Python 常用算法记录
一、递归
汉诺塔算法:把A柱的盘子,移动到C柱上,最少需要移动几次,大盘子只能在小盘子下面
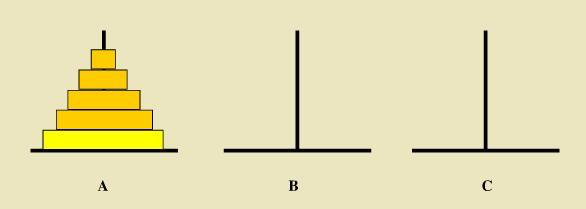
1、当盘子的个数为n时,移动的次数应等于2^n – 1
2、描述盘子从A到C:
(1)如果A只有一个圆盘,可以直接移动到C;
(2)如果A有N个圆盘,可以看成A有1个圆盘(底盘) + (N-1)个圆盘,首先需要把 (N-1) 个圆盘移动到 B,然后,将 A的最后一个圆盘移动到C,再将B的(N-1)个圆盘移动到C。
3、代码
i = 0 def move(n, a, b, c):
global i
if n == 1:
i += 1
print('移动第', i, '次', a, '-->', c)
else:
# 1.把A柱上n-1个圆盘移动到B柱上
move(n - 1, a, c, b)
# 2.把A柱上最大的移动到C柱子上
move(1, a, b, c)
# 3.把B柱子上n-1个圆盘移动到C柱子上
move(n - 1, b, a, c) move(4, 'A', 'B', 'C')
二、常用排序算法
1、冒泡排序 Bubble Sort
(1)两两比较,大元素往后排,类似水里的气泡从下面浮上来
(2)代码
def bubble_sort(alist):
"""冒泡排序"""
n = len(alist)
for j in range(n - 1):
count = 0
for i in range(0, n - 1 - j):
if alist[i] > alist[i + 1]:
alist[i], alist[i + 1] = alist[i + 1], alist[i]
count += 1
# count为0,表示数据本来就是有序的,无需多比较
if 0 == count:
return if __name__ == "__main__":
li = [8, 1, 5, 4, 3, 9, 0, 2, 7, 6]
bubble_sort(li)
print(li)
2、选择排序 Selection Sort
(1)设置一个标记位记录每一轮遍历后(内循环)最小数值的角标,在内循环一轮结束后,直接将标记位指向的元素,放到本轮遍历(内循环)的第一个位置。
(2)代码
def select_sort(alist):
"""选择排序"""
n = len(alist)
for j in range(n-1):
min_index = j # 这是标记位
for i in range(j+1, n):
if alist[min_index] > alist[i]:
min_index = i # 记录下最小的数值对应的角标
# 本轮内循环结束,本轮比较的数组的第一个元素为 alist[j]
alist[j], alist[min_index] = alist[min_index], alist[j] if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
select_sort(li)
print(li)
3、插入排序 Insertion Sort
(1)逐个取出元素(比如从第二个开始),和前面的每个元素比较,插入到合适的位置。这样,保证一轮比较后,取出元素位置的左边都是排序过的有序数据。
(2)代码
def insert_sort(alist):
"""插入排序"""
n = len(alist)
# 需要取出每一个元素和左边的逐个比较,j就是每个元素的角标,控制外循环
for j in range(1, n):
# j = [1, 2, 3, n-1]
# i 代表内层循环起始值,每一次外循环更新内循环的起始值
i = j
while i > 0 and alist[i] < alist[i-1]:
# 插入到前面的正确位置中,依然需要逐个比较、交换
alist[i], alist[i-1] = alist[i-1], alist[i]
i -= 1 if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
insert_sort(li)
print(li)
4、希尔排序 SHELL
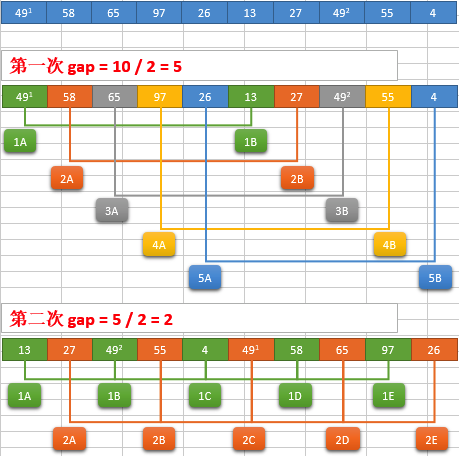
(1)选择一个步长(gap) ,然后按间隔gap取元素,放到一个组里,以此将这个数据分成多组。每个组采用插入排序处理数据。紧接着步长逐渐变小,循环前面操作,直至为1。
(2)简单图示:
(3)代码
def shell_sort(alist):
"""希尔排序"""
n = len(alist)
gap = n // 2
while gap > 0:
# 插入算法,与普通的插入算法的区别就是gap步长
for j in range(gap, n):
# j = [gap, gap+1, gap+2, gap+3, ..., n-1]
i = j while i > 0 and alist[i] < alist[i - gap]:
alist[i], alist[i - gap] = alist[i - gap], alist[i]
i -= gap # 缩短gap步长,不一定必须折半
gap //= 2 if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
shell_sort(li)
print(li)
5、快速排序 Quick Sort
(1)选择一个关键值,通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程递归进行。
(2)图示
<1> 详细拆解

<2> 代码中的low和high

(3)代码
def quick_sort(alist, first, last):
"""快速排序"""
if first < last: # 设置中间值,作为基数:最终比他小的元素放在左边,比他大的元素放在右边
# 此处就是取的第一个元素作为基数
mid_value = alist[first] # 设置高、低两个标记位
low,high = first,last # 每一次外循环完成的是:一次高、低位的交换(和中间值比较后)
while low < high: # Step1 high左移:如果高标记位所在的值大于等于中间值,则继续左移
while low < high and alist[high] >= mid_value:
high -= 1 # Step2 当高标记位的值小于中间值时:标记位不再移动,同时,将高标记位的值放到低标记位
alist[low] = alist[high] # Step3 low右移:如果低记位所在的值小于于中间值,则继续左移
# 注意:此处是没有等于mid_value的情况,目的是将同等大小情况的值,都放到一边,这是一种规范
while low < high and alist[low] < mid_value:
low += 1 # Step4 当低标记位的值大于中间值时:标记位不再移动,同时,将低标记位的值放到高标记位
alist[high] = alist[low] # 从循环退出时,low>=high,将中间值直接放到low位
# 此时,mid_value的左边都是比他小的,右边都是比他大的
alist[low] = mid_value # 递归一 :对中间值左边的列表执行快速排序
quick_sort(alist, first, low-1) # 递归二 :对中间值右边的列表排序
quick_sort(alist, low+1, last) return alist if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
quick_sort(li, 0, len(li)-1)
print(li)
6、归并排序
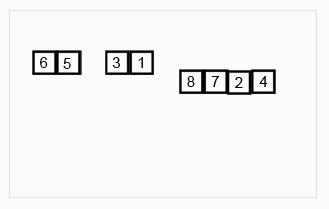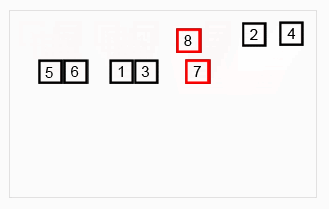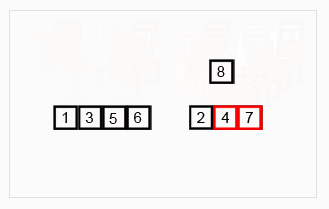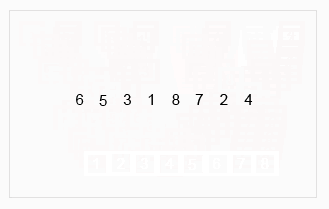
(1)先递归分解数组,子数组之间比较后合并成有序数组,新合并的子数组之间再递归比较,直到最终合并成唯一一个新的有序数组。
(2)步骤:先将原数组分解最小之后,然后合并两个有序数组(依次重新合并,成为最终唯一的有序数组)。其中,每次两个小分组比较时,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
(3)图示
(4)代码
def merge_sort(alist):
"""归并排序"""
n = len(alist) # 个数大于一时进行比较,否则直接返回
if n > 1: # ---------- 递归分解数组 ---------- # 每次采用折半的方式进行拆分,直到拆成一个元素的数组
mid = n//2 # left:左半部分,递归,采用归并排序后形成的有序的新的列表
left_li = merge_sort(alist[:mid]) # right:右半部分,递归,采用归并排序后形成的有序的新的列表
right_li = merge_sort(alist[mid:]) # ---------- 递归排序子序列并且合并 ---------- # 将两个有序的子序列合并为一个新的整体
# 左、右指针,用于依次取出左右两个数组的每个元素进行比较
left_pointer, right_pointer = 0, 0 # 存放合并后的有序数组
result = [] # 循环,直到穷尽左、右其中一个数组
while left_pointer < len(left_li) and right_pointer < len(right_li): # 比较左右子序列,把小的依次放到result里,并且正确的移动相应的指针
if left_li[left_pointer] <= right_li[right_pointer]:
result.append(left_li[left_pointer])
left_pointer += 1
else:
result.append(right_li[right_pointer])
right_pointer += 1 # 跳出循环,不论左、右序列是否有剩余的元素,直接添加到结果最后
# 注意:python的数组切片时,如果越界,返回空数组
result += left_li[left_pointer:]
result += right_li[right_pointer:] # 返回新的有序数组
return result return alist if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
sorted_li = merge_sort(li)
print(sorted_li)
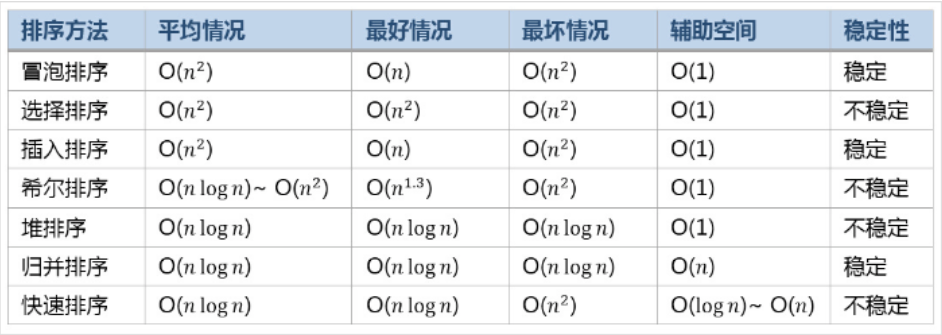
三、常见排序算法效率比较
四、搜索
1、二分法查找、折半查找
(1)针对有序序列,选择中间点,比较查找目标在左右哪个区间,然后递归在该区间查找目标,直到该目标和中间点的值相同(查找到了),否则无结果(没查找到)
(2)代码实现
<1> 递归版本
def binary_search(alist, item):
"""二分查找,递归"""
n = len(alist)
if n > 0: # 每次递归,设置中间角标
mid = n//2 # Section1 查找的值等于中间值,查找成功!
if alist[mid] == item:
return '找到了:' + str(item) # Section2 查找的值小于中间值,递归查找中间值左边的子序列
elif item < alist[mid]:
return binary_search(alist[:mid], item) # Section3 查找的值大于中间值,递归查找中间值右边的子序列
else:
return binary_search(alist[mid+1:], item) # 传入序列元素为空,结束,未查找到!
return '没有找到:' + str(item) if __name__ == "__main__":
li = [17, 20, 26, 31, 44, 54, 55, 77, 93]
print(binary_search(li, 55))
print(binary_search(li, 100))
<2> 非递归
def binary_search_2(alist, item):
"""二分查找, 非递归"""
n = len(alist)
first = 0
last = n-1 # 更改查找的左右区间,直到左指针超过了右指针,循环停止
while first <= last: # 取出中间值坐标
mid = (first + last)//2
if alist[mid] == item:
return "找到了:" + str(item)
elif item < alist[mid]:
# 右指针设置为中间值左边第一个
last = mid - 1
else:
# 左指针设置为中间值右边第一个
first = mid + 1 return "未找到:" + str(item) if __name__ == "__main__": li = [17, 20, 26, 31, 44, 54, 55, 77, 93]
print(binary_search_2(li, 55))
print(binary_search_2(li, 100))
五、树与树算法
1、树的特质
(1)完全二叉树:若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布。
(2)满二叉树:除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)平衡二叉树:又被称为AVL树(区别于AVL算法),它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
(3)特质:
<1>: 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
<2>: 深度为k的二叉树至多有2^k - 1个结点(k>0)
<3>: 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
<4>: 具有n个结点的完全二叉树的深度必为 log2(n+1)
<5>: 对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根,除外)
(4)几种遍历方式:广度遍历,先序遍历(根左右),中序遍历(左根右),后续遍历(左右根)
(5)生成树(包括添加元素、广度遍历)时,使用队列,来存储每个待处理节点,通过队列的pop和append,逐步完成整二叉树的操作。
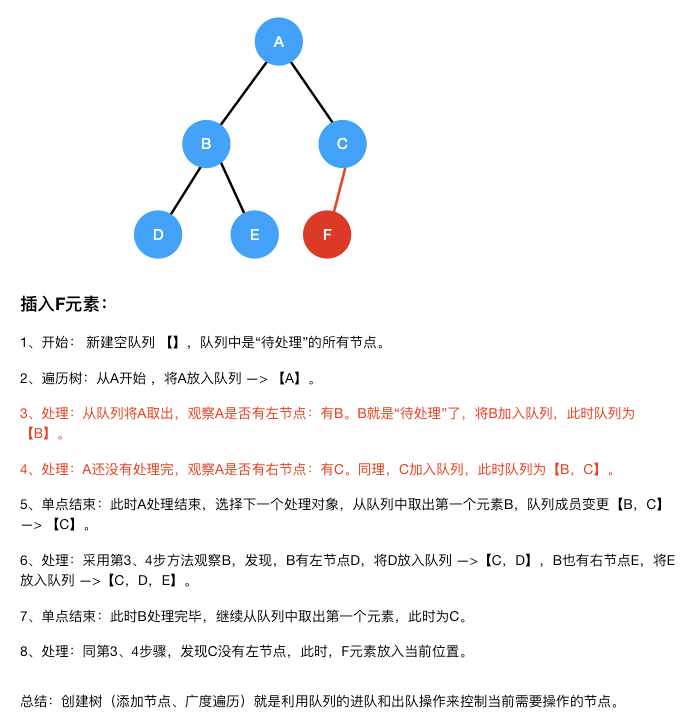
2、代码实现
class Node(object):
"""节点"""
def __init__(self, item):
self.elem = item
self.lchild = None
self.rchild = None class Tree(object):
"""二叉树"""
def __init__(self):
self.root = None def add(self, item):
"""添加节点"""
node = Node(item)
if self.root is None:
self.root = node
return # 取出根节点放到队列中
queue = [self.root] # 只要队列不为空,就一直从队列中取出节点处理
while queue: # 取出当前要处理节点
cur_node = queue.pop(0) # 如果左节点不存在,直接设置item到左节点
if cur_node.lchild is None:
cur_node.lchild = node
return
else:
# 如果左节点存在,将其加入队列中,作为"待处理"的节点
queue.append(cur_node.lchild) # 同上,判断右节点
if cur_node.rchild is None:
cur_node.rchild = node
return
else:
queue.append(cur_node.rchild) def breadth_travel(self):
"""广度遍历"""
if self.root is None:
return
queue = [self.root]
while queue:
cur_node = queue.pop(0)
print(cur_node.elem, end=" ")
if cur_node.lchild is not None:
queue.append(cur_node.lchild)
if cur_node.rchild is not None:
queue.append(cur_node.rchild) def preorder(self, node):
"""先序遍历"""
if node is None:
return
print(node.elem, end=" ")
self.preorder(node.lchild)
self.preorder(node.rchild) def inorder(self, node):
"""中序遍历"""
if node is None:
return
self.inorder(node.lchild)
print(node.elem, end=" ")
self.inorder(node.rchild) def postorder(self, node):
"""后序遍历"""
if node is None:
return
self.postorder(node.lchild)
self.postorder(node.rchild)
print(node.elem, end=" ") if __name__ == "__main__": tree = Tree()
print("\n创建数据结构 0 - 9 数字")
for index in range(10):
tree.add(index)
print("\n广度遍历:")
tree.breadth_travel()
print("\n前序遍历:")
tree.preorder(tree.root)
print("\n中序遍历:")
tree.inorder(tree.root)
print("\n后序遍历:")
tree.postorder(tree.root)
print("\n")
最新文章
- 恢复 root 本地无权限 Access denied for user 'root'@'localhost' (using password: NO)
- 模板:正则替换之后生成标准的php文件 然后include该文件
- System.OutOfMemoryException: 内存不足。(转)
- (C++) Interview in English. - Constructors/Destructors
- centos设置开机自启动
- O(V*n)的多重背包问题
- oracle instantclient basic +pl/sql 安装和配置
- 调试 Azure 云服务项目的方法
- 数据结构(并查集||树链剖分):HEOI 2016 tree
- C++:互斥量C++实现,内存调试,自动锁
- 设计模式20---设计模式之备忘录模式(Memento)(行为型)
- Python安装mysqldb
- MYSQL数据库学习六 索引的操作
- Python 文本转语音
- Scrum Mastery:产品开发中如何优化产品价值?
- tomcat 8.0安装ssl证书,及centos7.2 的openssl升级到最新版本,及ERR_SSL_OBSOLETE_CIPHER错误解决
- AHOI2019N省联考凉凉记
- 元组tuple 可迭代对象
- JS实现购物商城商品放大
- dp——完全背包(方案数)
热门文章
- day21 05 员工信息表
- 优先队列重载运算符< 以及初始化列表
- CodeForcesGym 100517H Hentium Scheduling
- codeforces 88E Interesting Game
- stl lower_bound()和up_bound()
- 1 problem was encountered while building the effective model [FATAL] Non-parseable POM F:\MavenRepository\org\apache\maven\plugins\maven-resources-plugin\2.6\maven-resources-plugin-2.6.pom: start tag
- 洛谷 通天系列 P1760 P1757 P1759
- 【Java集合】Java中集合(List,Set,Map)
- 自定义日志工具LogUtil
- Webstrom打开太慢