1.1-1.3 HBase入门
2024-08-30 08:51:41
一、HBASE入门
部分参考链接:https://www.cnblogs.com/steven-note/p/7209398.html
1、简介
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google BigTable的开源实现,与Google BigTable利用GFS作为其文件存储系统类似,HBase利用Hadoop HDFS作为其文件存储系统;
Google运行MapReduce来处理BigTable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;
Google BigTable利用Chubby作为协同服务,HBase利用Zookeeper作为协同服务。
官网版本:http://archive.apache.org/dist/hbase/ CDH版本(稳定,推荐):http://archive.cloudera.com/cdh5/ ##
HBase的用途:
海量数据存储
准实时查询 HBase的应用场景及特点:
交通
金融
电商
移动(电话信息)等
2、HBASE的特点
HBase的特点:
1、
容量大
HBase单表可以有上百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性。 2.、面向列
HBase是面向列的存储和权限控制,并支持独立检索。列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,
能大大减少读取的数据量。 多版本
HBase每一个列的数据存储有多个Version(version)。 稀疏性
为空的列并不占用存储空间,表可以设计的非常稀疏。 扩展性
底层依赖于HDFS 高可靠性
WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失:Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。
而且HBase底层使用HDFS,HDFS本身也有备份。 3、高性能
底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得HBase具有非常高的写入性能。region切分、主键索引和缓存机制使得HBase在
海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够达到毫秒级别。
二、HBASE架构体系
1、
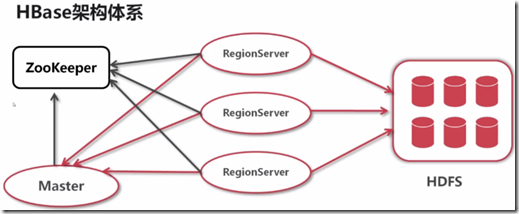
HBase中的每一张表就是所谓的BigTable。BigTable会存储一系列的行记录,行记录有三个基本类型的定义:
RowKey:
是行在BigTable中的唯一标识。 TimeStamp:
是每一次数据操作对应关联的时间戳,可以看作SVN的版本。 Columns family列簇:
定义为<family>:<label>,通过这两部分可以指定唯一的数据的存储列,family的定义和修改需要对HBase进行类似于DB的DDL操作,
而label,不需要定义直接可以使用,这也为动态定制列提供了一种手段。family另一个作用体现在物理存储优化读写操作上,同family
的数据物理上保存的会比较接近,因此在业务设计的过程中可以利用这个特性。 ##
RowKey
与NoSQL数据库一样,rowkey是用来检索记录的主键。访问HBase Table中的行,只有三种方式:
通过单个rowkey访问; 通过rowkey的range; 全表扫描
rowkey行键可以任意字符串(最大长度64KB,实际应用中长度一般为10-100bytes),在HBase内部RowKey保存为字节数组。
存储时,数据按照RowKey的字典序(byte order)排序存储,设计key时,要充分了解这个特性,将经常一起读取的行存放在一起。
需要注意的是:行的一次读写是原子操作(不论一次读写多少列) 列簇
HBase表中的每个列,都归属于某个列簇,列簇是表的schema的一部分(而列不是),必须在使用表之前定义。列名都以列簇作为前缀。例如:
courses:history, courses:math 都属于 courses 这个列簇。
访问控制,磁盘和内存的使用统计都是在列簇层面进行的。
实际应用中,列簇上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、
一些应用可以读取基本数据并创建继承的列簇、一些应用则只允许浏览数据(设置可能因为隐私的原因不能浏览所有数据)。 时间戳
HBase中通过row和columns family确定的为一个存储单元称为cell。每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引。
时间戳的类型是64位整型。时间戳可以由HBase在写入时自动赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显示赋值。
如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中在不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多的版本造成的管理负担,HBase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本
(比如最近七天)。用户可以针对每个列簇进行设置。 Cell
由{row key, columnFamily, version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存储。
表结构逻辑图: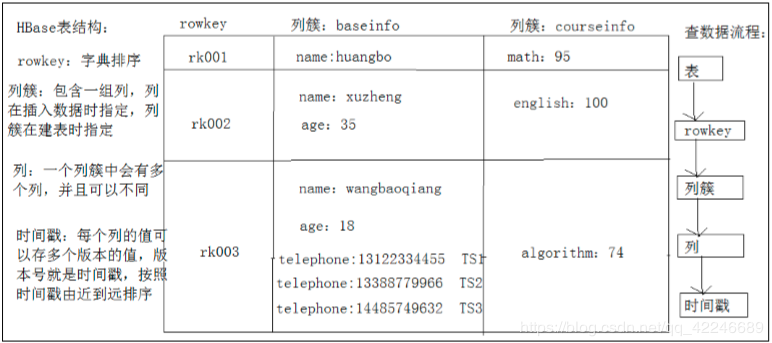
2、HBASE存储架构
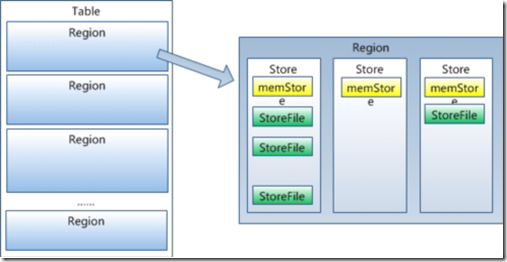
Table在行的方向上分割为多个HRegion,每个HRegion分散在不同的RegionServer中。

每个HRegion由多个Store构成,每个Store由一个MemStore和0或多个StoreFile组成,每个Store保存一个Columns Family
StoreFile以HFile格式存储在HDFS中。
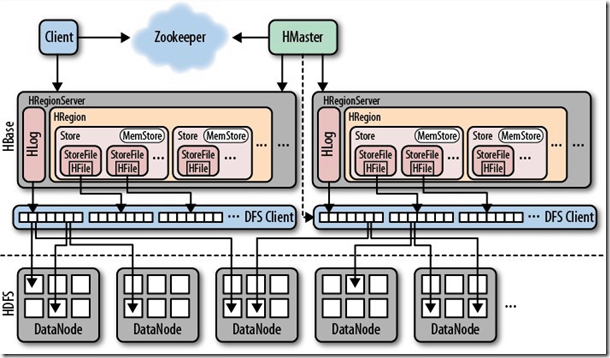
从HBase的架构图上可以看出,HBase中的存储包括HMaster、HRegionSever、HRegion、HLog、Store、MemStore、StoreFile、HFile等,以下是HBase存储架构图:
HBase中的每张表都通过键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,
而HRegion的分配由HMaster管理。 HMaster的作用:
为HRegionServer分配HRegion;
负责HRegionServer的负载均衡;
发现失效的HRegionServer并重新分配;
HDFS上的垃圾文件回收;
处理Schema更新请求; HRegionServer的作用:
维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求;
负责切分正在运行过程中变得过大的HRegion; 可以看到,Client访问HBase上的数据并不需要HMaster参与,寻址访问ZooKeeper和HRegionServer,数据读写访问HRegionServer,
HMaster仅仅维护Table和Region的元数据信息,Table的元数据信息保存在ZooKeeper上,负载很低。HRegionServer存取一个子表时,
会创建一个HRegion对象,然后对表的每个列簇创建一个Store对象,每个Store都会有一个MemStore和0或多个StoreFile与之对应,
每个StoreFile都会对应一个HFile,HFile就是实际的存储文件。因此,一个HRegion有多少列簇就有多少个Store。
一个HRegionServer会有多个HRegion和一个HLog。 HRegion
Table在行的方向上分割为多个HRegion,HRegion是HBase中分布式存储和负载均衡的最小单元,即不同的HRegion可以分别在不同的HRegionServer上,
但同一个HRegion是不会拆分到多个HRegionServer上的。HRegion按大小分割,每个表一般只有一个HRegion,随着数据不断插入表,HRegion不断增大,
当HRegion的某个列簇达到一个阀值(默认256M)时就会分成两个新的HRegion。 Store
每一个HRegion由一个或多个Store组成,至少是一个Store,HBase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,
如果有几个ColumnFamily,也就有几个Store。一个Store由一个MemStore和0或者多个StoreFile组成。 HBase以Store的大小来判断是否需要切分HRegion。 MemStore
MemStore 是放在内存里的,保存修改的数据即keyValues。当MemStore的大小达到一个阀值(默认64MB)时,MemStore会被Flush到文件,
即生成一个快照。目前HBase会有一个线程来负责MemStore的Flush操作。
StoreFile
MemStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
关于Hregion定位的问题:https://www.cnblogs.com/weiyiming007/p/12752723.html
HFile
HBase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。
Trailer中有指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。Data Block是HBase IO的基本单元,为了提高效率,
HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),
大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,
Magic内容就是一些随机数字,目的是防止数据损坏,结构如下。

HFile结构图如下:

Data Block段用来保存表中的数据,这部分可以被压缩。 Meta Block段(可选的)用来保存用户自定义的kv段,可以被压缩。 FileInfo段用来保存HFile的元信息,不能被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index段(可选的)用来保存Meta Blcok的索引。 Trailer这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),
然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。(备注: DataBlock Index的缺陷。 a) 占用过多内存 b) 启动加载时间缓慢)
HLog
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。 LogFlusher
定期的将缓存中信息写入到日志文件中 LogRoller
对日志文件进行管理维护
最新文章
- HashMap的内部实现机制,Hash是怎样实现的,什么时候ReHash
- C# 利用反射根据类名创建类的实例对象
- 使用jquery的imagecropper插件做用户头像上传 兼容移动端
- PC缺少一个或多个网络协议 qq可登录(win10)
- 【Matplotlib】 增加图例
- PHP Filter
- MATLAB GUI程序设计中使文本框接收多行输入的方法
- poj 1581 A Contesting Decision
- MongoDB的分组统计 group
- HDU 4549 M斐波那契数列(矩阵幂)
- 第二百六十三天 how can I 坚持
- bzoj1053
- cocos2d-x 3.3 显示中文
- Android Studio 错误 Duplicate files copied in APK META-INF/LICENSE.txt解决方案
- gerrit工具的数据提交流程
- Nginx + Tomcat 在 Windows7 上搭建负载均衡集群
- MD5加密与Hash加密
- python基础之列表list元组tuple
- eclipse设置字体、字符编码、快捷键
- sklearn 中的 Pipeline 机制