3.资源调度框架yarn
既然要分析yarn,无非是从以下方面分析
(一).yarn产生背景
(二).yarn概述
(三).yarn架构
(四).yarn执行流程
(五).yarn环境搭建
(六).提交作业到yarn上运行
(一).yarn产生的背景
1.在Mapreduce1.x版本中,单点故障以及节点压力大不容易扩展
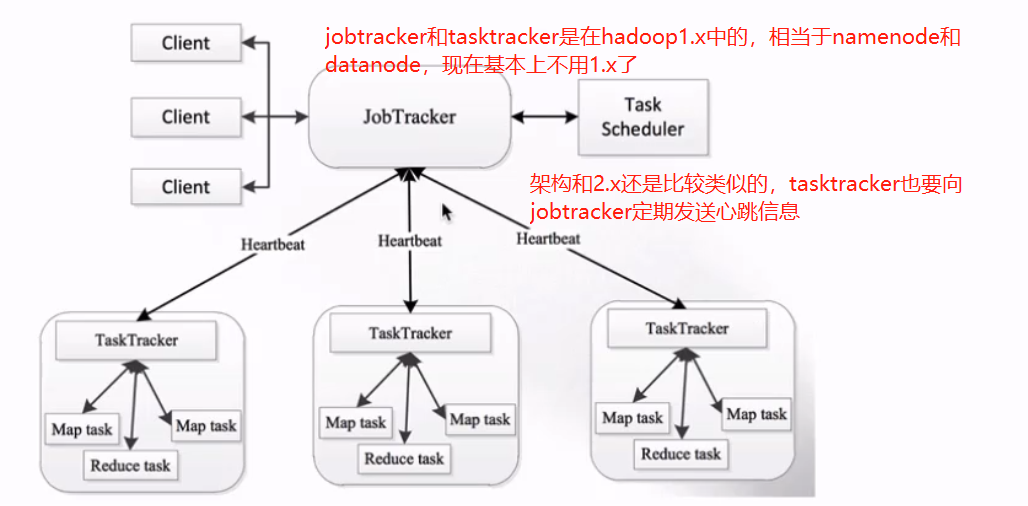
而且这种架构只支持MapReduce,像spark就无法支持
2.资源利用率低,以及运维成本高
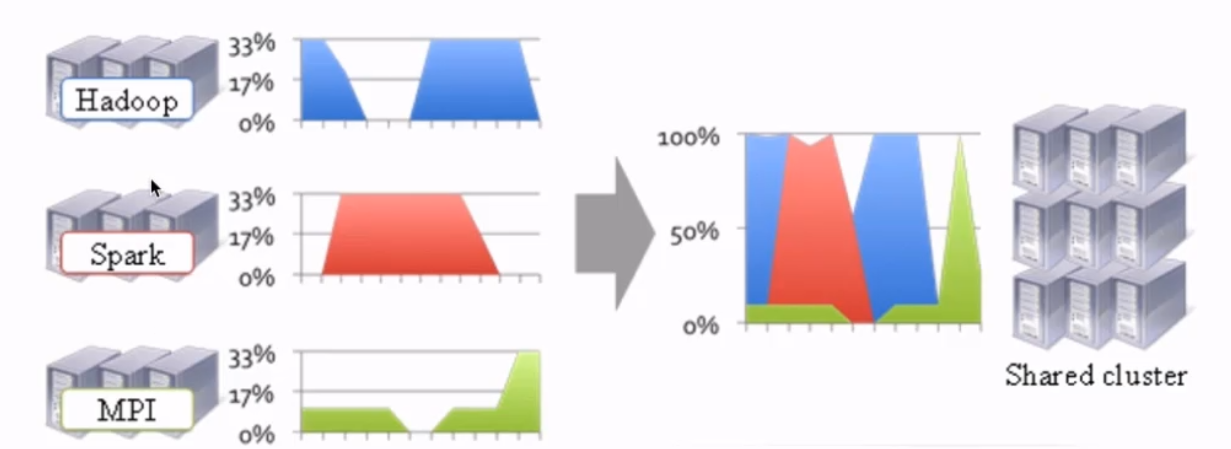
可以看到多个集群之间空闲比较多,资源利用率低,并且集群之间资源无法共享。hadoop空闲的时候无法给spark用,并且如果spark相对hadoop上的数据进行操作,需要跨网络把hadoop上的数据移过来,这个消耗是非常大的。那么能不能有一种模式,在一个集群上面运行hadoop,spark等等,共享一个集群的资源,这样肯定能大大减少数据移动所带来的成本,提高资源的利用率
以上原因便促使了yarn的诞生
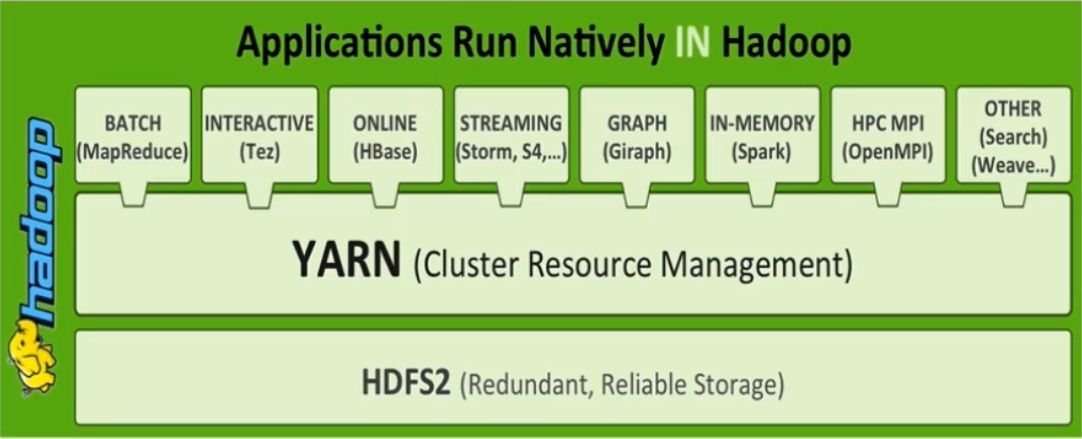
可以看到在有了yarn之后,可以支持很多计算框架。在hadoop1.x的时候,只支持MapReduce,但是2.x有了yarn之后,可以支持各种不同的计算框架,并且这些框架共享一个hdfs里的所有资源。我们可以把yarn想象成一个操作系统级别的资源调度框架,可以让更多不同的计算框架运行在同一个集群里面,享受整体的资源调度。
我们也常常听到xxx on yarn,这里的xxx可以使spark,MapReduce,storm,flink。这样的好处就在于与其他框架共享集群资源,按资源需要分配,进而提高集群资源的利用率
(二).yarn的概述
yarn是一个通用的资源管理系统,为上层应用提供统一的资源管理和调度
(三).yarn的架构
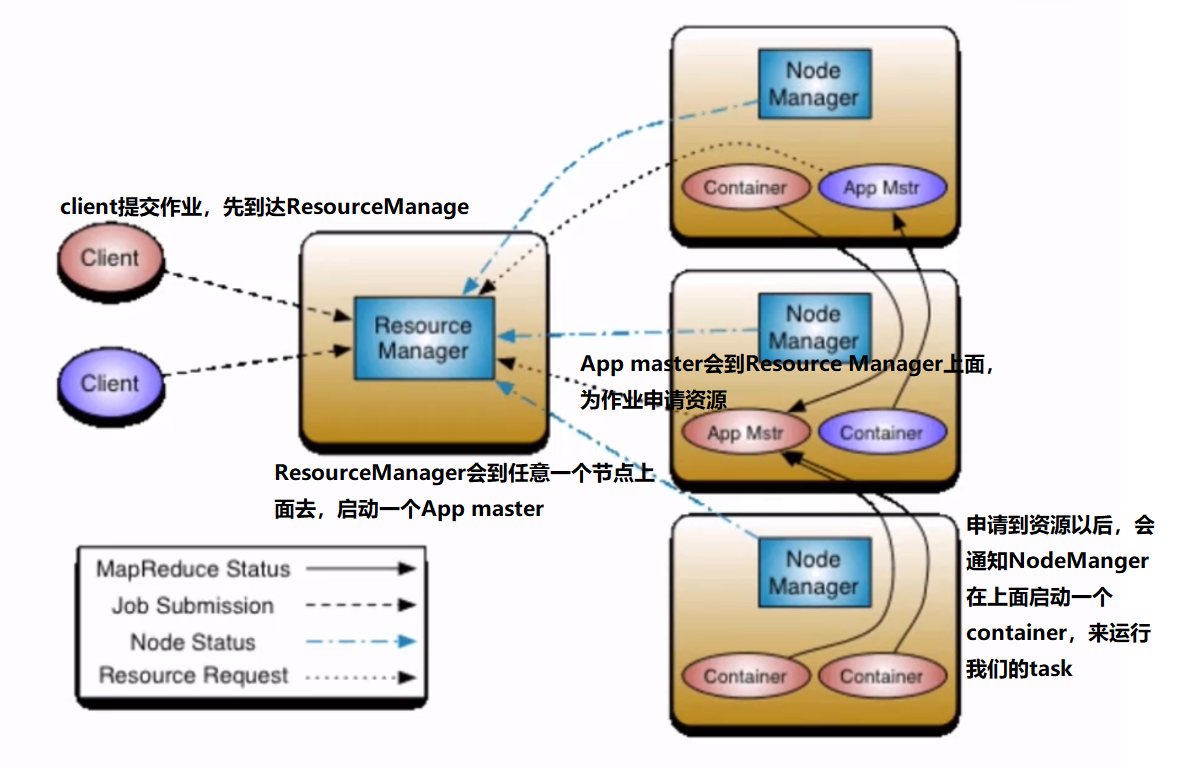
1)ResourceManager:RM
整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
处理客户端的请求:提交一个作业,杀死一个作业
监控NodeManager,一旦某个NM挂掉了,那么在该NM上运行的任务需要告诉我们的ApplicationMaster,来如何进行处理
2)NodeManager:NM
整个集群中有多个,负责自己本身节点的资源管理和使用
定时向RM汇报节点的资源使用情况
接收并处理来自RM的各种命令:启动container
处理来自AM的命令
单个节点的资源管理
3)ApplicationMaster:AM
每个应用程序对应一个AM,比如,MapReduce,spark,AM负责应用程序的管理
为应用程序申请资源(core,memory),分配给内部的task
需要与NM通信:启动/停止task。
task是运行在container里面的,AM也是
4)Container
封装了CPU,memory等资源的容器
是任务运行环境的一个抽象
5)Client
提交作业
查询作业的运行进度
杀死作业
(四).yarn的执行流程
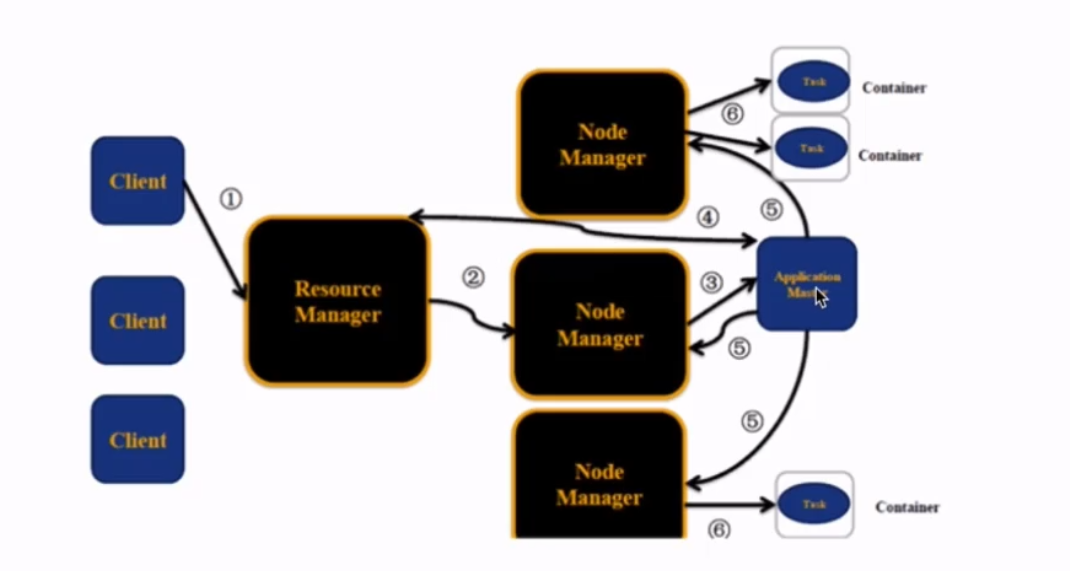
用户向yarn提交一个作业,比如一个MapReduce作业,spark作业。
那么RM会为作业分配第一个container,假设运行在第二个节点上面。RM就会与对应的NM进行通信,要求在该NM上面启动一个container,这个container是用来启动AM的。然后AM会到RM上进行一个注册。然后client就可以直接通过RM来查询作业的运行情况了
然后AM会将你作业所需要的core,memory来向RM申请,所以第四个箭头是来回的,双向的
然后AM在对应的NM上启动container,运行task
(五).yarn环境搭建
yarn并不需要单独下载,只需要修改两个配置文件即可。
yarn-site.xml
mapred-site.xml
配置文件仍然在etc/hadoop下面
1.修改mapred-site.xml
但是你会发现没有这个文件,倒是有mapred-site.xml.template这个文件,我们需要拷贝一份,然后把名称改成mapred-site.xml

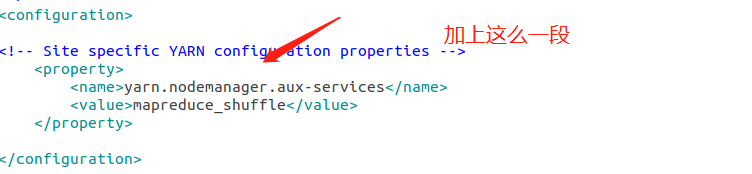
2.修改yarn-site.xml
3.启动yarn相关的进程
sbin/start-yarn.sh
4.验证
可以通过jps,也可以通过浏览器访问http://localhost:8088

启动成功

jps显示多了两个进程
我们也可以使用浏览器来访问,访问http://local:8088,或者http://ubuntu:8088,因为我这里的主机名就叫ubuntu
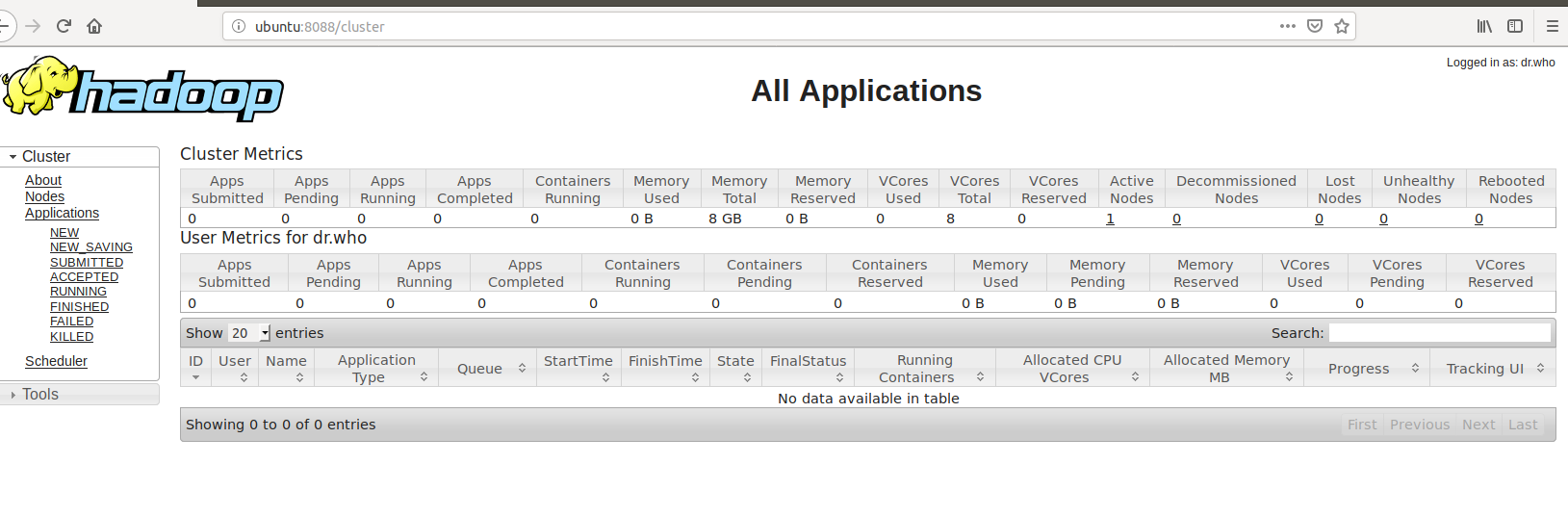
我们集群的详细信息都显示了出来
5.停止yarn
sbin/stop-yarn.sh
(六).提交作业到yarn上运行
我们还没有介绍MapReduce,后面会介绍,但是我们之前说了,hadoop为我们提供了一个测试用例,名字带example的那个
/usr/local/hadoop-cdh/hadoop-2.6.0-cdh5.8.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.8.5.jar

这个包的使用方法,输入hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.8.5.jar会有提示
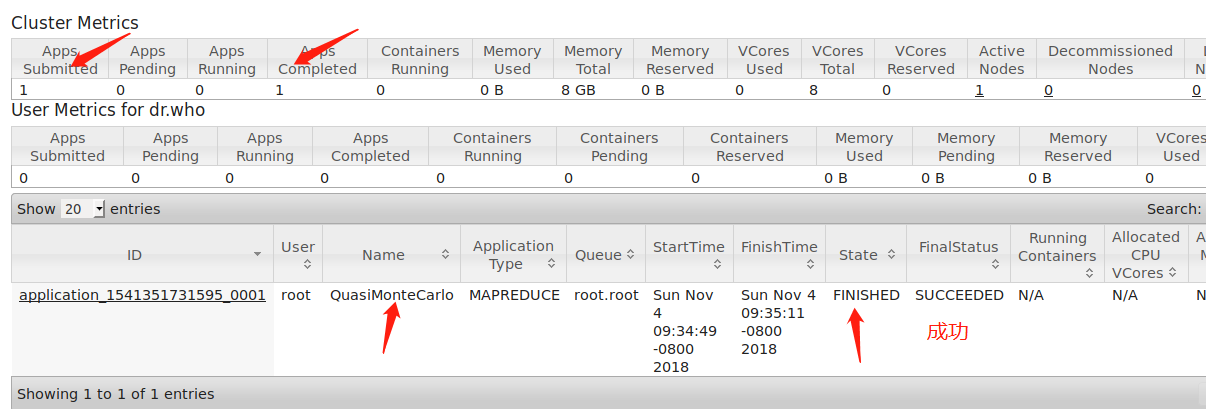
我这里输入的是hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.8.5.jar pi 2 3,我们来通过浏览器看看结果
最新文章
- es6分享——变量的解构赋值
- Unique Binary Search Trees
- js插入拼接链接 --包含可变字段
- Eclipse远程调试(远程服务器端监听)
- 简单排序算法 C++类实现
- Java中的JDBC数据库连接
- 【LINUX】Linux学习小结
- STC51系列单片机免掉电下载(热启动下载)
- 1071: [SCOI2007]组队 - BZOJ
- linux_windows下配置tomcat区别 ,不同子域名映射不同 项目
- Eclipse 中svn 分支,主干 合并与同步:
- 使用redis设计一个简单的分布式锁
- JavaScript 递归
- Java集合详解8:Java集合类细节精讲
- mutex,thread
- JS根据屏幕分辨率改变背景宽高
- C# Winform ListView控件
- camera理论基础和工作原理【转】
- [leetcode]33. Search in Rotated Sorted Array旋转过有序数组里找目标值
- Spark记录-SparkSql官方文档中文翻译(部分转载)
热门文章
- 安装arch系统时,把ubuntu的efi分区格式化
- Linux pthread 线程池实现
- 官方文档 恢复备份指南七 Using Flashback Database and Restore Points
- Java项目启动时候报Neither the JAVA_HOME nor the JRE_HOME environment variable is defined 解决办法
- ExtJS新手学习中常见问题
- sudo是干哈子的
- vThunder 安装
- [Leetcode] unique paths ii 独特路径
- [Leetcode] distinct subsequences 不同子序列
- BZOJ1293 [SCOI2009]生日礼物 【队列】