源码阅读之LinkedHashMap(JDK8)
概述
LinkedHashMap继承自HashMap,实现了Map<K,V>接口。其内部还维护了一个双向链表,在每次插入数据,或者访问、修改数据时,会增加节点、或调整链表的节点顺序。以决定迭代时输出的顺序。
默认情况,遍历时的顺序是按照插入节点的顺序。这也是其与HashMap最大的区别。
也可以在构造时传入accessOrder参数,使得其遍历顺序按照访问的顺序输出。
因继承自HashMap,所以除了输出无序,其他LinkedHashMap都有,比如扩容的策略,哈希桶长度一定是2的N次方等等。
LinkedHashMap在实现时,就是重写override了几个方法。以满足其输出序列有序的需求。
内部结构
LinkedHashMap的实现主要分两部分,一部分是哈希表,另外一部分是链表。
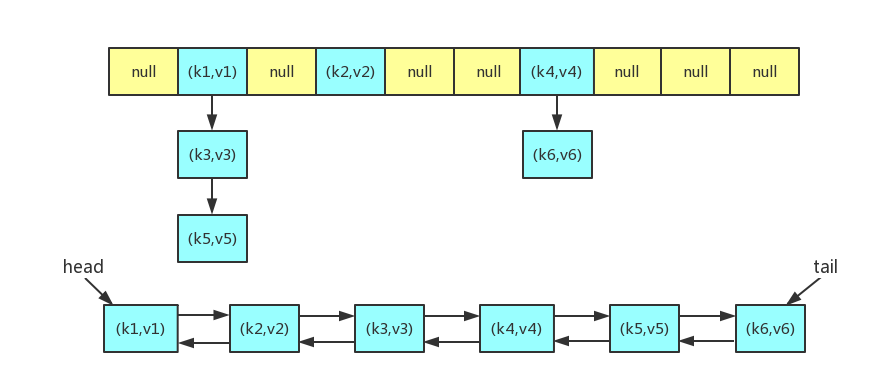
数据结构
//LinkedHashMap的链表节点继承了HashMap的节点,而且每个节点都包含了前指针和后指针,
//所以这里可以看出它是一个双向链表
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
} //双向链表的头指针
transient LinkedHashMap.Entry<K,V> head;
//双向链表的尾指针
transient LinkedHashMap.Entry<K,V> tail;
//默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序。
//为true时,可以在这基础之上构建一个LruCach
final boolean accessOrder;
构造函数
//指定初始化时的容量,和扩容的加载因子
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
//指定初始化时的容量
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
} public LinkedHashMap() {
super();
accessOrder = false;
} //利用另一个Map 来构建,
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
} //指定初始化时的容量,和扩容的加载因子,以及迭代输出节点的顺序
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
构造函数和HashMap相比,就是增加了一个accessOrder参数,用于控制迭代时的节点顺序,默认是false。
覆盖的方法
在HashMap中有三个模版方法,供子类来覆盖,在访问、插入、删除某个节点之后,进行一些特殊处理。
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
1. afterNodeAccess方法,会将当前被访问到的节点e,移动至内部的双向链表的尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;//原尾节点
//如果accessOrder 是true ,且原尾节点不等于e
if (accessOrder && (last = tail) != e) {
//节点e强转成双向链表节点p
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p现在是尾节点, 后置节点一定是null
p.after = null;
//如果p的前置节点是null,则p以前是头结点,所以更新现在的头结点是p的后置节点a
if (b == null)
head = a;
else//否则更新p的前直接点b的后置节点为 a
b.after = a;
//如果p的后置节点不是null,则更新后置节点a的前置节点为b
if (a != null)
a.before = b;
else//如果原本p的后置节点是null,则p就是尾节点。 此时 更新last的引用为 p的前置节点b
last = b;
if (last == null) //原本尾节点是null 则,链表中就一个节点
head = p;
else {//否则 更新 当前节点p的前置节点为 原尾节点last, last的后置节点是p
p.before = last;
last.after = p;
}
//尾节点的引用赋值成p
tail = p;
//修改modCount。
++modCount;
}
}
2.afterNodeInsertion方法,在哈希表中插入了一个新节点时调用的,它会把链表的头节点删除掉,删除的方式是通过调用HashMap的removeNode方法。
//回调函数,新节点插入之后回调 , 根据evict 和 判断是否需要删除最老插入的节点。如果实现LruCache会用到这个方法。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//LinkedHashMap 默认返回false 则不删除节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//LinkedHashMap 默认返回false 则不删除节点。 返回true 代表要删除最早的节点。通常构建一个LruCache会在达到Cache的上限是返回true
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
3.afterNodeRemoval方法,把在HashMap中删除的那个键值对一并从链表中删除,保证了哈希表和链表的一致性。
//在删除节点e时,同步将e从双向链表上删除
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//待删除节点 p 的前置后置节点都置空
p.before = p.after = null;
//如果前置节点是null,则现在的头结点应该是后置节点a
if (b == null)
head = a;
else//否则将前置节点b的后置节点指向a
b.after = a;
//同理如果后置节点时null ,则尾节点应是b
if (a == null)
tail = b;
else//否则更新后置节点a的前置节点为b
a.before = b;
}
添加元素
LinkedHashMap并没有重写任何put方法,但是其重写了构建新节点的newNode()方法,newNode()会在HashMap的putVal()方法里被调用。在每次构建新节点时,通过linkNodeLast(p),将新节点链接在内部双向链表的尾部。在putVal()里也调用了afterNodeInsertion方法
//在构建新节点时,构建的是`LinkedHashMap.Entry` 不再是`Node`.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//将新增的节点,连接在链表的尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//集合之前是空的
if (last == null)
head = p;
else {//将新节点连接在链表的尾部
p.before = last;
last.after = p;
}
}
删除元素
LinkedHashMap也没有重写remove()方法,因为它的删除逻辑和HashMap并无区别。 但它重写了afterNodeRemoval()这个回调方法,在remove方法里会调用这个afterNodeRemoval方法。
查询元素
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
对比HashMap中的实现,LinkedHashMap只是增加了在成员变量(构造函数时赋值)accessOrder为true的情况下,要去回调void afterNodeAccess(Node<K,V> e)函数。
遍历
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
} abstract class LinkedHashIterator {
//下一个节点
LinkedHashMap.Entry<K,V> next;
//当前节点
LinkedHashMap.Entry<K,V> current;
int expectedModCount; LinkedHashIterator() {
//初始化时,next 为 LinkedHashMap内部维护的双向链表的扁头
next = head;
//记录当前modCount,以满足fail-fast
expectedModCount = modCount;
//当前节点为null
current = null;
}
//判断是否还有next
public final boolean hasNext() {
//就是判断next是否为null,默认next是head 表头
return next != null;
}
//nextNode() 就是迭代器里的next()方法 。
//该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。
final LinkedHashMap.Entry<K,V> nextNode() {
//记录要返回的e。
LinkedHashMap.Entry<K,V> e = next;
//判断fail-fast
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
//如果要返回的节点是null,异常
if (e == null)
throw new NoSuchElementException();
//更新当前节点为e
current = e;
//更新下一个节点是e的后置节点
next = e.after;
//返回e
return e;
}
//删除方法 最终还是调用了HashMap的removeNode方法
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
示例
Map<String, String> map = new LinkedHashMap<>();
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("4", "d"); Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
} System.out.println("以下是accessOrder=true的情况:"); map = new LinkedHashMap<String, String>(10, 0.75f, true);
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("4", "d");
map.get("2");//2移动到了内部的链表末尾
map.get("4");//4调整至末尾
map.put("3", "e");//3调整至末尾
map.put(null, null);//插入两个新的节点 null
map.put("5", null);//
iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
结果:
1=a
2=b
3=c
4=d
以下是accessOrder=true的情况:
1=a
2=b
4=d
3=e
null=null
5=null
最新文章
- git init和git init -bare区别
- [CentOs7]安装mysql(2)
- You are note Hk
- iOS 集成银联支付
- Linux下PHP+MySQL+CoreSeek中文检索引擎配置
- SelectedValue,SelectedValuePath,SelectedValueBinding,DisplayMemberPath讲解
- Linux学习笔记29——IPC状态命令
- 简要介绍EF(实体框架)
- MFC属性页对话框
- Android 音视频开发(五):使用 MediaExtractor 和 MediaMuxer API 解析和封装 mp4 文件
- drf 教程
- spring-boot mybatis配置
- 使用C编程语言实现AVL树
- IP地址和子网划分学习笔记之《IP地址详解》
- quartz自定义线程数
- 微信小程序通过api接口将json数据展现到小程序示例
- 【转】移除HTML5 input在type="number"时的上下小箭头
- Requests库入门实例
- linux shell 正则表达式(BREs,EREs,PREs)差异比较(转)
- 浅谈javascript函数,变量声明及作用域