python之openpyxl模块
一 . Python操作EXCEL库的简介
1.1 Python官方库操作excel
Python官方库一般使用xlrd库来读取Excel文件,使用xlwt库来生成Excel文件,使用xlutils库复制和修改Excel文件,这三个库只支持到Excel2003。
1.2 第三方库openpyxl介绍
第三方库openpyxl(可读写excel表),专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易。 注意:如果文字编码是“gb2312” 读取后就会显示乱码,请先转成Unicode
本文将详细介绍第三方库openpyxl的基本用法
第三方库openpyxl的安装:
<1>下载路径:https://pypi.python.org/pypi/openpyxl
<2>解压到指定文件目录:tar -xzvf openpyxl.tar.gz
<3>进入目录,找到setup.py文件,执行命令:python3 setup.py install 如果报错No module named setuptools 就使用命令“easy_install openpyxl”,easy_install for win32,会自动安装setuptools; 或者直接用cmd命令:pip3 install openpyxl安装
二. openpyxl库基本操作总结
2.1 openpyxl 的基本操作
openpyxl中有三个不同层次的类,Workbook是对工作簿的抽象,Worksheet是对表格的抽象,Cell是对单元格的抽象,每一个类都包含了许多属性和方法。
(1)Excel基本操作
操作Excel的一般场景:
a)打开或者创建一个Excel需要创建一个Workbook对象
b)获取一个表则需要先创建一个Workbook对象,然后使用该对象的方法来得到一个Worksheet对象
c)如果要获取表中的数据,那么得到Worksheet对象以后再从中获取代表单元格的Cell对象
(2)Workbook对象知识点总结
一个Workbook对象代表一个Excel文档,因此在操作Excel之前,都应该先创建一个Workbook对象。对于创建一个新的Excel文档,直接进行Workbook类的调用即可,对于一个已经存在的Excel文档,可以使用openpyxl模块的load_workbook函数进行读取,该函数包含多个参数,但只有filename参数为必传参数。filename 是一个文件名,也可以是一个打开的文件对象。
创建workbook对象:
import openpyxl
>>> wb = openpyxl.Workbook(‘hello.xlxs‘)
>>> wb = openpyxl.load_workbook(‘file_name.xlxs‘)
注意:Workbook和load_workbook相同,返回的都是一个Workbook对象。
Workbook对象提供了很多属性和方法,其中,大部分方法都与sheet有关,其所有属性和方法如下:
['_sheets', '_pivots', '_active_sheet_index', 'defined_names', '_external_links', 'properties', 'security', '_Workbook__write_only', 'shared_strings', '_fonts', '_alignments', '_borders', '_fills', '_number_formats', '_protections', '_colors', '_cell_styles', '_named_styles', '_table_styles', 'loaded_theme', 'vba_archive', 'is_template', '_differential_styles', 'code_name', 'epoch', 'encoding', 'iso_dates', 'rels', 'calculation', 'views', '_data_only', '_read_only', '_keep_links', 'guess_types', 'template', '__module__', '__doc__', 'path', '__init__', '_setup_styles', 'read_only', 'data_only', 'write_only', 'keep_links', 'get_active_sheet', 'excel_base_date', 'active', 'create_sheet', '_add_sheet', 'remove', 'remove_sheet', 'create_chartsheet', 'get_sheet_by_name', '__contains__', 'index', 'get_index', '__getitem__', '__delitem__', '__iter__', 'get_sheet_names', 'worksheets', 'chartsheets', 'sheetnames', 'create_named_range', 'add_named_style', 'named_styles', 'get_named_ranges', 'add_named_range', 'get_named_range', 'remove_named_range', 'mime_type', 'save', 'style_names', 'copy_worksheet', 'close', '__dict__', '__weakref__', '__repr__', '__hash__', '__str__', '__getattribute__', '__setattr__', '__delattr__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__new__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__']
Workbook提供的部分常用属性如下:
- active:获取当前活跃的Worksheet
- worksheets:以列表的形式返回所有的Worksheet(表格)
- read_only:判断是否以read_only模式打开Excel文档
- write_only:判断是否以write_only模式打开Excel文档
- encoding:获取文档的字符集编码
- properties:获取文档的元数据,如标题,创建者,创建日期等
- sheetnames:获取工作簿中的表(列表)
#常用属性练习
workbook_path= os.path.join(CONFIG_PATH,'testdata.xlsx')
wb = openpyxl.load_workbook(workbook_path)
ws = wb.active
print(ws)#<Worksheet "Sheet1">
ws_list=wb.worksheets
print(ws_list)#[<Worksheet "Sheet1">, <Worksheet "Sheet2">, <Worksheet "Sheet3">]
print(wb.read_only) #False
print(wb.encoding)#utf-8
print(wb.write_only)#False
print(wb.sheetnames)#['Sheet1', 'Sheet2', 'Sheet3']
print(wb.properties)
#<openpyxl.packaging.core.DocumentProperties object>
#Parameters:
#creator='openpyxl', title=None, description=None, subject=None, identifier=None, language=None, created=datetime.datetime(2018, 8, 18, 2, 14, 50),
# modified=datetime.datetime(2018, 8, 18, 5, 12, 7), lastModifiedBy='wuxiaoli', category=None, contentStatus=None, version=None, revision=None,
# keywords=None, lastPrinted=None
Workbook提供的部分常用方法如下:
- get_sheet_names:获取所有表格的名称(新版已经不建议使用,通过Workbook的sheetnames属性即可获取)
- get_sheet_by_name:通过表格名称获取Worksheet对象(新版也不建议使用,通过Worksheet[‘表名‘]获取)
- get_active_sheet:获取活跃的表格(新版建议通过active属性获取)
- remove_sheet:删除一个表格
- create_sheet:创建一个空的表格
- copy_worksheet:在Workbook内拷贝表格
#workbook常用方法练习
workbook_path= os.path.join(CONFIG_PATH,'testdata.xlsx')
wb = openpyxl.load_workbook(workbook_path)
sheet_names_list=wb.get_sheet_names()#['Sheet1', 'Sheet2', 'Sheet3']
ws1 = wb.get_sheet_by_name('Sheet2')#<Worksheet "Sheet2">
ws2 = wb.get_active_sheet()#<Worksheet "Sheet1">
ws3 = wb.create_sheet('text')#<Worksheet "text">
print(wb.sheetnames)
#wb.remove_sheet(ws3)
wb.copy_worksheet(from_worksheet=ws1)
(3)worksheet对象知识点总结
有了Worksheet对象以后,我们可以通过这个Worksheet对象获取表格的属性,得到单元格中的数据,修改表格中的内容。openpyxl提供了非常灵活的方式来访问表格中的单元格和数据,Worksheet对象的所有属性和方法如下:
['_WorkbookChild__parent', '_WorkbookChild__title', 'HeaderFooter', 'row_dimensions', 'column_dimensions', 'page_breaks', '_cells', '_charts', '_images', '_rels', '_drawing', '_comments', 'merged_cells', '_tables', '_pivots', 'data_validations', '_hyperlinks', 'sheet_state', 'page_setup', 'print_options', '_print_rows', '_print_cols', '_print_area', 'page_margins', 'views', 'protection', '_current_row', 'auto_filter', 'sort_state', 'paper_size', 'formula_attributes', 'orientation', 'conditional_formatting', 'legacy_drawing', 'sheet_properties', 'sheet_format', '__module__', '__doc__', '_rel_type', '_path', 'mime_type', 'BREAK_NONE', 'BREAK_ROW', 'BREAK_COLUMN', 'SHEETSTATE_VISIBLE', 'SHEETSTATE_HIDDEN', 'SHEETSTATE_VERYHIDDEN', 'PAPERSIZE_LETTER', 'PAPERSIZE_LETTER_SMALL', 'PAPERSIZE_TABLOID', 'PAPERSIZE_LEDGER', 'PAPERSIZE_LEGAL', 'PAPERSIZE_STATEMENT', 'PAPERSIZE_EXECUTIVE', 'PAPERSIZE_A3', 'PAPERSIZE_A4', 'PAPERSIZE_A4_SMALL', 'PAPERSIZE_A5', 'ORIENTATION_PORTRAIT', 'ORIENTATION_LANDSCAPE', '__init__', '_setup', 'sheet_view', 'selected_cell', 'active_cell', 'show_gridlines', 'show_summary_below', 'show_summary_right', 'vba_code', 'get_cell_collection', 'freeze_panes', 'add_print_title', 'cell', '_get_cell', '_add_cell', '__getitem__', '__setitem__', '__iter__', '__delitem__', 'min_row', 'max_row', 'min_column', 'max_column', 'calculate_dimension', 'dimensions', 'iter_rows', '_cells_by_row', 'rows', 'values', 'iter_cols', '_cells_by_col', 'columns', 'get_squared_range', 'get_named_range', 'set_printer_settings', 'add_data_validation', 'add_chart', 'add_image', 'add_table', 'add_pivot', 'merge_cells', '_clean_merge_range', 'merged_cell_ranges', 'unmerge_cells', 'append', '_move_cells', 'insert_rows', 'insert_cols', 'delete_rows', 'delete_cols', '_invalid_row', '_add_column', '_add_row', '_write', 'print_title_rows', 'print_title_cols', 'print_titles', 'print_area', '_id', '_default_title', '__repr__', 'parent', 'encoding', 'title', 'oddHeader', 'oddFooter', 'evenHeader', 'evenFooter', 'firstHeader', 'firstFooter', 'path', '__dict__', '__weakref__', '__hash__', '__str__', '__getattribute__', '__setattr__', '__delattr__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__new__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__']
Worksheet提供的部分常用属性如下:
- title:表格的标题
- dimensions:表格的大小,这里的大小是指含有数据的表格的大小,即:左上角的坐标:右下角的坐标
- max_row:表格的最大行
- min_row:表格的最小行
- max_column:表格的最大列
- min_column:表格的最小列
- rows:按行获取单元格(Cell对象) - 生成器
- columns:按列获取单元格(Cell对象) - 生成器
- freeze_panes:冻结窗格
- values:按行获取表格的内容(数据) - 生成器
注意:freeze_panes,参数比较特别,主要用于在表格较大时冻结顶部的行或左边的行。对于冻结的行,在用户滚动时,是始终可见的,可以设置为一个Cell对象或一个端元个坐标的字符串,单元格上面的行和左边的列将会冻结(单元格所在的行和列不会被冻结)。例如我们要冻结第一行那么设置A2为freeze_panes,如果要冻结第一列,freeze_panes取值为B1,如果要同时冻结第一行和第一列,那么需要设置B2为freeze_panes,freeze_panes值为none时 表示 不冻结任何列。
Workbook提供的部分常用方法如下:
- iter_rows:按行获取所有单元格,内置属性有(min_row,max_row,min_col,max_col)
- iter_columns:按列获取所有的单元格
- append:在表格末尾添加数据
- merged_cells:合并多个单元格
- unmerged_cells:移除合并的单元格
(4)cell对象知识点总结
Cell对象比较简单,常用的属性如下:
- row:单元格所在的行
- column:单元格坐在的列
- value:单元格的值
- coordinate:单元格的坐标
(5)Excel基本操作总结
<1>openpyxl的三种最重要的数据结构 NULL空值:对应于python中的None,表示这个cell里面没有数据。
numberic: 数字型,统一按照浮点数来进行处理。对应于python中的float。
string: 字符串型,对应于python中的unicode。 <2>Excel 文件的三个对象 workbook: 工作簿,一个excel工作簿包含多个sheet。
sheet:工作表,一个workbook有多个,表名识别,如“sheet1”,“sheet2”等。
cell: 单元格,存储数据对象 <3>导入 from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.styles import PatternFill, Border, Side, Alignment, Protection, Font, Color, Fill
from openpyxl.styles import colors
from openpyxl.styles import Fill,fills
from openpyxl.formatting.rule import ColorScaleRule <4>加载workbook 加载workbook时注意openpyxl只支持xlsx格式,老版的xls格式需要其他方法去加载。
wb = load_workbook('file_name.xlsx')或wb = load_workbook(filename = r'file_namexlsx') <5>新建worksheet 新建工作表用函数create_sheet() create_sheet(title=None, index=None):
"""Create a worksheet (at an optional index).
:param title: optional title of the sheet
:type title: unicode
:param index: optional position at which the sheet will be inserted
:type index: int """
ws1 = wb.create_sheet() #默认插在最后
ws2 = wb.create_sheet(0) #插在开头建表后默认名按顺序,如sheet1,sheet2...
ws.title = "New Title" #修改表名称
简化 ws2 = wb.create_sheet(title="sheet_name") <6>打开 worksheet 1)通过名字
ws = wb["sheet_name"]
等同于 ws2 = wb.get_sheet_by_name('sheet_name') 2)不知道名字用index
sheet_names = wb.get_sheet_names()
ws = wb.get_sheet_by_name(sheet_names[index])# index为0为第一张表 或者
ws =wb.active
等同于 ws = wb.get_active_sheet() #通过_active_sheet_index设定读取的表,默认0读第一个表
3) 获取活动表表名wb.get_active_sheet().title <7>编辑单元格 1)读写单个单元格
c = ws['A4'] #read 等同于 c = ws.cell('A4')
ws['A4'] = 4 #write
#ws.cell有两种方式,行号列号从1开始
d = ws.cell(row = 4, column = 2) #行列读写
d = ws.cell('A4')
写入cell值
ws.cell(row = 4, column = 2).value = 'test')
ws.cell(row = 4, column = 2, value = 'test')
2)读写多个单元格
cell_range = ws['A1':'C2']#读取A1到C1单元格数据
get_cell_collection()#读所有单元格数据 <8>获取最大行和最大列 print(sheet.max_row)
print(sheet.max_column) <9>获取行和列的值 sheet.rows为生成器, 里面是每一行的数据,每一行又由一个tuple包裹。
sheet.columns类似,不过里面是每个tuple是每一列的单元格。
# 按行获取值,返回值为A1, B1, C1这样的顺序
for row in sheet.rows:
for cell in row:
print(cell.value)
# 按列获取值,返回值为A1, A2, A3这样的顺序
for column in sheet.columns:
for cell in column:
print(cell.value)
上面的代码就可以获得所有单元格的数据。如果要获得某行的数据呢?因sheet.rows是生成器类型,不能使用索引,但是转换成list之后便可使用索引,如list(sheet.rows)[2]这样就获取到第三行的tuple对象。
for cell in list(sheet.rows)[2]:
print(cell.value)
也可以通过iter_rows的参数min_row, max_row指定并获取指定行内容,如下所示,获取第二行表格的内容: for row in ws.iter_rows(min_row=2, max_row=2,):
line = [cell.value for cell in row]
print(line) 此外可使用方法ws.iter_rows()逐行读取数据
ws.iter_rows(range_string=None, row_offset=0, column_offset=0): range-string(string)-单元格的范围:例如('A1:C4') row_offset-添加行 column_offset-添加列
# 返回一个生成器, 注意取值时要用value,例如:
from openpyxl import load_workbook
from constant.constant import CONFIG_PATH
import os.path
test_data = os.path.join(CONFIG_PATH,'testdata.xlsx')
wb = load_workbook(test_data)
ws = wb.active
ws.title = 'testdata.xlsx'
for row in ws.iter_rows('A1:C2'):
for cell in row:
print(cell.value) <10>获取任意区间的值 法1.使用range函数
可以使用range函数,下面的写法,获得了以A1为左上角,B3为右下角矩形区域的所有单元格。注意range从1开始的,因为在openpyxl中为了和Excel中的表达方式一致,并不和编程语言的习惯以0表示第一个值。
workbook_path= os.path.join(CONFIG_PATH,'testdata.xlsx')
wb = openpyxl.load_workbook(workbook_path)
ws = wb.get_sheet_by_name(name='Sheet1')
for i in range(1, 4):
for j in range(1, 3):
print(ws.cell(row=i, column=j))
#out
#<Cell 'Sheet1'.A1>
#<Cell 'Sheet1'.B1>
#<Cell 'Sheet1'.A2>
#<Cell 'Sheet1'.B2>
#<Cell 'Sheet1'.A3>
#<Cell 'Sheet1'.B3>
法2.使用切片,如sheet['A1':'B3'],返回一个tuple,该元组内部还是元组,由每行的单元格构成一个元组。 workbook_path= os.path.join(CONFIG_PATH,'testdata.xlsx')
wb = openpyxl.load_workbook(workbook_path)
ws = wb.get_sheet_by_name(name='Sheet1') for row_cell in ws['A1':'B3']:
for cell in row_cell:
print(cell)
#out
#<Cell 'Sheet1'.A1>
#<Cell 'Sheet1'.B1>
#<Cell 'Sheet1'.A2>
#<Cell 'Sheet1'.B2>
#<Cell 'Sheet1'.A3>
#<Cell 'Sheet1'.B3> for cell in sheet['A1':'B3']:
print(cell)
#out
#(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>)
#(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>)
#(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>)
<11>根据字母获得列号,根据列号返回字母
from openpyxl.utils import get_column_letter, column_index_from_string # 根据列的数字返回字母
print(get_column_letter(2)) # B
# 根据字母返回列的数字
print(column_index_from_string('D')) # <12>写单元格 # 直接给单元格赋值就行
sheet['A1'] = 'good'
# 利用公式在B9处写入平均值
sheet['B9'] = '=AVERAGE(B2:B8)'
#注意:如果是读取,需要加上data_only=True,这样读到B9返回的才是数字,如果不加这个参数,返回的将是公式本身'=AVERAGE(B2:B8)' <13>使用append函数写数据 append函数可以一次添加多行数据,从第一行空白行开始(下面都是空白行)写入。
ws.append(iterable)
#添加一行到当前sheet的最底部(即逐行追加从第一行开始) iterable必须是list,tuple,dict,range,generator类型的。 1,如果是list,将list从头到尾顺序添加。 2,如果是dict,按照相应的键添加相应的键值。
ws.append([‘This is A1’, ‘This is B1’, ‘This is C1’])
ws.append({‘A’ : ‘This is A1’, ‘C’ : ‘This is C1’})
ws.append({1 : ‘This is A1’, 3 : ‘This is C1’})
# 添加一行如下:
row = [1 ,2, 3, 4, 5]
sheet.append(row)
2.2 openpyxl练习
(1)Excel的读取操作练习
练习表格内容如下
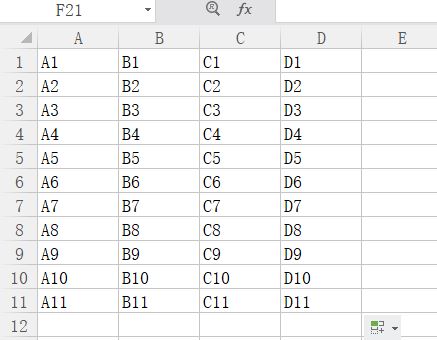
import openpyxl
if __name__=='__main__':
wb = openpyxl.load_workbook(r'D:\pythonstudy\2018-08-18.xlsx')
# 取第一张表
sheetnames = wb.sheetnames
ws = wb[sheetnames[0]]
# 显示表名,表行数,表列数
print("Work Sheet Title:", ws.title)
print("Work Sheet Rows:", ws.max_row)
print("Work Sheet Cols:",ws.max_column)
#获取指定行的值,如第三行
row3_values = []
row3_cell_list = list(ws.rows)[2]
for cell in row3_cell_list:
row3_values.append(cell.value)
print(row3_values)#output:['A3', 'B3', 'C3', 'D3']
#获取所有行的数据
# 建立存储数据的字典
data = {}
# 获取表格所有值
#法1:
for i in range(0,ws.max_row):
every_row_values = []
every_row_cell_list = list(ws.rows)[i]
for cell in every_row_cell_list:
every_row_values.append(cell.value)
data[i+1]= every_row_values
print(data)
#{1: ['A1', 'B1', 'C1', 'D1'], 2: ['A2', 'B2', 'C2', 'D2'], 3: ['A3', 'B3', 'C3', 'D3'], 4: ['A4', 'B4', 'C4', 'D4'], 5: ['A5', 'B5', 'C5', 'D5'],
# 6: ['A6', 'B6', 'C6', 'D6'], 7: ['A7', 'B7', 'C7', 'D7'], 8: ['A8', 'B8', 'C8', 'D8'], 9: ['A9', 'B9', 'C9', 'D9'], 10: ['A10', 'B10', 'C10', 'D10'],
# 11: ['A11', 'B11', 'C11', 'D11']}
#法2
for row in ws.rows:
line = [cell.value for cell in row]
print (line)#output:['A1', 'B1', 'C1', 'D1'],['A2', 'B2', 'C2', 'D2'], ['A3', 'B3', 'C3', 'D3'],['A4', 'B4', 'C4', 'D4'], ['A5', 'B5', 'C5', 'D5'],['A6', 'B6', 'C6', 'D6'],['A7', 'B7', 'C7', 'D7'],['A8', 'B8', 'C8', 'D8'],['A9', 'B9', 'C9', 'D9'],['A10', 'B10', 'C10', 'D10'],['A11', 'B11', 'C11', 'D11']
#获取某个区间的值,例:获得了以A3为左上角,C6为右下角矩形区域的所有单元格
#法1:使用range
data1={}
for i in range(2,6):
every_row_values = []
every_row_cell_list = list(ws.rows)[i]
for cell in every_row_cell_list:
every_row_values.append(cell.value)
data1[i+1]=every_row_values
print(data1)
#output{3: ['A3', 'B3', 'C3', 'D3'], 4: ['A4', 'B4', 'C4', 'D4'], 5: ['A5', 'B5', 'C5', 'D5'], 6: ['A6', 'B6', 'C6', 'D6']}
#法2:使用切片
data_list = []
for row_cell in ws['A3':'C6']:
every_row_value = []
for cell in row_cell:
every_row_value.append(cell.value)
data_list.append(every_row_value)
print(data_list)#output:[['A3', 'B3', 'C3'], ['A4', 'B4', 'C4'], ['A5', 'B5', 'C5'], ['A6', 'B6', 'C6']]
(2)封装一个读取表格的类,实用于读测试用例
#-*- coing=utf-8 -*-
from openpyxl import load_workbook
from constant.constant import CONFIG_PATH
import os.path class ExcelReader(object):
"""
Read the contents of the excel file, Return list.
example:
The contents of the excel file:
| A | B | C |
| A1 | B1 | C1 |
| A2 | B2 | C2 |
print(ExcelReader(excel, title_line=True).data),output:
[{A: A1, B: B1, C:C1}, {A:A2, B:B2, C:C2}]
print(ExcelReader(excel, title_line=False).data),output:
[[A,B,C], [A1,B1,C1], [A2,B2,C2]]
You can specify sheet through index or name:
example:
ExcelReader(excel, sheet=2)
ExcelReader(excel, sheet='testdata')
""" def __init__(self, excel, sheet=0, title_line=True):
if os.path.exists(excel):
self.excel = excel
else:
raise FileNotFoundError('Excel file does not exist !')
self.sheet = sheet
self.title_line = title_line
self._data = list() @property
def data(self):
if not self._data:
workbook = load_workbook(self.excel)
if type(self.sheet) not in [int, str]:
raise TypeError('Please pass in <type int> or <type str>, not {0}'.format(type(self.sheet)))
elif type(self.sheet) == int:
sheetnames = workbook.sheetnames
ws = workbook[sheetnames[self.sheet]]
else:
ws = workbook[self.sheet] if self.title_line:
for row in ws.iter_rows(min_row=1, max_row=1, ):
title = [cell.value for cell in row]# 首行为title for i in range(1, ws.max_row):
every_row_cell_list = list(ws.rows)[i]
every_row_value = []
for cell in every_row_cell_list:
every_row_value.append(cell.value)
self._data.append(dict(zip(title, every_row_value)))
else:
for row in ws.rows:
self._data.append([cell.value for cell in row])
return self._data if __name__ == '__main__':
test_data = os.path.join(CONFIG_PATH,'testdata.xlsx')
reader = ExcelReader(test_data,sheet= 0,title_line=False)
print(reader.data)
(3)Openpyxl常用操作的封装
#-*- coing=utf-8 -*-
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter, column_index_from_string
from config.globalconfig import TEST_DATA_PATH
import os.path class ExcelReader(object): def __init__(self, excel, sheet=0, title_line=True,column=None,row=None):
"""
:param excel: excel path,type=str
:param sheet: sheet name or sheet sequence number,type = str or int
:param title_line: title_line = True,return dic,title_line = False,return list
:param column: Non essential parameter,type = int or str,int express column number,str express column field name of first line
:param row: Non essential parameter,type = int,express row number
"""
if os.path.exists(excel):
self.excel = excel
else:
raise FileNotFoundError('Excel file does not exist !')
self.sheet = sheet
self.title_line = title_line
self.column = column
self.row = row
self._data = []
self._cell_data = str()
self.workbook = load_workbook(self.excel)
if type(self.sheet) not in [int, str]:
raise TypeError('Please pass in <type int> or <type str>, not {0}'.format(type(self.sheet)))
elif type(self.sheet) == int:
sheetnames = self.workbook.sheetnames
self.ws = self.workbook[sheetnames[self.sheet]]
else:
self.ws = self.workbook[self.sheet] @property
def sheet_data(self):
"""
Read the contents of the excel file, Return list.
example:
The contents of the excel file:
| A | B | C |
| A1 | B1 | C1 |
| A2 | B2 | C2 |
print(ExcelReader(excel, title_line=True).data),output:
[{A: A1, B: B1, C:C1}, {A:A2, B:B2, C:C2}]
print(ExcelReader(excel, title_line=False).data),output:
[[A,B,C], [A1,B1,C1], [A2,B2,C2]]
You can specify sheet through index or name:
example:
ExcelReader(excel, sheet=2)
ExcelReader(excel, sheet='testdata')
"""
if not self._data:
if self.title_line:
for row in self.ws.iter_rows(min_row=1, max_row=1, ):
title = [cell.value for cell in row]# 首行为title for i in range(1, self.ws.max_row):
every_row_cell_list = list(self.ws.rows)[i]
every_row_value = []
for cell in every_row_cell_list:
every_row_value.append(cell.value)
self._data.append(dict(zip(title, every_row_value)))
else:
for row in self.ws.rows:
self._data.append([cell.value for cell in row])
return self._data def column_letter(self):
"""Column number converted to letter form."""
if isinstance(self.column, (int)):
return get_column_letter(self.column) # 数字转换为字母
elif isinstance(self.column, (str)):
for row in self.ws.iter_rows(min_row=1, max_row=1, ):
columnFieldName = [cell.value for cell in row]
if columnFieldName.count(self.column) == 1: # 相同字段名存在的个数
for index, cell in enumerate(columnFieldName):
if cell == self.column:
return get_column_letter(index + 1)
elif columnFieldName.count(self.column) == 0:
raise ValueError("Current sheet page '%s' no field name '%s' exists!" % (self.ws.title, self.column))
else:
raise ValueError("Current sheet page'%s'include duplicate field name '%s'" % (self.ws.title, self.column))
else:
raise TypeError("The column parameter type should be int or str, not '%s'" % (self.column.__class__))
@property
def cell_data(self):
if not self._cell_data:
if not isinstance(self.row, (int)):
raise TypeError("The row parameter type should be int instead of '%s'!" % (self.row.__class__))
column = self.column_letter()
return self.ws[column + str(self.row)].value class ExcelWritter(ExcelReader):
def __init__(self, excel, sheet=0, column=None,row=None,value=''):
ExcelReader.__init__(self,excel,sheet=0)
self.value = value
self.column =column
self.row = row def write_cell(self):
if not isinstance(self.row, (int)):
raise TypeError("The row parameter type should be int instead of '%s'!" % (self.row.__class__))
if not isinstance(self.value, (str)):
raise TypeError("The value parameter type should be str instead of '%s'!" % (self.value.__class__)) column = self.column_letter()
self.ws[column + str(self.row)].value = self.value
self.workbook.save(self.excel)
(4)写存在的xlsx文件,报错:PermissionError: [Errno 13] Permission denied的解决办法
此问题为文件被拒绝访问,主要是该文件已经被打开了。关闭此excel文件后在执行excel的相关操作就ok了。
>>>>>>>>>>待续
最新文章
- MVC中部分视图调用方法总结
- 联合主键用Hibernate注解映射的三种方式
- Android自定义View
- 可复用的js效果
- 10款实用Android UI 开发框架
- java多线程之从任务中获取返回值
- What is the difference between position: static,relative,absolute,fixed
- MoreLinq和Linq
- VBA Excel 常用 自定义函数
- poj 2104 K-th Number 划分树,主席树讲解
- MATLAB中的函数的归总
- JavaScript引用类型之Object类型
- Day 1: How to install jedi/codeintel plugin for sublime on Linux
- Nginx网站使用CDN之后禁止用户真实IP访问的方法
- 正则表达式&常用JS校验
- Geohash-》通过经纬度计算两地距离的函数
- python下用OpenCV的圆形检测
- Windows已遇到关键问题,将在一分钟后自动重新启动,请立即保存工作
- 编辑器-vim
- npm的源改成淘宝镜像