NameNode数据存储
HDFS架构图
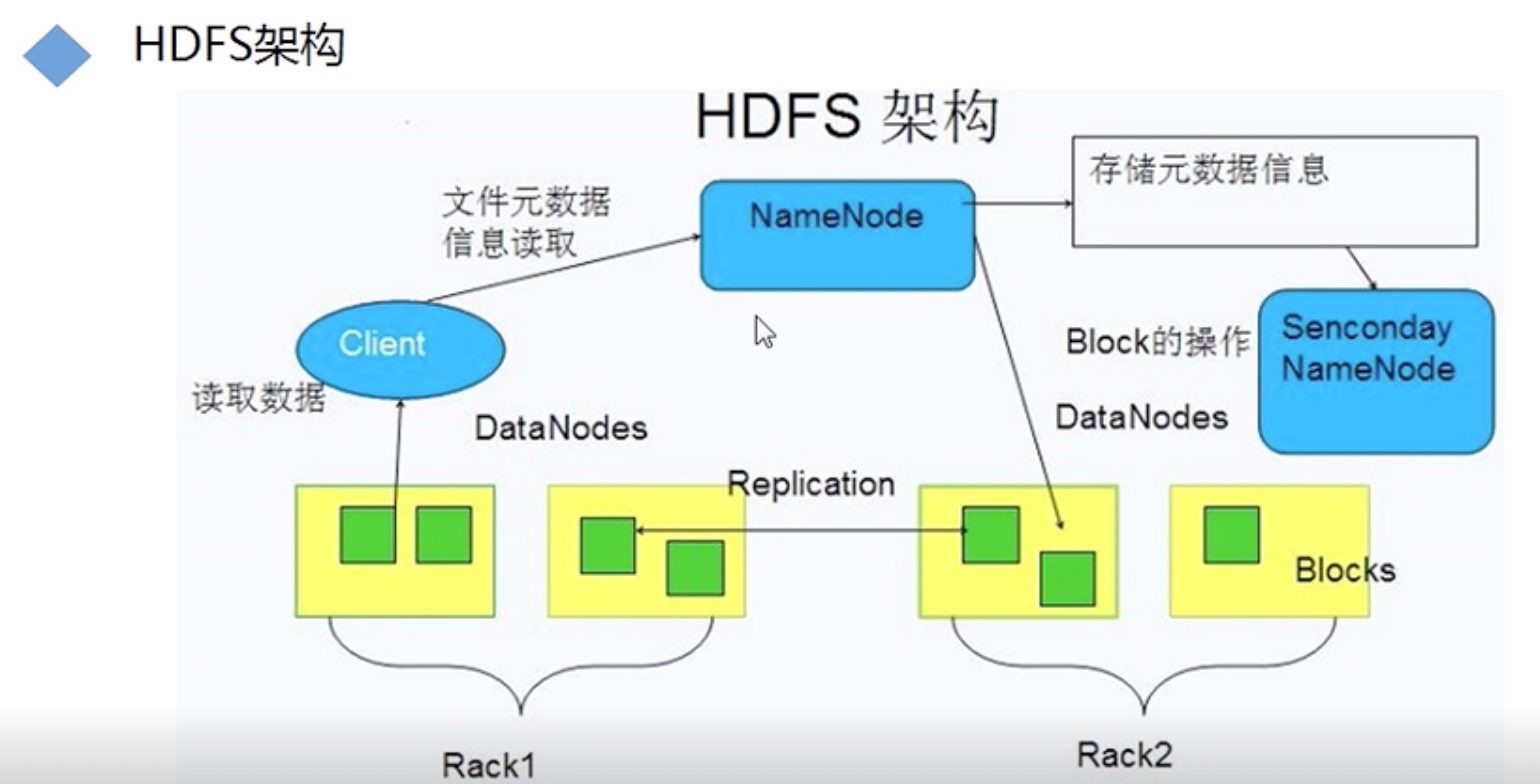
HDFS原理
1) 三大组件
NameNode、 DataNode 、SecondaryNameNode
2)NameNode
存储元数据(文件名、创建时间、大小、权限、文件与block块映射关系)
3)DataNode
存储真实的数据信息
4)SecondaryNameNode
合并edits日志文件和fsimage镜像文件进行合并
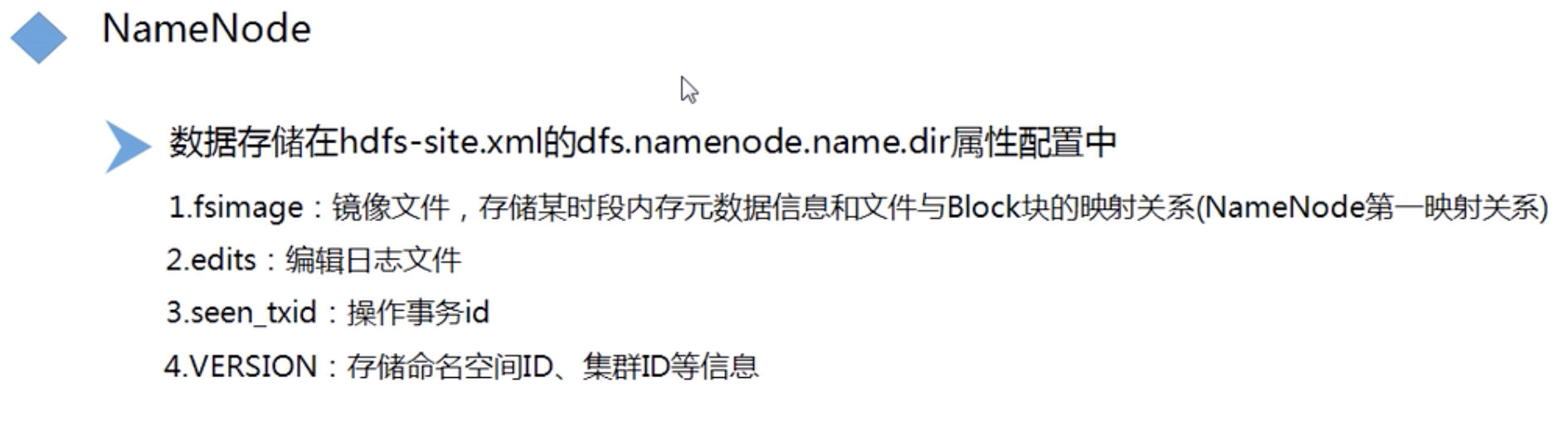
详细信息如下:
其中fsimage_0000000000000000000000属于镜像文件
see_txid操作事务id
其中fsimage_0000000000000000000000.md5属于校验和
VERSION属于版本号,详细信息如下:
(1)dfs.namenode.name.dir file://{$hadoop.tmp.dir}/dfs/name
hadoop.tmp.dir /tmp/hadoop-${user.name}
多次格式化的问题:
hdfs格式化会改变VERSION文件中的clusterID, 首次格式化时datanode和namenode会产生相同的clusterID;
如果重新执行格式化,namenode的clusterID改变,就会愈datanode的cluseterID不一致,如果重启或者读写hdfs,就会挂掉
(2)dfs.datanode.data.dir file://${hadoop.tmp.dir}/dfs/data
hadoop.tmp.dir /tmp/hadoop-${user.name}
例:/tmp/hadoop-root/dfs目录下:
name、data、namesecondary
(3)dfs.namenode.checkpoint.dir file://{hadoop.tmp.dir}/dfs/namesecondary
tmp/hadoop-${user.name}/dfs/name或者 tmp/hadoop-${user.name}/dfs/data下的datanode和namenode信息在系统
在重启时,会被清空处理。为了防止数据丢失,接下来我们更改路径存储,以namenode为例:
配置hdfs信息如下:将namenode数据存储在data/name下面
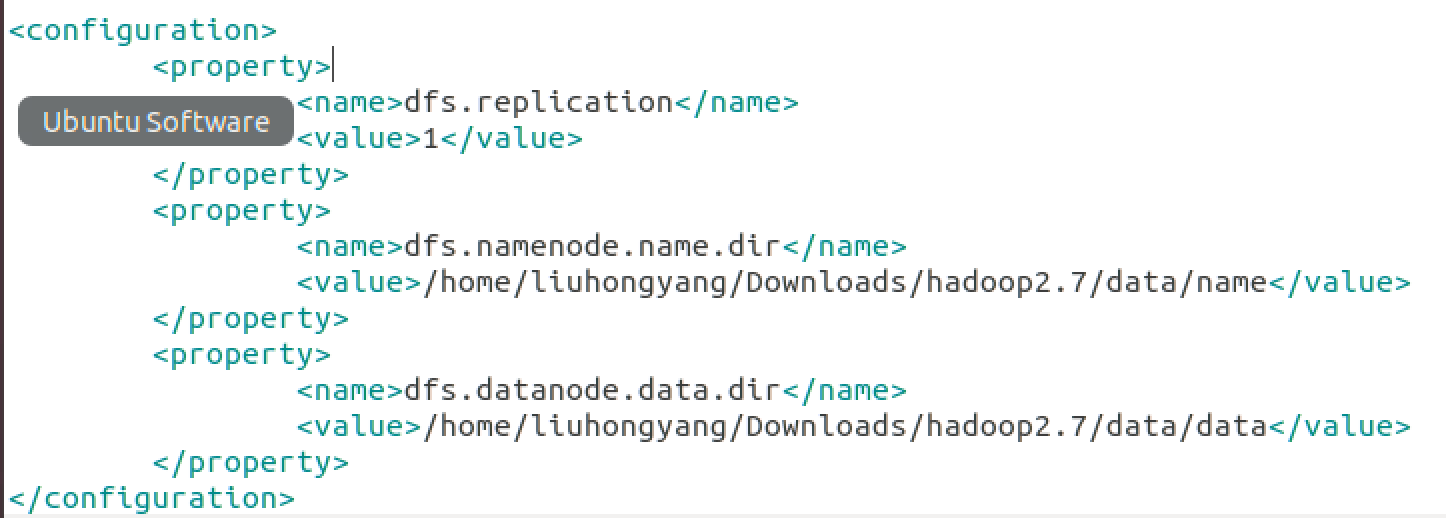
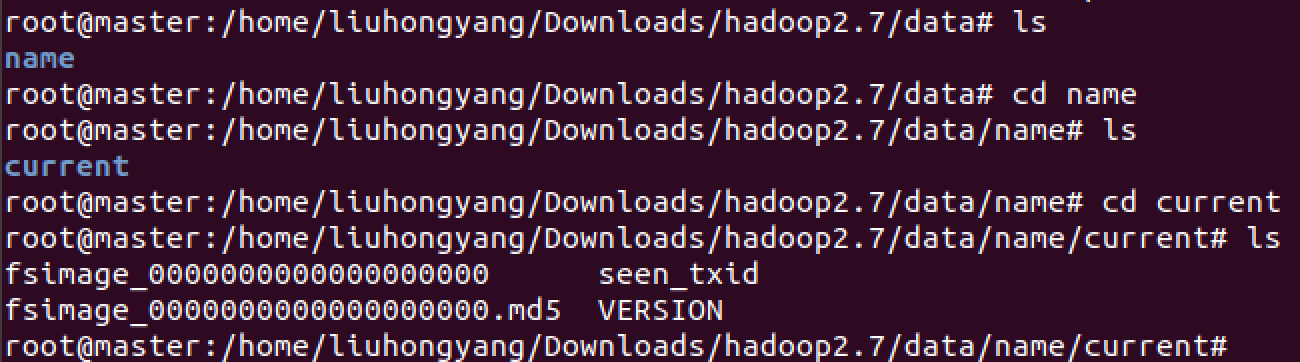
在执行格式化之前,查询data下的目录信息:

进行格式化:
hdfs namenode -format -force
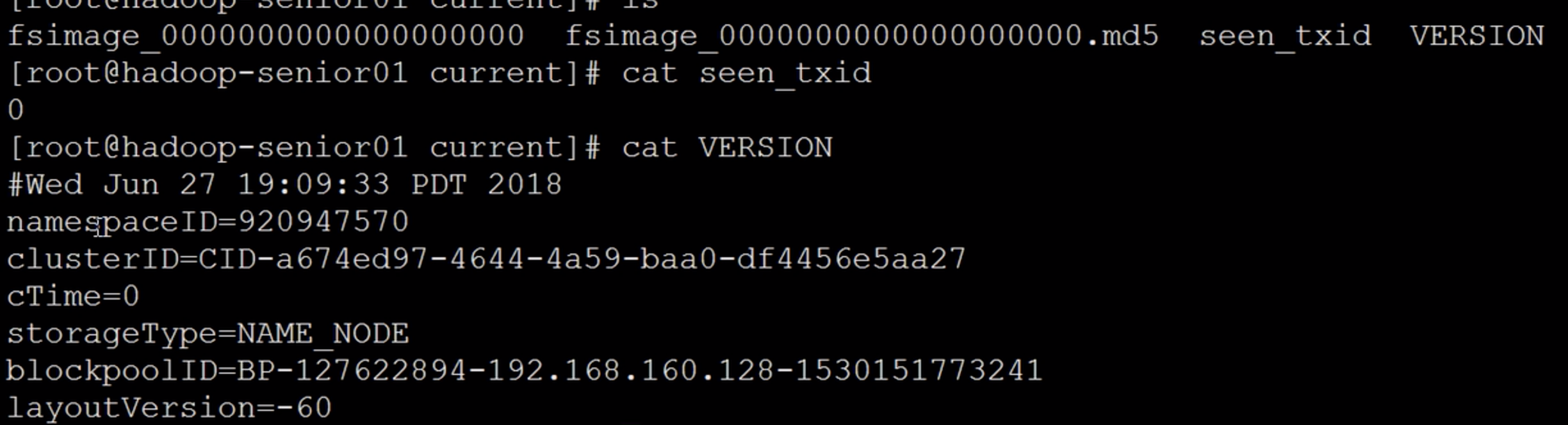
格式化之后,在data/name/current下查看name信息
最新文章
- 关于我们经常用到的form表单提交
- POJ 2420:A Star not a Tree?
- SQL语句 - 数据操作
- Android JNI之JAVA调用C/C++层
- C语言初学 比较五个整数并输出最大值和最小值1
- 多线程并发 synchronized对象锁的控制与优化
- spring mvc综合easyui点击上面菜单栏中的菜单项问题
- hdu_2224_The shortest path(dp)
- NSDateFormatter调整时间格式的代码
- 树莓派小车(三)Python控制小车
- JFFS2 文件系统及新特性介绍
- Python爬虫从入门到进阶(3)之requests的使用
- 2019-01-13 [日常]mov文件转换为gif
- bzoj 1067: [SCOI2007]降雨量 (离散化+线段树)
- PAT Basic 1069. 微博转发抽奖(20)
- Linux跨服务器发送文件
- 开窗函数 函数() OVER()
- android的消息处理机制(图文+源码分析)—Looper/Handler/Message[转]
- SQLSERVER STANDARD 版本不支持内存数据库
- 流行的FPGA的上电复位