图像分割之mean shift
2024-08-28 15:05:34
阅读目的:理解quick shift,同时理解mean shift原理,mean shift用于图像聚类,优点是不需要指定聚类中心个数,缺点是计算量太大(原因)。
mean shift主要用来寻找符合一些数据样本的模型,证明样本符合某一概率密度函数(PDF),是一种非参数迭代算法能够寻找模型和聚类。
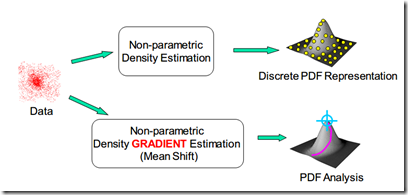
数据经过非参数密度估计能够得到符合数据分布的概率密度函数,而mean shift是非参数的密度梯度估计,能够对概率密度函数进行分析,比如找到概率密度函数极值点。
面对的是什么样的一个问题,mean shift能够解决?
以聚类为例,一副图像需要进行分割,根据的是像素间的距离和像素的颜色,亮度相似性。那么我们就将这些东西量化构建一个图像的特征空间。这个特征空间包括像素在图像中的位置以及每个像素RGB三个分量。在特征空间中位置相近,颜色相近会聚集在一起成为一类。
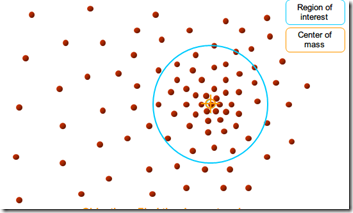
我们的目的是找到这样一个个聚类中心,将中心一定范围内的像素赋值给相同的标签。mean shift将特征空间(连续的)中的点(如图像中的像素)当成抽样隐藏概率密度函数(可表示成曲面或超曲面)上的点(如上图),那么密集的区域或者某个聚类就相当于概率密度函数的模式(局部最大值)。这样找聚类中心就转换成求隐含概率密度函数的模式。
mean shift 的流程
1.在特征空间中每个点上放置一个窗口
2.计算窗口中所有数据的均值
3.移动窗口到均值,直到窗口到达最密集的区域。
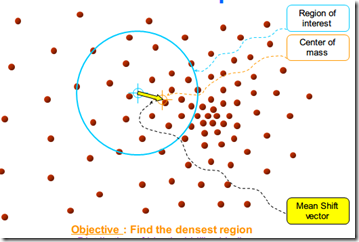
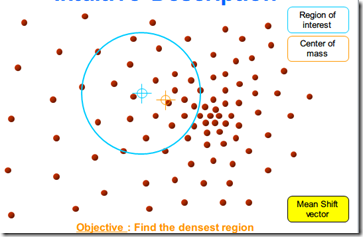
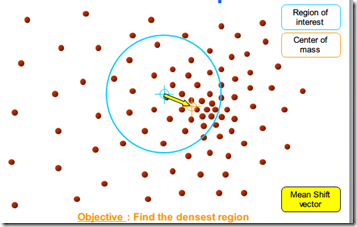
待更新
最新文章
- 关于iis8.5中发布的网站无法连接数据库的解决方案。
- C++ const
- Python自动化 【第一篇】:Python简介和入门
- 转载的vim配置文件
- js判断是电脑访问手机版网站,跳转到电脑版
- linux 常用alias
- 【BOZJ 1901】Zju2112 Dynamic Rankings
- weblogic 10域结构
- 基于WebForm+EasyUI的业务管理系统形成之旅 -- 构建Web界面(Ⅴ)
- 更新xcode后插件失效问题——不针对特定版本的通用解决方法
- kafka消息监控-KafkaOffsetMonitor
- iOS开发zhiATM机的设计与实现
- 【百度地图API】如何给自定义覆盖物添加事件
- 【Machine Learning in Action --2】K-近邻算法构造手写识别系统
- 移动端HTML5性能优化
- java实现Quartz定时功能
- mysql8绿色免安装win64版本(自带heidisql.exe客户端)应该兼容老版第三方工具。
- linux中时间命令详解
- Head First Servlets & JSP 学习笔记 第七章 —— 作为JSP
- oracle中nvarchar2()和varchar2()的区别