Kinect 开发 —— 语音识别(下)
使用定向麦克风进行波束追踪 (Beam Tracking for a Directional Microphone)
可以使用这4个麦克风来模拟定向麦克风产生的效果,这个过程称之为波束追踪(beam tracking)
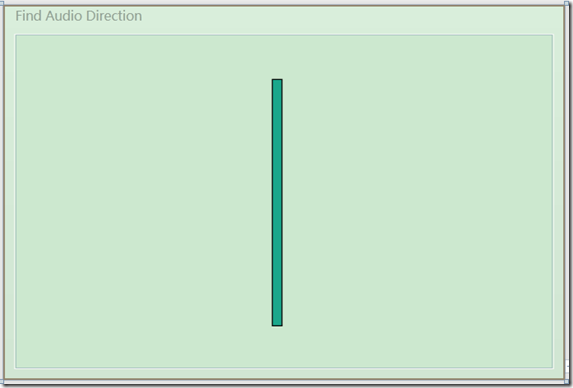
界面上的细长矩形用来指示某一时刻探测到的说话者的语音方向。矩形有一个旋转变换,在垂直轴上左右摆动,以表示声音的不同来源方向。
<Rectangle Fill="#1BA78B" HorizontalAlignment="Left" Margin="240,41,0,39" Stroke="Black" Width="" RenderTransformOrigin="0.5,0">
<Rectangle.RenderTransform>
<TransformGroup>
<ScaleTransform/>
<SkewTransform/>
<RotateTransform Angle="{Binding BeamAngle}"/>
<TranslateTransform/>
</TransformGroup>
</Rectangle.RenderTransform>
</Rectangle>
上图是程序的UI界面。后台逻辑代码和之前的例子大部分都是相同的。首先实例化一个KinectAudioSource对象,然后将主窗体的DataContext赋值给本身。将BeamAngleMode设置为Adaptive,使得能够自动追踪说话者的声音。我们需要编写KinectAudioSource对象的BeamChanged事件对应的处理方法。当用户的说话时,位置发生变化时就会触发该事件。我们需要创建一个名为BeamAngle的属性,使得矩形的RotateTransform可以绑定这个属性。
public partial class MainWindow : Window, INotifyPropertyChanged
{
public MainWindow()
{
InitializeComponent();
this.DataContext = this;
this.Loaded += delegate { ListenForBeamChanges(); };
} private KinectAudioSource CreateAudioSource()
{
var source = KinectSensor.KinectSensors[].AudioSource;
source.NoiseSuppression = true;
source.AutomaticGainControlEnabled = true;
source.BeamAngleMode = BeamAngleMode.Adaptive;
return source;
} private void ListenForBeamChanges()
{
KinectSensor.KinectSensors[].Start();
var audioSource = CreateAudioSource();
audioSource.BeamAngleChanged += audioSource_BeamAngleChanged;
audioSource.Start();
} public event PropertyChangedEventHandler PropertyChanged; private void OnPropertyChanged(string propName)
{
if (PropertyChanged != null)
PropertyChanged(this, new PropertyChangedEventArgs(propName));
} private double _beamAngle;
public double BeamAngle
{
get { return _beamAngle; }
set
{
_beamAngle = value;
OnPropertyChanged("BeamAngle");
}
}
}以上代码中,还需要对BeamChanged事件编写对应的处理方法。每次当波束的方向发生改变时,就更改BeamAngle的属性。SDK中使用弧度表示角度。所以在事件处理方法中我们需要将弧度换成度。为了能达到说话者移到左边,矩形条也能够向左边移动的效果,我们需要将角度乘以一个 –1
void audioSource_BeamAngleChanged(object sender, BeamAngleChangedEventArgs e)
{
BeamAngle = - * e.Angle;
}
语音命令识别
结合KinectAudioSource和SpeechRecognitionEngine来演示语音命令识别的强大功能。为了展示语音命令能够和骨骼追踪高效结合,我们会使用语音命令向窗体上绘制图形,并使用命令移动这些图形到光标的位置
CrossHair用户控件简单的以十字光标形式显示当前用户右手的位置。下面的代码显示了这个自定义控件的XAML文件。注意到对象于容器有一定的偏移使得十字光标的中心能够处于Grid的零点。
自定义控件 CrossHairs
CrossHair用户控件简单的以十字光标形式显示当前用户右手的位置。下面的代码显示了这个自定义控件的XAML文件。注意到对象于容器有一定的偏移使得十字光标的中心能够处于Grid的零点。
<Grid Height="50" Width="50" RenderTransformOrigin="0.5,0.5">
<Grid.RenderTransform>
<TransformGroup>
<ScaleTransform/>
<SkewTransform/>
<RotateTransform/>
<TranslateTransform X="-25" Y="-25"/>
</TransformGroup>
</Grid.RenderTransform>
<Rectangle Fill="#FFF4F4F5" Margin="22,0,20,0" Stroke="#FFF4F4F5"/>
<Rectangle Fill="#FFF4F4F5" Margin="0,22,0,21" Stroke="#FFF4F4F5"/>
</Grid>
在应用程序的主窗体中,将根节点从 grid 对象改为 canvas对象。Canvas对象使得将十字光标使用动画滑动到手的位置比较容易。在主窗体上添加一个CrossHairs自定义控件。在下面的代码中,我们可以看到将Canvas对象嵌套在了一个Viewbox控件中。这是一个比较老的处理不同屏幕分辨率的技巧。ViewBox控件会自动的将内容进行缩放以适应实际屏幕的大小。设置MainWindows的背景色,并将Canvas的颜色设置为黑色。然后在Canvas的底部添加两个标签。一个标签用来显示SpeechRecognitionEngine将要处理的语音指令,另一个标签显示匹配正确的置信度。CrossHair自定义控件绑定了HandTop和HandLeft属性。两个标签分别绑定了HypothesizedText和Confidence属性。
<Window x:Class="KinectPutThatThere.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:local="clr-namespace:KinectPutThatThere"
Title="Put That There" Background="Black">
<Viewbox>
<Canvas x:Name="MainStage" Height="1080" Width="1920" Background="Black" VerticalAlignment="Bottom">
<local:CrossHairs Canvas.Top="{Binding HandTop}" Canvas.Left="{Binding HandLeft}" />
<Label Foreground="White" Content="{Binding HypothesizedText}" Height="55" FontSize="32" Width="965" Canvas.Left="115" Canvas.Top="1025" />
<Label Foreground="Green" Content="{Binding Confidence}" Height="55" Width="114" FontSize="32" Canvas.Left="0" Canvas.Top="1025" />
</Canvas>
</Viewbox>
</Window>
在后台逻辑代码中,让MainWindows对象实现INofityPropertyChanged事件并添加OnPropertyChanged帮助方法。我们将创建4个属性用来为前台UI界面进行绑定。
public partial class MainWindow : Window, INotifyPropertyChanged
{
private double _handLeft;
public double HandLeft
{
get { return _handLeft; }
set
{
_handLeft = value;
OnPropertyChanged("HandLeft");
} } private double _handTop;
public double HandTop
{
get { return _handTop; }
set
{
_handTop = value;
OnPropertyChanged("HandTop");
}
} private string _hypothesizedText;
public string HypothesizedText
{
get { return _hypothesizedText; }
set
{
_hypothesizedText = value;
OnPropertyChanged("HypothesizedText");
}
} private string _confidence;
public string Confidence
{
get { return _confidence; }
set
{
_confidence = value;
OnPropertyChanged("Confidence");
}
} public event PropertyChangedEventHandler PropertyChanged; private void OnPropertyChanged(string propertyName)
{
if (PropertyChanged != null)
{
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
} }
}
添加CreateAudioSource方法,在该方法中,将KinectAudioSource对象的AutoGainControlEnabled的属性设置为false。
private KinectAudioSource CreateAudioSource()
{
var source = KinectSensor.KinectSensors[].AudioSource;
source.AutomaticGainControlEnabled = false;
source.EchoCancellationMode = EchoCancellationMode.None;
return source;
}
接下来实现骨骼追踪部分逻辑来获取右手的坐标,相信看完骨骼追踪那两篇文章后这部分的代码应该会比较熟悉。首先创建一个私有字段_kinectSensor来保存当前的KienctSensor对象,同时创建SpeechRecognitionEngine对象。在窗体的构造函数中,对这几个变量进行初始化。例外注册骨骼追踪系统的Skeleton事件并将主窗体的DataContext对象赋给自己。
KinectSensor _kinectSensor;
SpeechRecognitionEngine _sre;
KinectAudioSource _source; public MainWindow()
{
InitializeComponent();
this.DataContext = this;
this.Unloaded += delegate
{
_kinectSensor.SkeletonStream.Disable();
_sre.RecognizeAsyncCancel();
_sre.RecognizeAsyncStop();
_sre.Dispose();
};
this.Loaded += delegate
{
_kinectSensor = KinectSensor.KinectSensors[];
_kinectSensor.SkeletonStream.Enable(new TransformSmoothParameters()
{
Correction = 0.5f,
JitterRadius = 0.05f,
MaxDeviationRadius = 0.04f,
Smoothing = 0.5f
});
_kinectSensor.SkeletonFrameReady += nui_SkeletonFrameReady;
_kinectSensor.Start();
StartSpeechRecognition();
};
}
在上面的代码中,我们添加了一些TransformSmoothParameters参数来使得骨骼追踪更加平滑。nui_SkeletonFrameReady方法如下。方式使用骨骼追踪数据来获取我们感兴趣的右手的关节点位置。这部分代码和之前文章中的类似。大致流程是:遍历当前处在追踪状态下的骨骼信息。然后找到右手关节点的矢量信息,然后使用SkeletonToDepthImage来获取相对于屏幕尺寸的X,Y坐标信息。
void nui_SkeletonFrameReady(object sender, SkeletonFrameReadyEventArgs e)
{
using (SkeletonFrame skeletonFrame = e.OpenSkeletonFrame())
{
if (skeletonFrame == null)
return; var skeletons = new Skeleton[skeletonFrame.SkeletonArrayLength];
skeletonFrame.CopySkeletonDataTo(skeletons);
foreach (Skeleton skeletonData in skeletons)
{
if (skeletonData.TrackingState == SkeletonTrackingState.Tracked)
{
Microsoft.Kinect.SkeletonPoint rightHandVec = skeletonData.Joints[JointType.HandRight].Position;
var depthPoint = _kinectSensor.MapSkeletonPointToDepth(rightHandVec
, DepthImageFormat.Resolution640x480Fps30);
HandTop = depthPoint.Y * this.MainStage.ActualHeight / ;
HandLeft = depthPoint.X * this.MainStage.ActualWidth / ;
}
}
}
}
接下来我们需要实现语音识别部分的逻辑。SpeechRecognitionEngine中的StartSpeechRecognition方法必须找到正确的语音识别库来进行语音识别。下面的代码展示了如何设置语音识别库预计如何将KinectAudioSource传递给语音识别引起。我们还添加了SpeechRecognized,SpeechHypothesized以及SpeechRejected事件对应的方法。SetInputToAudioStream中的参数和前篇文章中的含义一样,这里不多解释了。注意到SpeechRecognitionEngine和KinectAudioSource都是Disposable类型,因此在整个应用程序的周期内,我们要保证这两个对象都处于打开状态。
private void StartSpeechRecognition()
{
_source = CreateAudioSource(); Func<RecognizerInfo, bool> matchingFunc = r =>
{
string value;
r.AdditionalInfo.TryGetValue("Kinect", out value);
return "True".Equals(value, StringComparison.InvariantCultureIgnoreCase)
&& "en-US".Equals(r.Culture.Name, StringComparison.InvariantCultureIgnoreCase);
};
RecognizerInfo ri = SpeechRecognitionEngine.InstalledRecognizers().Where(matchingFunc).FirstOrDefault(); _sre = new SpeechRecognitionEngine(ri.Id);
CreateGrammars(ri);
_sre.SpeechRecognized += sre_SpeechRecognized;
_sre.SpeechHypothesized += sre_SpeechHypothesized;
_sre.SpeechRecognitionRejected += sre_SpeechRecognitionRejected; Stream s = _source.Start();
_sre.SetInputToAudioStream(s,
new SpeechAudioFormatInfo(
EncodingFormat.Pcm, , , ,
, , null));
_sre.RecognizeAsync(RecognizeMode.Multiple);
}
要完成程序逻辑部分,我们还需要处理语音识别时间以及语音逻辑部分,以使得引擎能够直到如何处理和执行我们的语音命令。SpeechHypothesized以及SpeechRejected事件代码如下,这两个事件的逻辑很简单,就是更新UI界面上的label。SpeechRecognized事件有点复杂,他负责处理传进去的语音指令,并对识别出的指令执行相应的操作。另外,该事件还负责创建一些GUI对象(实际就是命令模式),我们必须使用Dispatcher对象来发挥InterpretCommand到主UI线程中来。
void sre_SpeechRecognitionRejected(object sender, SpeechRecognitionRejectedEventArgs e)
{
HypothesizedText += " Rejected";
Confidence = Math.Round(e.Result.Confidence, ).ToString();
} void sre_SpeechHypothesized(object sender, SpeechHypothesizedEventArgs e)
{
HypothesizedText = e.Result.Text;
} void sre_SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
Dispatcher.BeginInvoke(new Action<SpeechRecognizedEventArgs>(InterpretCommand), e);
}
现在到了程序核心的地方。创建语法逻辑并对其进行解析。本例中的程序识别普通的以“put”或者“create”开头的命令。前面是什么我们不关心,紧接着应该是一个颜色,然后是一种形状,最后一个词应该是“there”。下面的代码显示了创建的语法。
private void CreateGrammars(RecognizerInfo ri)
{
var colors = new Choices();
colors.Add("cyan");
colors.Add("yellow");
colors.Add("magenta");
colors.Add("blue");
colors.Add("green");
colors.Add("red"); var create = new Choices();
create.Add("create");
create.Add("put"); var shapes = new Choices();
shapes.Add("circle");
shapes.Add("triangle");
shapes.Add("square");
shapes.Add("diamond"); var gb = new GrammarBuilder();
gb.Culture = ri.Culture;
gb.Append(create);
gb.AppendWildcard();
gb.Append(colors);
gb.Append(shapes);
gb.Append("there"); var g = new Grammar(gb);
_sre.LoadGrammar(g); var q = new GrammarBuilder{ Culture = ri.Culture };
q.Append("quit application");
var quit = new Grammar(q); _sre.LoadGrammar(quit);
}上面的代码中,我们首先创建一个Choices对象,这个对象会在命令解析中用到。在程序中我们需要颜色和形状对象。另外,第一个单词是“put”或者“create”,因此我们也创建Choices对象。然后使用GrammarBuilder类将这些对象组合到一起。首先是”put”或者“create”然后是一个占位符,因为我们不关心内容,然后是一个颜色Choices对象,然后是一个形状Choices对象,最后是一个“there”单词。
我们将这些语法规则加载进语音识别引擎。同时我们也需要有一个命令来停止语音识别引擎。因此我们创建了第二个语法对象,这个对象只有一个”Quit”命令。然后也将这个语法规则加载到引擎中。
一旦识别引擎确定了要识别的语法,真正的识别工作就开始了。被识别的句子必须被解译,出别出来想要的指令后,我们必须决定如何进行下一步处理。下面的代码展示了如何处理识别出的命令,以及如何根据特定的指令来讲图形元素绘制到UI界面上去。
private void InterpretCommand(SpeechRecognizedEventArgs e)
{
var result = e.Result;
Confidence = Math.Round(result.Confidence, ).ToString();
if (result.Confidence < && result.Words[].Text == "quit" && result.Words[].Text == "application")
{
this.Close();
}
if (result.Words[].Text == "put" || result.Words[].Text == "create")
{
var colorString = result.Words[].Text;
Color color;
switch (colorString)
{
case "cyan": color = Colors.Cyan;
break;
case "yellow": color = Colors.Yellow;
break;
case "magenta": color = Colors.Magenta;
break;
case "blue": color = Colors.Blue;
break;
case "green": color = Colors.Green;
break;
case "red": color = Colors.Red;
break;
default:
return;
} var shapeString = result.Words[].Text;
Shape shape;
switch (shapeString)
{
case "circle":
shape = new Ellipse();
shape.Width = ;
shape.Height = ;
break;
case "square":
shape = new Rectangle();
shape.Width = ;
shape.Height = ;
break;
case "triangle":
var poly = new Polygon();
poly.Points.Add(new Point(, ));
poly.Points.Add(new Point(, ));
poly.Points.Add(new Point(, -));
shape = poly;
break;
case "diamond":
var poly2 = new Polygon();
poly2.Points.Add(new Point(, ));
poly2.Points.Add(new Point(, ));
poly2.Points.Add(new Point(, ));
poly2.Points.Add(new Point(, -));
shape = poly2;
break;
default:
return;
}
shape.SetValue(Canvas.LeftProperty, HandLeft);
shape.SetValue(Canvas.TopProperty, HandTop);
shape.Fill = new SolidColorBrush(color);
MainStage.Children.Add(shape);
}
}
方法中,我们首先检查语句识别出的单词是否是”Quit”如果是的,紧接着判断第二个单词是不是”application”如果两个条件都满足了,就不进行绘制图形,直接返回。如果有一个条件不满足,就继续执行下一步。
InterpretCommand方法然后判断第一个单词是否是“create”或者“put”,如果不是这两个单词开头就什么也不执行。如果是的,就判断第三个单词,并根据识别出来的颜色创建对象。如果第三个单词没有正确识别,应用程序也停止处理。否则,程序判断第四个单词,根据接收到的命令创建对应的形状。到这一步,基本的逻辑已经完成,最后第五个单词用来确定整个命令是否正确。命令处理完了之后,将当前受的X,Y坐标赋给创建好的对象的位置。
namespace KinectPutThatThere
{
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window, INotifyPropertyChanged
{
KinectSensor _kinectSensor;
SpeechRecognitionEngine _sre;
KinectAudioSource _source; public MainWindow()
{
InitializeComponent();
this.DataContext = this;
this.Unloaded += delegate
{
_kinectSensor.SkeletonStream.Disable();
_sre.RecognizeAsyncCancel();
_sre.RecognizeAsyncStop();
//_source.Dispose();
_sre.Dispose();
};
this.Loaded += delegate
{
_kinectSensor = KinectSensor.KinectSensors[];
_kinectSensor.SkeletonStream.Enable(new TransformSmoothParameters() // 对骨骼数据进行平滑处理
{
// This struct is used to setup the skeleton smoothing values
Correction = 0.5f,
JitterRadius = 0.05f,
MaxDeviationRadius = 0.04f,
Smoothing = 0.5f
});
_kinectSensor.SkeletonFrameReady += nui_SkeletonFrameReady;
_kinectSensor.Start();
StartSpeechRecognition();
};
} #region 骨骼数据处理 void nui_SkeletonFrameReady(object sender, SkeletonFrameReadyEventArgs e)
{
using (SkeletonFrame skeletonFrame = e.OpenSkeletonFrame())
{
if (skeletonFrame == null)
return; var skeletons = new Skeleton[skeletonFrame.SkeletonArrayLength]; // 不定类型 —— Skeleton
skeletonFrame.CopySkeletonDataTo(skeletons);
foreach (Skeleton skeletonData in skeletons)
{
if (skeletonData.TrackingState == SkeletonTrackingState.Tracked)
{
Microsoft.Kinect.SkeletonPoint rightHandVec = skeletonData.Joints[JointType.HandRight].Position;
var depthPoint = _kinectSensor.MapSkeletonPointToDepth(rightHandVec
, DepthImageFormat.Resolution640x480Fps30);
HandTop = depthPoint.Y * this.MainStage.ActualHeight / ;
HandLeft = depthPoint.X * this.MainStage.ActualWidth / ;
}
}
}
}
#endregion private KinectAudioSource CreateAudioSource()
{
var source = KinectSensor.KinectSensors[].AudioSource;
source.AutomaticGainControlEnabled = false;
source.EchoCancellationMode = EchoCancellationMode.None;
return source;
} private void StartSpeechRecognition()
{
_source = CreateAudioSource(); Func<RecognizerInfo, bool> matchingFunc = r =>
{
string value;
r.AdditionalInfo.TryGetValue("Kinect", out value);
return "True".Equals(value, StringComparison.InvariantCultureIgnoreCase)
&& "en-US".Equals(r.Culture.Name, StringComparison.InvariantCultureIgnoreCase);
};
// 识别库 RecognizerInfo ri = SpeechRecognitionEngine.InstalledRecognizers().Where(matchingFunc).FirstOrDefault(); _sre = new SpeechRecognitionEngine(ri.Id); // 需要设置识别引擎的ID编号
CreateGrammars(ri);
_sre.SpeechRecognized += sre_SpeechRecognized;
_sre.SpeechHypothesized += sre_SpeechHypothesized;
_sre.SpeechRecognitionRejected += sre_SpeechRecognitionRejected; Stream s = _source.Start();
_sre.SetInputToAudioStream(s,
new SpeechAudioFormatInfo(
EncodingFormat.Pcm, , , ,
, , null));
_sre.RecognizeAsync(RecognizeMode.Multiple);
} private void CreateGrammars(RecognizerInfo ri)
{
// 创建语法 var colors = new Choices(); // 通配符 —— 择类(Choices)是通配符类(Wildcard)的一种,它可以包含多个值。但与通配符不同的是,我们可以指定可接受的值的顺序。
colors.Add("cyan");
colors.Add("yellow");
colors.Add("magenta");
colors.Add("blue");
colors.Add("green");
colors.Add("red"); var create = new Choices();
create.Add("create");
create.Add("put"); var shapes = new Choices();
shapes.Add("circle");
shapes.Add("triangle");
shapes.Add("square");
shapes.Add("diamond"); var gb = new GrammarBuilder();
gb.Culture = ri.Culture;
gb.Append(create);
gb.AppendWildcard();
gb.Append(colors);
gb.Append(shapes);
gb.Append("there"); var g = new Grammar(gb);
_sre.LoadGrammar(g); var q = new GrammarBuilder { Culture = ri.Culture };
q.Append("quit application");
var quit = new Grammar(q); _sre.LoadGrammar(quit);
} #region 语音事件处理 void sre_SpeechRecognitionRejected(object sender, SpeechRecognitionRejectedEventArgs e)
{
HypothesizedText += " Rejected";
Confidence = Math.Round(e.Result.Confidence, ).ToString();
} void sre_SpeechHypothesized(object sender, SpeechHypothesizedEventArgs e)
{
HypothesizedText = e.Result.Text;
} void sre_SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
Dispatcher.BeginInvoke(new Action<SpeechRecognizedEventArgs>(InterpretCommand), e);
} #endregion
private void InterpretCommand(SpeechRecognizedEventArgs e)
{
var result = e.Result;
Confidence = Math.Round(result.Confidence, ).ToString();
if (result.Confidence < && result.Words[].Text == "quit" && result.Words[].Text == "application")
{
this.Close();
}
if (result.Words[].Text == "put" || result.Words[].Text == "create")
{
var colorString = result.Words[].Text;
Color color;
switch (colorString)
{
case "cyan": color = Colors.Cyan;
break;
case "yellow": color = Colors.Yellow;
break;
case "magenta": color = Colors.Magenta;
break;
case "blue": color = Colors.Blue;
break;
case "green": color = Colors.Green;
break;
case "red": color = Colors.Red;
break;
default:
return;
} var shapeString = result.Words[].Text;
Shape shape;
switch (shapeString)
{
case "circle":
shape = new Ellipse();
shape.Width = ;
shape.Height = ;
break;
case "square":
shape = new Rectangle();
shape.Width = ;
shape.Height = ;
break;
case "triangle":
var poly = new Polygon();
poly.Points.Add(new Point(, ));
poly.Points.Add(new Point(, ));
poly.Points.Add(new Point(, -));
shape = poly;
break;
case "diamond":
var poly2 = new Polygon();
poly2.Points.Add(new Point(, ));
poly2.Points.Add(new Point(, ));
poly2.Points.Add(new Point(, ));
poly2.Points.Add(new Point(, -));
shape = poly2;
break;
default:
return;
}
shape.SetValue(Canvas.LeftProperty, HandLeft);
shape.SetValue(Canvas.TopProperty, HandTop);
shape.Fill = new SolidColorBrush(color);
MainStage.Children.Add(shape);
}
} #region 前台控件的绑定 private double _handLeft;
public double HandLeft
{
get { return _handLeft; }
set
{
_handLeft = value;
OnPropertyChanged("HandLeft");
} } private double _handTop;
public double HandTop
{
get { return _handTop; }
set
{
_handTop = value;
OnPropertyChanged("HandTop"); // 驱动控件
}
} private string _hypothesizedText;
public string HypothesizedText
{
get { return _hypothesizedText; }
set
{
_hypothesizedText = value;
OnPropertyChanged("HypothesizedText");
}
} private string _confidence;
public string Confidence
{
get { return _confidence; }
set
{
_confidence = value;
OnPropertyChanged("Confidence");
}
} public event PropertyChangedEventHandler PropertyChanged; private void OnPropertyChanged(string propertyName)
{
if (PropertyChanged != null)
{
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
} } #endregion
}
}
最新文章
- 在移动端中的flex布局
- 让自己也能使用Canvas
- 通过npm安装 Cordova
- 【转载】关于 Ubuntu 的小知识分享
- iterator与const_iterator及const iterator区别
- [转载]Nginx如何处理一个请求
- WP开发笔记——WP APP添加页面跳转动画
- 关于一次Weblogic活动线程的问题处理
- Android MediaCodec 使用例子
- 在ubuntu10.0.4下更新git
- Linux部署ASP.NET 5 (vNext)
- 微信浏览器安卓手机video浮在最上层问题
- ReactNative小笔记
- 成对使用new和delete,传值传引用
- MFC 消息框
- USBDM Coldfire V2,3,4/DSC/Kinetis Debugger and Programmer -- MC9S08JS16
- Linux学习之CentOS(五)----网卡的配置
- capistranorb
- (转)InnoDB存储引擎MVCC实现原理
- SQL Serever学习12——数据库的备份和还原