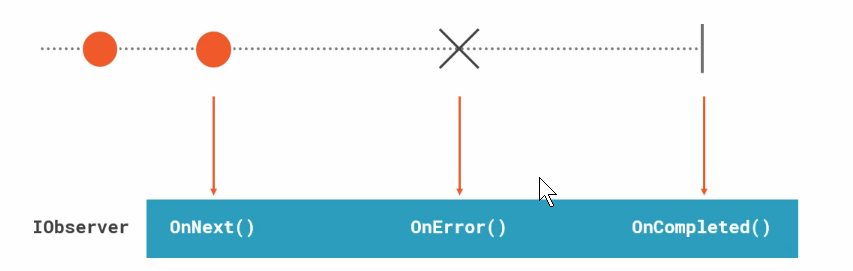
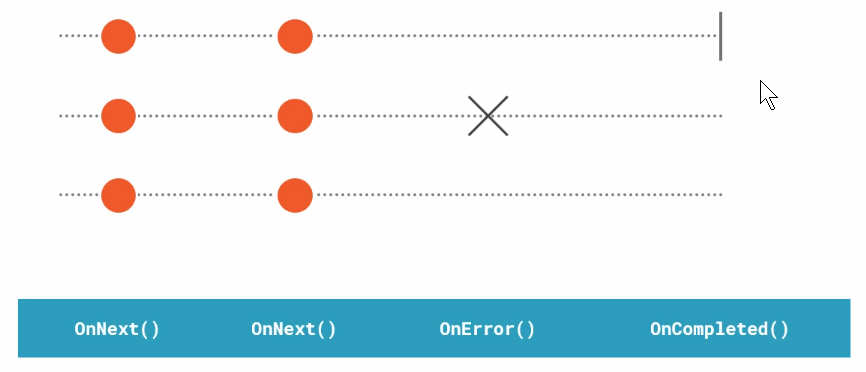
这图表示的是IObserver, 每当有新的值在Observable出现的时候, 传递到IObservable的Subscribe方法的参数IObserver的OnNext方法就会调用. 发生错误的话 OnError方法就会调用, 整个流也就结束了. 没有错误的话, 走到结束就会调用OnComplete方法. 不过有些Observable是不会结束的.
Observable.Subscribe()返回的Subscription对象被Dispose后, Observer就无法收到新的数据了.
创建Observable流/序列
创建流/序列的方式:
- 返回简单的值
- 包装现有的值
- 写一个生成函数
简单的Observables
- Observable.Empty 返回一个直接结束的Obsevable序列
- Observable.Never 返回一个没有值, 且永远不会结束的序列
- Observable.Throw(exception), 返回一个带有错误的序列
- Observable.Return(xxx) 返回单值的序列
包装Observables
可以包装下面这些来返回Observable:
- Action
- Observable.Start(() => 42) 返回一个含有42的序列, 并在Action结束的时候, OnComplete方法被调用.
- Task
- Task.ToObservable() 使用这个扩展方法进行包装, 当Task结束的时候, Observable推送新的数据, 然后结束
- IEnumerable
- ienumerable.ToObservable() 也是扩展方法, ienumerable的每个值都会作为新的值被推送到Observable上, 最后结束OnComplete
- Event
- Observable.FromEventPattern(obj, "xxChanged") 这是个工厂方法, 需要提供触发event的对象和event的名字.
生成函数
- Range
- Interval, Timer
- Create(低级), Generate
看图解释:
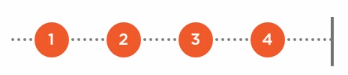
Observable.Range(1, 4):
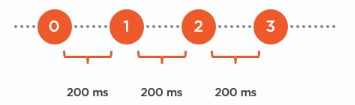
Observable.Interval(200):
Observable.Timer(200, () => 42):

Observable.Create<int>(o =>
{
o.OnNext(42);
o.OnComplete();
return Disposable.Empty;
});

Observable.Generate(1, value => value < 5, value => value + 1, value => value);
例子
using System;
using System.Reactive.Disposables;
using System.Reactive.Linq;
using System.Reactive.Threading.Tasks;
using System.Threading.Tasks;
namespace Test
{
class Program
{
static void Main(string[] args)
{
var sequence = GetTaskObservable();
sequence.Subscribe
(
x => Console.WriteLine($"OnNext: {x}"),
ex => Console.WriteLine($"OnError: {ex}"),
() => Console.WriteLine("OnCompleted")
);
Console.ReadKey();
}
private static IObservable<int> GetSimpleObservable()
{
return Observable.Return(42);
}
private static IObservable<int> GetThrowObservable()
{
return Observable.Throw<int>(new ArgumentException("Error in observable"));
}
private static IObservable<int> GetEmptyObservable()
{
return Observable.Empty<int>();
}
private static IObservable<int> GetTaskObservable()
{
return GetTask().ToObservable();
}
private static async Task<int> GetTask()
{
return 42;
}
private static IObservable<int> GetRangeObservable()
{
return Observable.Range(2, 10);
}
private static IObservable<long> GetIntervalObservable()
{
return Observable.Interval(TimeSpan.FromMilliseconds(200));
}
private static IObservable<int> GetCreateObservable()
{
return Observable.Create<int>(observer =>
{
observer.OnNext(1);
observer.OnNext(2);
observer.OnNext(3);
observer.OnNext(4);
observer.OnCompleted();
return Disposable.Empty;
});
}
private static IObservable<int> GetGenerateObservable()
{
return Observable.Generate(
1,
x => x < 5,
x => x + 1,
x => x
);
}
}
}
请自行运行查看结果.
Cold 和 Hot Observable
Cold: Observable可以为每个Subscriber创建新的数据生产者
Hot: 每个Subscriber从订阅的时候开始在同一个数据生产者那里共享其余的数据.
从原理来说是这样的: Cold内部会创建一个新的数据生产者, 而Hot则会一直使用外部的数据生产者.
举个例子:
Cold: 就相当于我在腾讯视频买体育视频会员, 可以从头看里面的足球比赛.
Hot: 就相当于看足球比赛的现场直播, 如果来晚了, 那么前面就看不到了.
把Cold 变 Hot, 使用.Publish()方法.
把Hot 变 Cold, 使用.Subscribe()方法把它变成Subject即可.
过滤和控制序列
LINQ操作符
操作符的类型:
- 过滤
- 合并
- 聚合
- 工具
过滤
sequence.Where(x => x % 2 == 0):
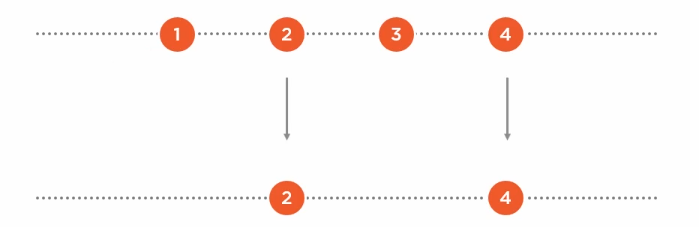
.OfType<Square>():

移除重复的:
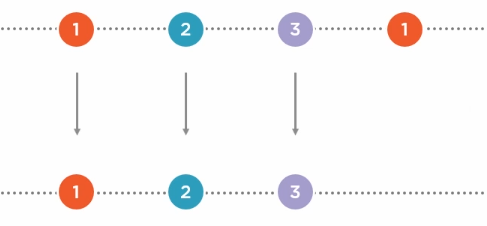
.Distinct():
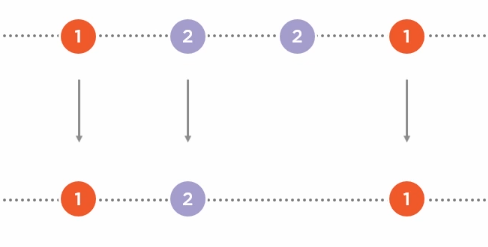
.DistinctUntilChanged():
过滤头尾元素:
.Take(2) .Skip(2):
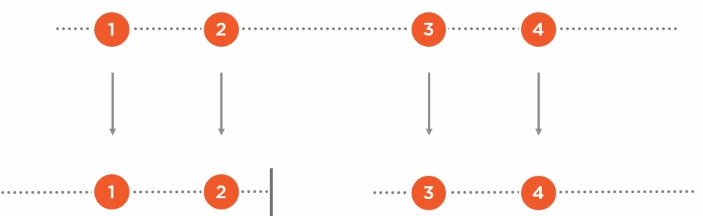
.SkipLast(2) .TakeLast(2):
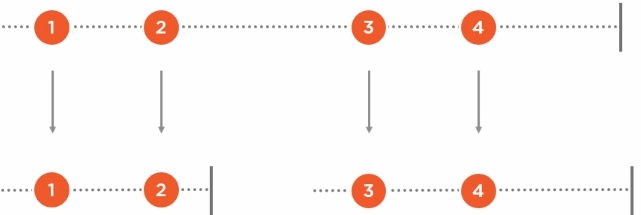
序列的阀:
a.TakeUnit(b)l a.SkipUntil(b):
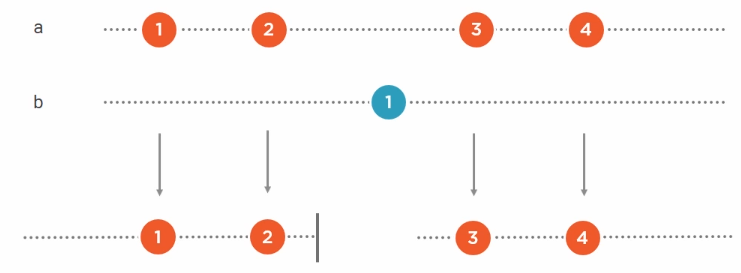
实际例子: 把鼠标移动和点击转化为拖拽:
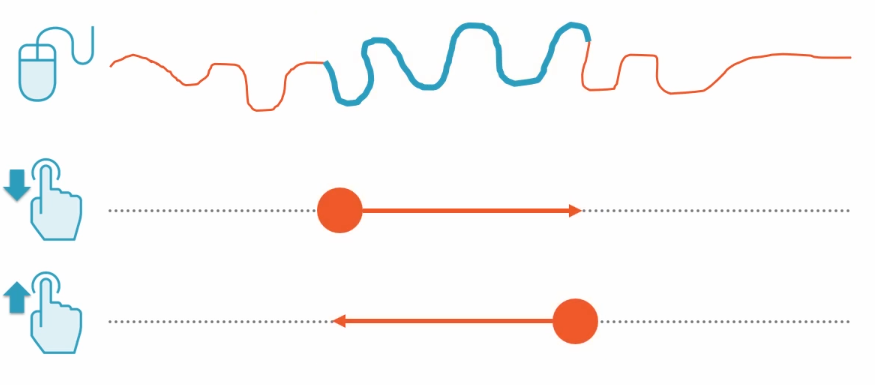
代码非常的简单:
var mouseDrags = mouseMoves.SkipUntil(mouseDowns).TakeUnit(mouseUps);
合并
a.Merge(b)
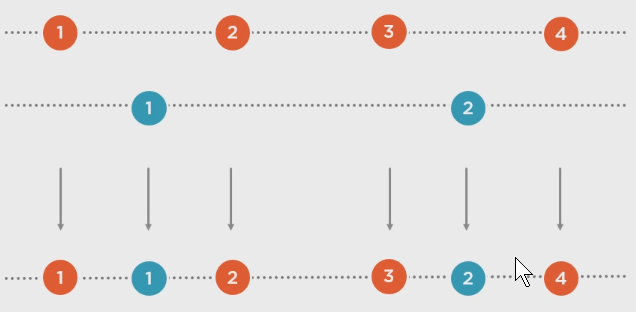
a.Amb(b), 其中的amb是ambiguous的缩写:
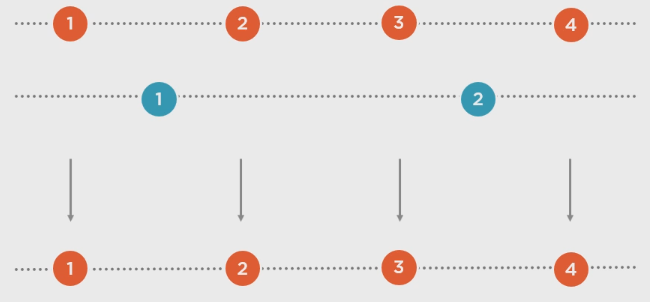
a.Concat(b):
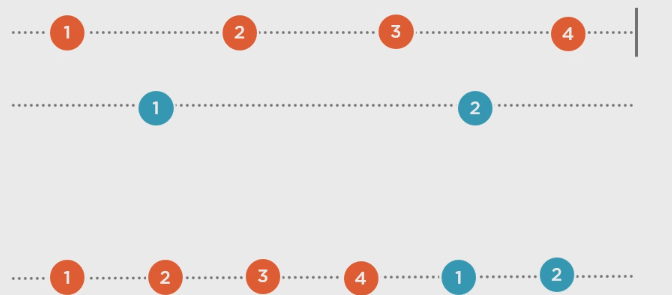
为序列配对:
a.CombineLatest(b, (x, y) => x + y):
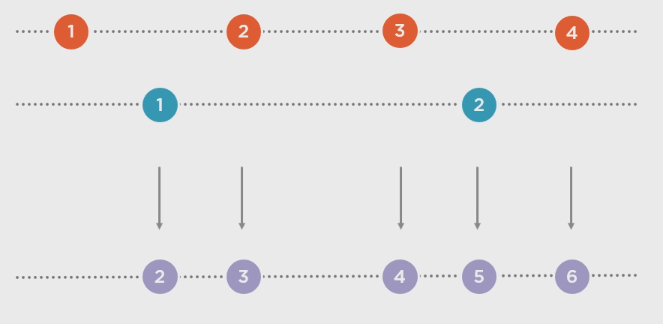
a.Zip(b, (x, y) => x + y):
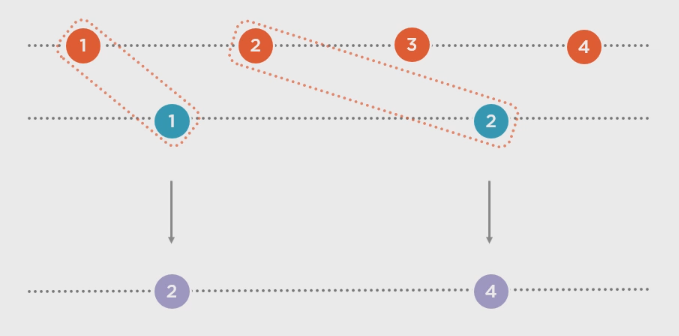
序列的序列:
Merge()是可以达到这种效果的:
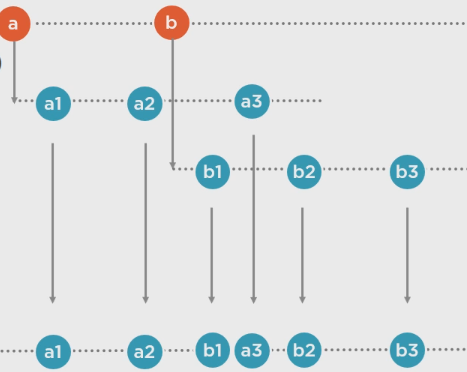
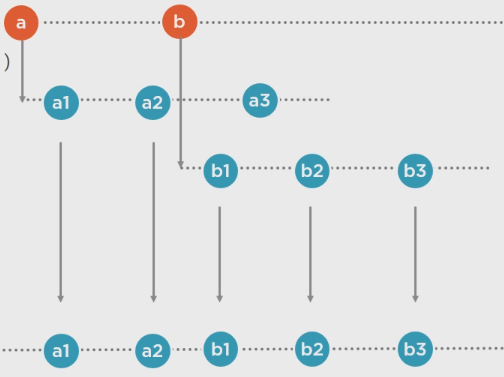
.Switch():
聚合
聚合就是指把序列聚合成一个值, 在序列结束后才能返回值
Count() Sum():

Aggregate():

Scan():
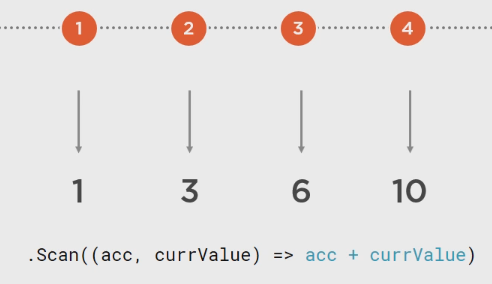
其他工具操作符
会有一些副作用
.Do(x => Log(x)): 但是记住不要改变序列的元素
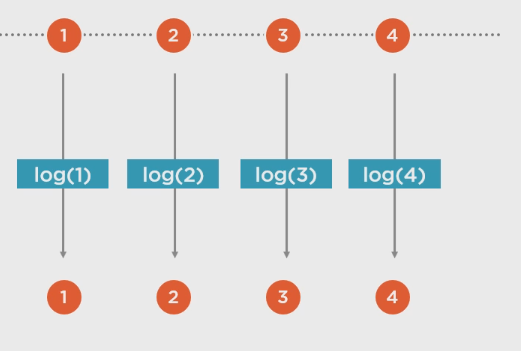
.TimeStamp():
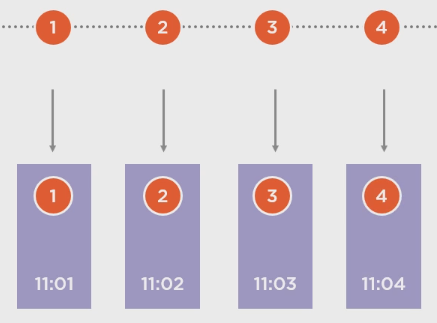
.Throttle(TimeSpan.FromSeconds(1)):
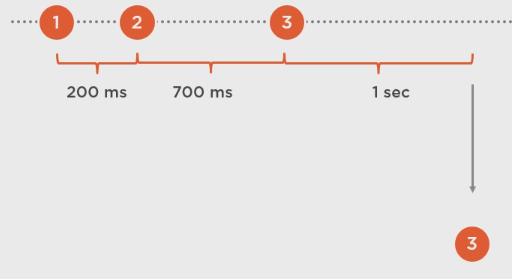
异步和多线程
异步就表示不一定按顺序执行, 但是它可以保证非阻塞, 通常会有回调函数(或者委托或者async await).
但是异步对于Rx来说就是它的本性
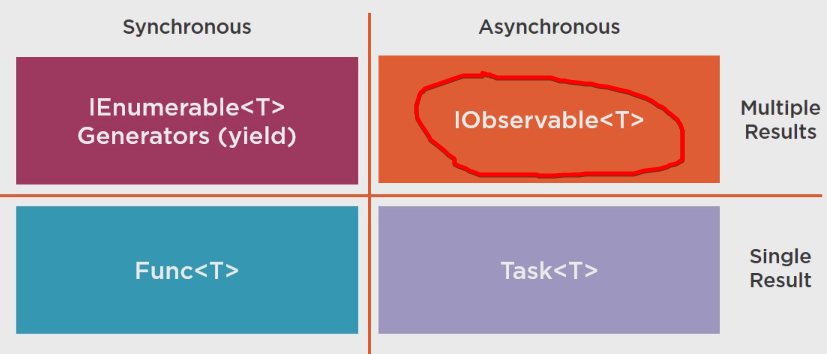
Rx的同步异步对比:
多线程
Rx不是多线程的, 但是它是线程自由的(就是可以使用多个线程), 它被设计成只是用必须的线程而已.
多线程表示, 同时有多个线程在执行. 也可以称作并发. 它可以分担计算量. 但是据需要考虑线程安全了.
Rx已经做了一些抽象, 所以不必过多的考虑线程安全了.
例如:
Observable.Interval(TimeSpan.FromSeconds(1)).Subscribe(xxx):

UI的例子:
Observable.Interval(TimeSpan.FromSeconds(1)).ObserveOn(SynchronizationContext.Current).Subscribe(t => searchBox.Text = t.ToString()):
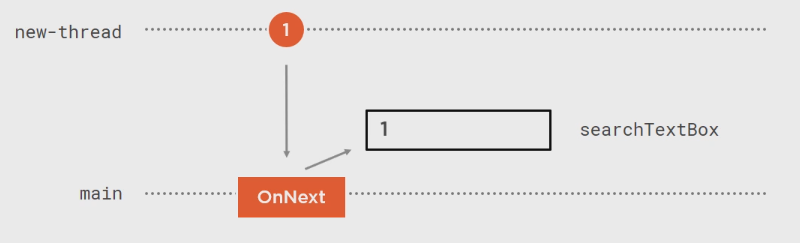
如果计算量比较大的话:
Observable.Create(大量工作).Subscribe(xxx):
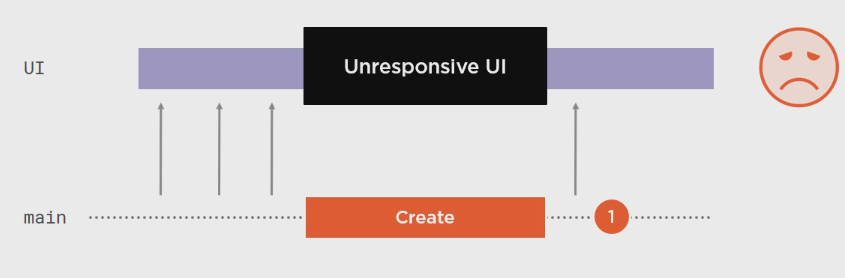
UI假死, 这就不好了.
应该这样:
Observable.Create(大量工作).SubscribeOn(NewThreadScheduler.Default).ObserveOn(SynchronizationContext.Current).Subscribe(xxx):
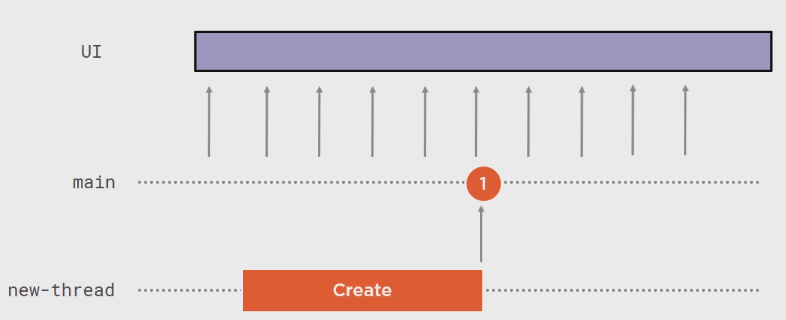
Schedulers
Scheduler可以在Rx里面安排执行动作. 它使用IScheduler接口.
现在就可以把Scheduler理解为是对未来执行的一个抽象.
它同时也负责着Rx所有的并发工作.
Rx提供了很多Scheduler.
下面是.net现有有很多种在未来执行动作的方法:
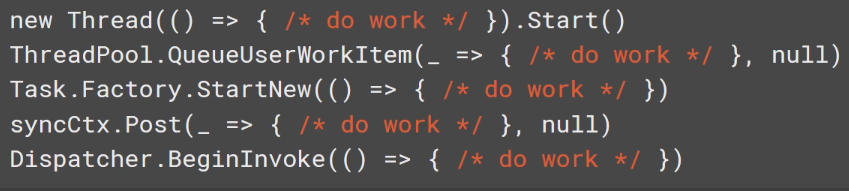
Rx里面就这个:
IScheduler接口:
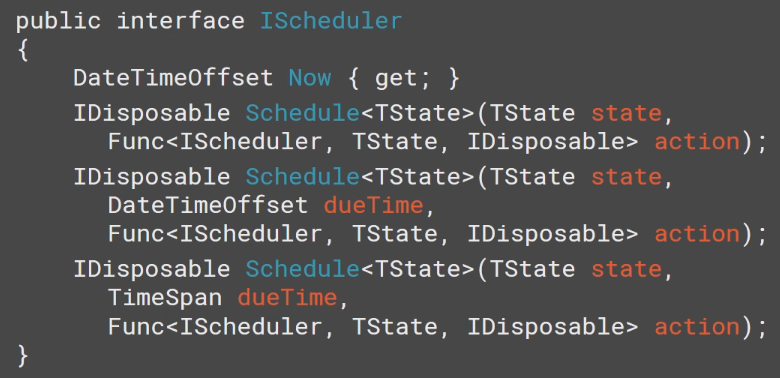
基本上不用直接去使用IScheduler, 因为内置了很多现成的Schedulers了:
- Immediate, 这是唯一一个不是异步的Scheduler
- CurrentThread
- EventLoop
- Dispatcher
- NewThread
- TaskPool, ThreadPool
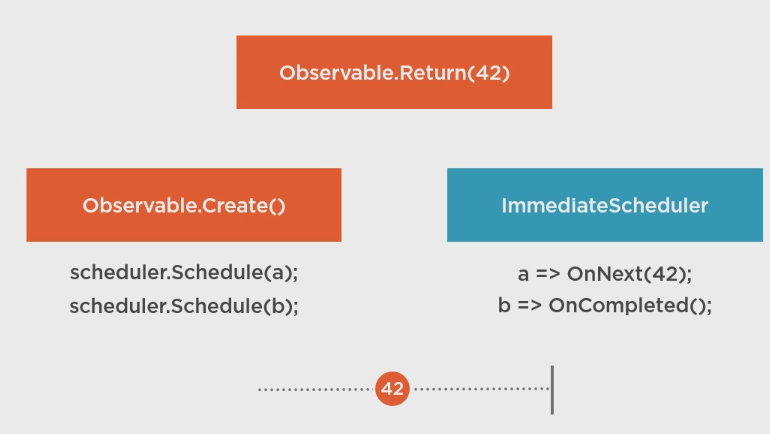
Schedulers实际上到处都使用着:
应该用哪个Scheduler?

Fake Scheduler:
用于测试
最新文章
- 如何使用其他文件中定义的类Python
- 【C#】C# 队列,
- 前端 js 实现简单 表单提交
- 关于apache做301的问题
- JAVA基础知识之Annotation
- leancloud 手机注册用户(调用API) 教程
- bzoj 1503 splay
- C#利用POST实现杭电oj的AC自动机器人,AC率高达50%~~
- 使用 as 和 is 运算符安全地进行强制转换
- library cache lock
- Typecho 代码阅读笔记(三) - 插件机制
- Tomcat 开启Gzip压缩
- IDEA远程连接Hadoop
- 关于mysql文件导入提示“Variable @OLD_CHARACTER_SET_CLIENT can't be set to the value of @@CHARACTER_SET_CLIENT”问题分析
- 我的grunt学习笔记
- Python2.7-weakref
- Java基础-进制转换
- RabbitMQ消息交换模式简介
- Java中如何实现类似C++结构体的二级排序
- 【DB2数据库在windows平台上的安装】