Hadoop第三课
1.3Hadoop基础知识
1.3.1术语解释
1.Hadoop1.0
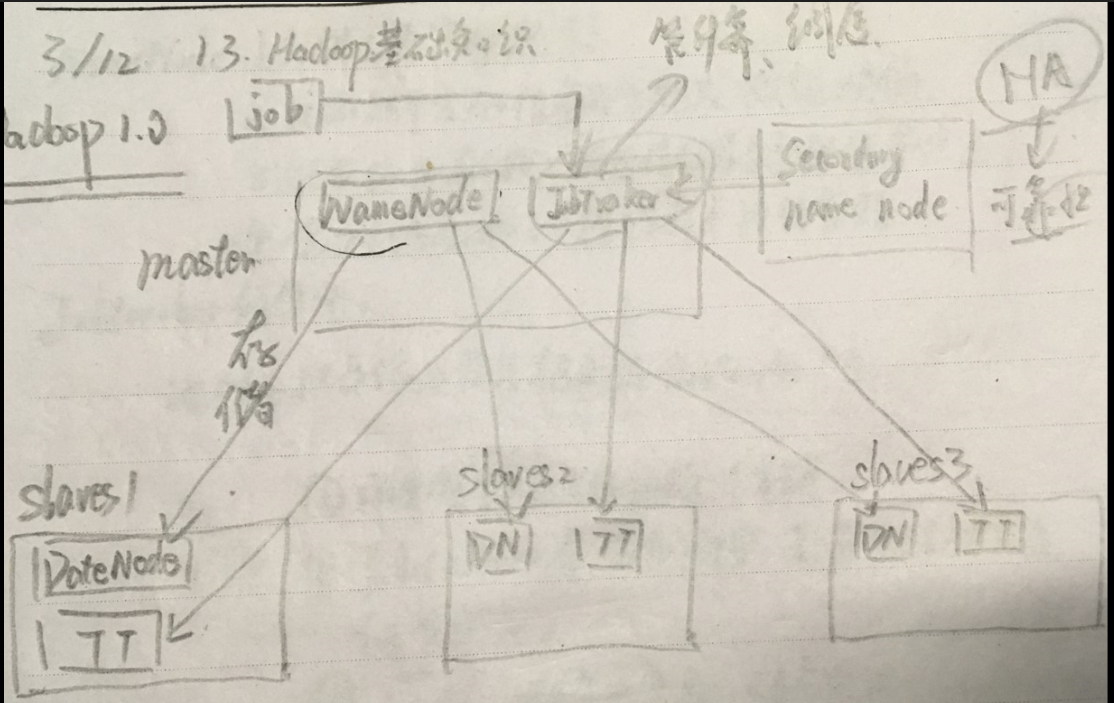
• 第一代Hadoop,由分布式文件系统HDFS 和分布式计算框架MapReduce组成
• HDFS由一个NameNode和多个DataNode 组成
• MapReduce由一个JobTracker和多个 TaskTracker组成
课堂笔记
图中的4个英文单词都是指带进程。
进程简而言之就是程序(一行行的代码)加上启动这个程序所包含的所有资源。
大致讲解一下Hadoop1.0,看图!master这个节点中有两个进程,NameNode和JobTracker;slaves这个节点中也有两个进程,DateNode和TaskTracker。首先我们要知道上文所陈列的三点,顾名思义,NameNode管存储,将资源存储在DateNode中;而JobTracker管计算和调度,(DateNode和TaskTracker在同一个地方,一个存储,一个计算,这种计算方法是最优化的)。我们可以打个比方,比作是一个公司,那么CEO—JobTracker,秘书—NameNode(真正的存储是存储在DateNode是我身上的)。
但这样的Hadoop1.0有一个致命的缺点,倘若宕机的是master这一节点,这一系统就彻底奔溃了,这时,我们想到了一个解决方法,给master作备份,然而这个备份是冷备份,也就是说不是实时备份的,因而我们所说的单点故障是由NameNode的冷备份所造成的,所以Hadoop1.0没有走下去。
master这一节点在整个集群中是不唯一的。NameNode是唯一的。slaves这个节点也不唯一,是多个的。
下面分别阐述下几个进程的作用:
- NameNode:
1.HDFS的守护进程。
2.记录文件是如何被分隔成数据块的。
3.记录这些数据块被存储到哪些节点上。
4.会对内存和IO进行集中性的管理。
- JobTracker:
客户端提交作业首先是提交给JobTracker的。
1.用于处理后台作业的一个程序。
2.JobTracker会分割任务,并分配到对应的节点上。
3.分析:任务未完成;任务失败。重新启动失败的任务;重新调度,让新的节点来完成这一任务。
- DateNode
每一台slaves服务器上都有一个DateNode的进程。DateNode的工作:负责将HDFS上的数据读取到本地文件文件系统中去。
- TaskTracker
做具体工作的一个进程。作用:启动多个JVM,并执行Map或reduse的任务。
————————————————————————————————————
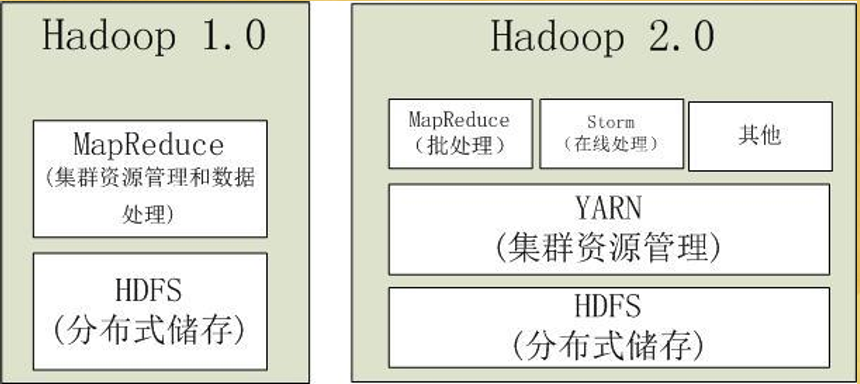
2.Hadoop2.0
- 第二代Hadoop,为克服Hadoop1.0中 HDFS和MapReduce存在的各种问题而提出
- Hadoop1.0单NameNode制约HDFS扩展性,(因为内存大小限制了节点的个数,大体为4000个节点个数) 提出HDFS Federation (联合 思想:分而治之)
- Hadoop1.0中MapReduce在扩展性和多框架支持等方面的不足,将JobTracker中的资 源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现
ps:Spark—搭建在Hadoop上才变成分布式的。
因为有了YARN,所以可以有其他框架进入Hadoop2.0这个载体上,这是个松耦合。
3.MapReduce1.0或MRv1
MRv1中计算框架为三个部分:
- 编程模型——Map和Reduce函数组成
- 数据处理引擎——Map Task和Reduce Task组成
- 运行环境——一个JobTracker和多个 TaskTracker组成
4.MRv2
- 与MRv1相同的编程模型和数据处理引擎, 不同的是运行环境
- MRv2是在MRv1基础上经过加工后,运行 于资源管理框架YARN之上的计算框架 MapReduce
- 由通用资源管理系统YARN和作业控制进程 ApplicationMaster来完成相应工作
5.YARN
- Hadoop2.0中的资源管理系统,是一个通用 资源管理模块,可为各类应用程序进行资 源管理和调度
- YARN不仅限于MapReduce一种计算框架, 也可供其他框架使用,如Spark、Storm
- 由于YARN的通用性,下一代MapReduce 的核心已从简单的支持单一应用的计算框 架转移到通用资源管理系统上
ps:MESOS也是一个通用资源管理器。
Hadoop1.0+Spark+Storm这三个框架造成了资源浪费,人力资源问题等。有YARN后,这些问题就得以优化,当Spark用的比较多时,可以将资源迁移到Spark上。
6.HDFS Federation
- Hadoop2.0对HDFS进行了改进,使 NameNode可以横向扩展成多个,每个 NameNode分管一部分目录,进而产生了 HDFS Federation
- 该机制的引入不仅增强了HDFS的扩展性, 也使HDFS具备了隔离性
1.3.2Hadoop版本变迁
Apache Hadoop主要有四个系列的版本:
- 0.20.X系列——最老版本
- 0.21.0/0.22.x系列——俗称Hadoop1.0版本
- 0.23.X系列——克服Hadoop在扩展性和框 架通用性方面的不足
- 2.X系列——同0.23.X系列一样,属于 Hadoop2.0版本,主要增加了NameNode HA等功能
作业
- 什么是Hadoop,你理解中的Hadoop是什么,请举例说明?
- Hadoop2.0生态系统中包括哪些产品,请描述他们之间的关系?
最新文章
- Java分别与MySQL、Oracle、SQL Server数据库建立连接
- commonJS — 全局操作(for Window)
- 阅读jQuery源码的18个惊喜
- How a woman's glance can tell a man if she's interested
- spring quartz 定时任务“Failed to load class "org.slf4j.impl.StaticLoggerBinder”“Checking for available updated version of Quartz”
- Dom4j写XML
- liGDX life_cycle (生命周期)
- robotium如何定位控件?
- reshape2 数据操作 数据融合 (melt)
- 201521123001《Java程序设计》第7周学习总结
- OpenCV4Android
- Linux学习之CentOS(一)--CentOS6.5环境搭建
- 逆向学习-Upack的PE文见头分析
- Laravel设置软删除及其恢复系列操作
- 关于http以及aphace配置https
- python 全栈开发,Day43(引子,协程介绍,Greenlet模块,Gevent模块,Gevent之同步与异步)
- The origin server did not find a current representation for the target resource or is not willing to disclose that one exists.
- OC MRC之autorelease问题(代码分析)
- Docker入门讲解
- Playfair加密