自然语言处理(五)——实现机器翻译Seq2Seq完整经过
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
我只能说这本书太烂了,看完这本书中关于自然语言处理的内容,代码全部敲了一遍,感觉学的很绝望,代码也运行不了。
具体原因,我也写过一篇博客diss过这本书。可是既然学了,就要好好学呀。为了搞懂自然语言处理,我毅然决然的学习了网上的各位小伙伴的博客。这里是我学习的简要过程,和代码,以及运行结果。大家共勉。
参考链接:
目录
学习过程:
0. 数据准备
我用的数据就是参考链接里面的数据。即一个TED 演讲的中英字幕。
下载地址:
https://wit3.fbk.eu/mt.php?release=2015-01
1. 数据切片
简单来说,就是,我们得到的文件里面都是自然语言,“今天天气很好。”这样的句子。我们首先要做的就是要将这些句子里的每一个字以及标点符号,用空格隔开。所以第一步就是利用工具进行文本切片。(具体方法看链接,这里不赘述)
我们要进行处理的文件是下面两个。

但是在这两个文件里面除了演讲内容中英文之外,还有关于演讲主题的一些信息,如下图。
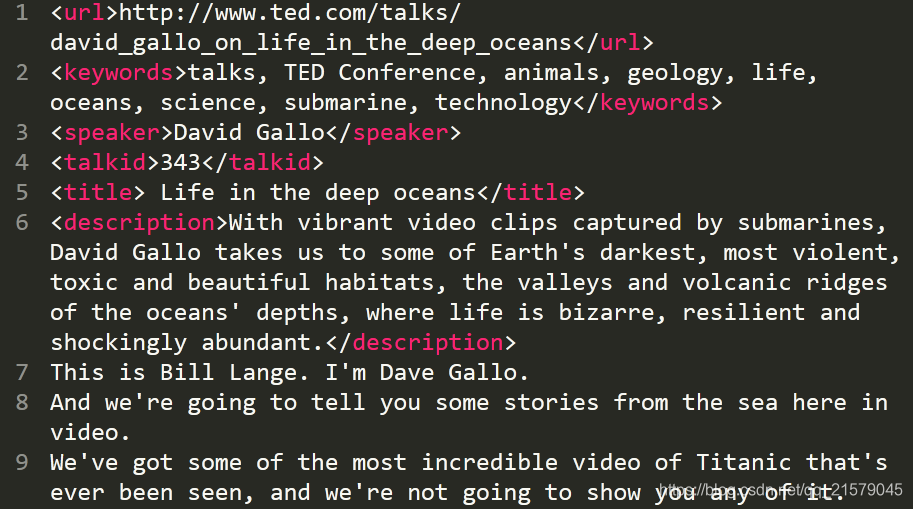
我用正则表达式的方法(现百度现用)去除了这些介绍部分的文字。英文和中文只需要改变名字和路径就行了,下面贴代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: file_deal.py
@time: 2019/3/19 11:05
@desc: 对两个文件进行处理,将两个文件中的表头信息清除
"""
import re
def txt_clean(x):
pattern = re.compile(r'<\w*>|</\w*>')
result = pattern.search(x)
return result
def main():
path = 'D:/Python3Space/Seq2SeqLearning/en-zh/'
# file = 'train.tags.en-zh.en'
# save_path = 'D:/Python3Space/Seq2SeqLearning/train.en'
file = 'train.tags.en-zh.zh'
save_path = 'D:/Python3Space/Seq2SeqLearning/train.zh'
path1 = path + file
output = open(save_path, 'w', encoding='utf-8')
with open(path1, 'r', encoding='utf-8') as f:
x = f.readlines()
for y in x:
result = txt_clean(y)
# print(result)
if result is None:
# print(y)
output.write(y)
output.close()
if __name__ == '__main__':
main()
运行这个程序就能得到两个文件,分别是去除了介绍文字部分的英文和中文翻译:

内容如下(我不知道为什么截图之后图片变窄了,很难受):
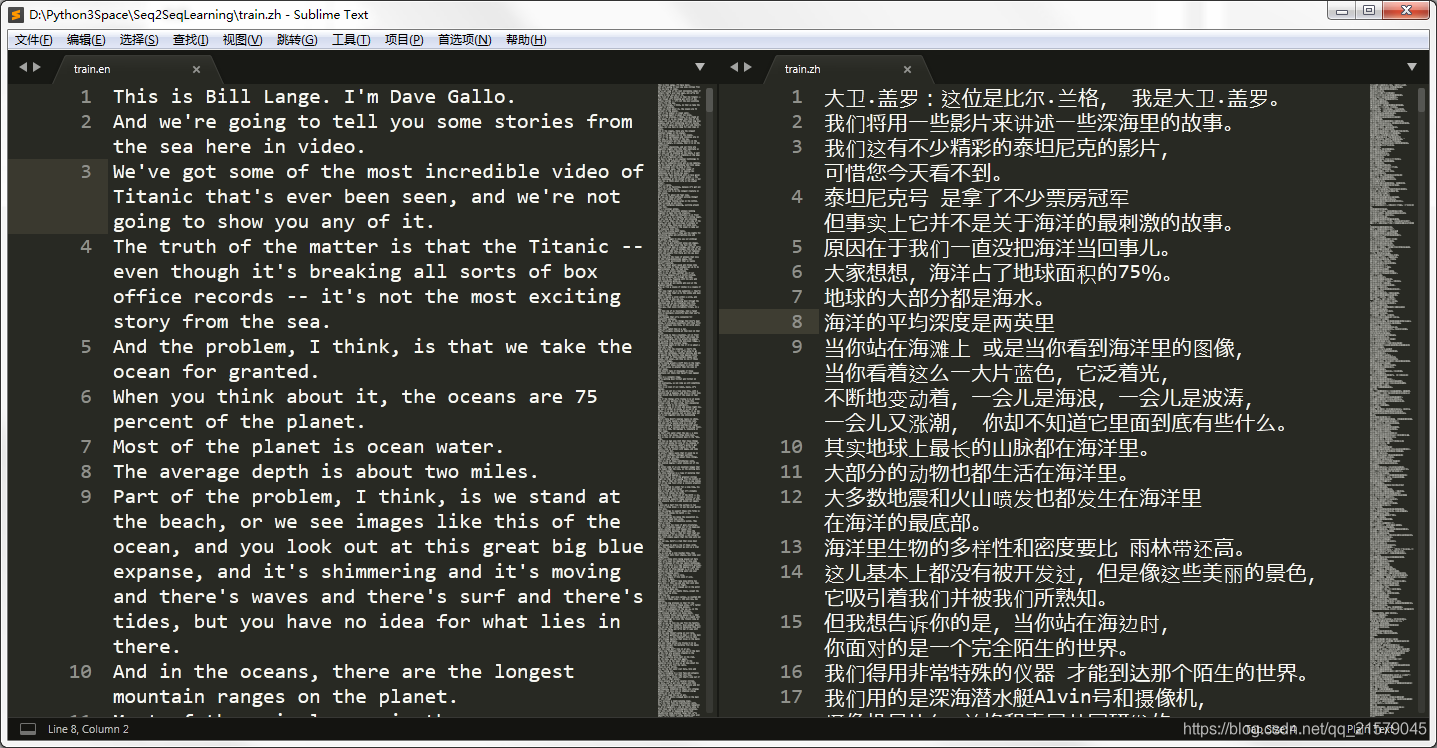
接下来我们需要有那种每个元素都是由空格所分开的(包括所有符号)。在这里,我选取的中文和英文的分词工具都是stanfordcorenlp,相关知识请参考这篇博客。
很绝望的是,我安装过程中Python还报错了:
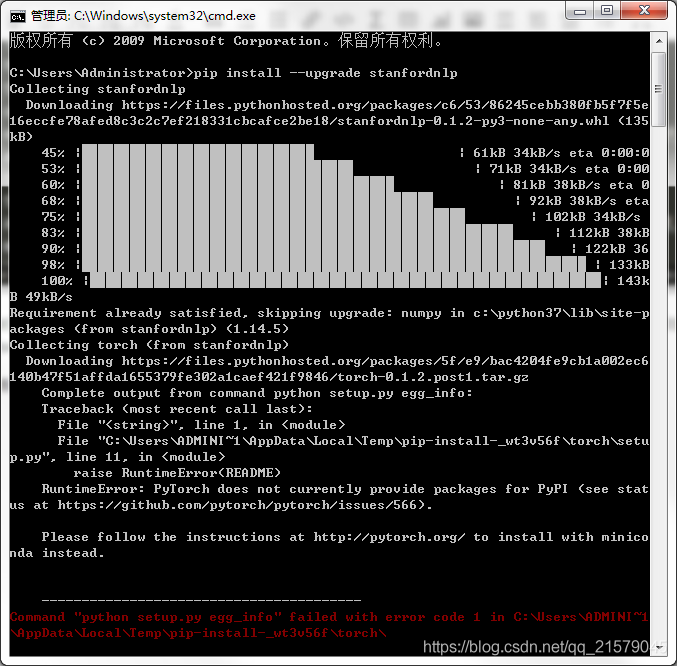
所以我借鉴知乎上面的回答解决了这个问题。
为什么要选用斯坦福的工具???
明明可以用nltk来对英文进行分词,用jieba对中文进行分词,可是当我搜到斯坦福这个自然语言处理工具的时候,我想了想,天啦,这个名字也太酷炫了吧,一看就很复杂啊,中英文用同一个库进行分词应该要比较好吧,我要搞定它。然后按照网上的教程,真的很容易的就安装了,然后很容易的就是实现对英文的分词了。可是!真的有毒吧!对中文进行分词的时候,我特么输出的是['', '', '', '']这种空值,无论怎么解决都没有办法,我真的要崩溃了。还好我看到了这篇文章。嗯。。。写的非常不错,竟然有我各种百度都没找到的解决办法,简直是太开心了好吗!可是!
里面写的 corenlp.py 到底在哪儿阿喂!
我哭了真的!
你们看,里面明明就只有一个叫corenlp.sh的文件好吗?打开之后里面也并不是知乎里面所说的内容啊!
在这个令人绝望的关头!我灵光一闪。。。.py!.py!莫不是在python库文件里面。。。然后我就立马去python3目录下找。

我是真的快乐,真的。。。特别是竟然出现了两个corenlp.py(虽然其中一个是nltk的啦,nltk是可以调用斯坦福的模块的,所以如果你百度的话,是可以查到如何用nlkt调用Stanfordcorenlp进行中文分词啊,语义解析啊等等的。我瞄了一眼一看就觉得不适合我哈哈!)
然后就顺利的根据上面知乎里的解决办法,替换了corenlp.py文件里面的某些关键字(具体内容点开上面的链接就知道啦)。
下面是我写的中英文分词的demo。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: seperate_word.py
@time: 2019/4/1 14:34
@desc: 对处理好的中英文数据进行分词操作(demo)
"""
from stanfordcorenlp import StanfordCoreNLP
sentence1 = "大家想想,海洋占了地球面积的75%。"
sentence2 = "When you think about it, the oceans are 75 percent of the planet."
nlp = StanfordCoreNLP('D:/python包/stanford-corenlp-full-2016-10-31', lang='zh')
nlp2 = StanfordCoreNLP('D:/python包/stanford-corenlp-full-2016-10-31', lang='en')
print(nlp.word_tokenize(sentence1))
print(nlp2.word_tokenize(sentence2))
运行之后得到:
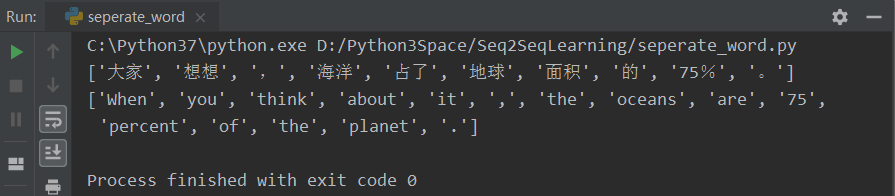
我现在是真的快乐!真的!真的是万事开头难,中间难,结尾难!
什么?你竟然不相信我会用jieba和nltk。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: seperate_word.py
@time: 2019/4/1 14:34
@desc: 对处理好的中英文数据进行分词操作(demo)
"""
from stanfordcorenlp import StanfordCoreNLP
import jieba
import nltk
# nltk.download("punkt")
sentence1 = "大家想想,海洋占了地球面积的75%。"
sentence2 = "When you think about it, the oceans are 75 percent of the planet."
# nlp = StanfordCoreNLP('D:/python包/stanford-corenlp-full-2016-10-31', lang='zh')
# nlp2 = StanfordCoreNLP('D:/python包/stanford-corenlp-full-2016-10-31', lang='en')
# print(nlp.word_tokenize(sentence1))
# print(nlp2.word_tokenize(sentence2))
seg_list = jieba.cut(sentence1, cut_all=False)
tokens = nltk.word_tokenize(sentence2)
print(list(seg_list))
print(tokens)
运行之后得到:

要记得在使用nltk工具包的时候,要下载对应的语言包,不然就会报错。也可以预先下载好所有的语言包,可是速度也太慢了吧,我还是用啥下啥好了。真的是巨慢。。。(下载完所有的好像得3、4个G)
那我给出大佬的解决办法,大家自行下载呀。(这里是punkt库)
如果想要所有的库,可以去官网下载,离线解压就完事儿了。
有了demo之后,我们就可以对中英文数据进行切片了:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: seperate_word_en.py
@time: 2019/4/7 15:37
@desc: 处理好的英文数据进行分词操作
"""
from stanfordcorenlp import StanfordCoreNLP
import time
path = 'D:/Python3Space/Seq2SeqLearning/'
en_path = path + 'train.en'
zh_path = path + 'train.zh'
nlp = StanfordCoreNLP('D:/python包/stanford-corenlp-full-2016-10-31', lang='zh')
# en = open(path + 'test.en', 'w', encoding='utf-8')
zh = open(path + 'test.zh', 'w', encoding='utf-8')
with open(zh_path, 'r', encoding='utf-8') as f:
data = f.readlines()
for text in data:
print(text)
if text != "\n":
fenci = nlp.word_tokenize(text)
sen = ' '.join(fenci)
zh.write(sen + '\n')
else:
zh.write('\n')
zh.close()
处理之后分别得到两个文件:
里面是已经处理好的句子,各个句子进行了切片处理,每个元素用空格隔开。
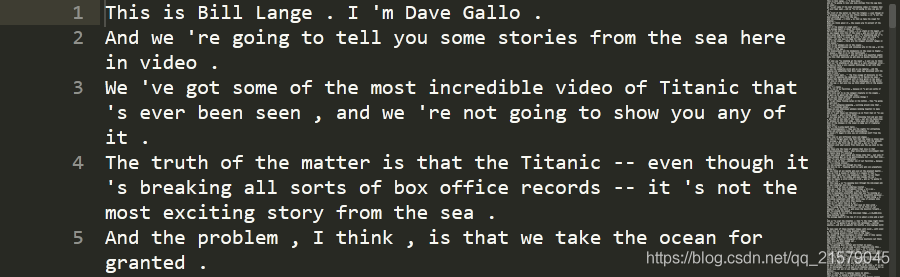

2. 数据集的预处理
为了将文本转化为模型可以读入的单词序列,需要将这4000个中文词汇,10000个英文词汇分别映射到0~9999之间的整数编号。
我们首先按照词频顺序确定词汇表,然后将词汇表保存到两个独立的vocab的文件中。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: statistic_word1.py
@time: 2019/4/22 9:36
@desc: 首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。
"""
import codecs
import collections
from operator import itemgetter
def deal(lang):
# 训练集数据文件
ROOT_PATH = "D:/Python3Space/Seq2SeqLearning/"
if lang == "zh":
RAW_DATA = ROOT_PATH + "test.zh"
# 输出的词汇表文件
VOCAB_OUTPUT = ROOT_PATH + "zh.vocab"
# 中文词汇表单词个数
VOCAB_SIZE = 4000
elif lang == "en":
RAW_DATA = ROOT_PATH + "test.en"
VOCAB_OUTPUT = ROOT_PATH + "en.vocab"
VOCAB_SIZE = 10000
else:
print("what?")
# 统计单词出现的频率
counter = collections.Counter()
with codecs.open(RAW_DATA, "r", "utf-8") as f:
for line in f:
for word in line.strip().split():
counter[word] += 1
# 按照词频顺序对单词进行排序
sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True)
sorted_words = [x[0] for x in sorted_word_to_cnt]
# 在后面处理机器翻译数据时,出了"<eos>",还需要将"<unk>"和句子起始符"<sos>"加入
# 词汇表,并从词汇表中删除低频词汇。在PTB数据中,因为输入数据已经将低频词汇替换成了
# "<unk>",因此不需要这一步骤。
sorted_words = ["<unk>", "<sos>", "<eos>"] + sorted_words
if len(sorted_words) > VOCAB_SIZE:
sorted_words = sorted_words[:VOCAB_SIZE]
with codecs.open(VOCAB_OUTPUT, 'w', 'utf-8') as file_output:
for word in sorted_words:
file_output.write(word + "\n")
if __name__ == "__main__":
# 处理的语言
lang = ["zh", "en"]
for i in lang:
deal(i)
处理之后分别得到两个文件:
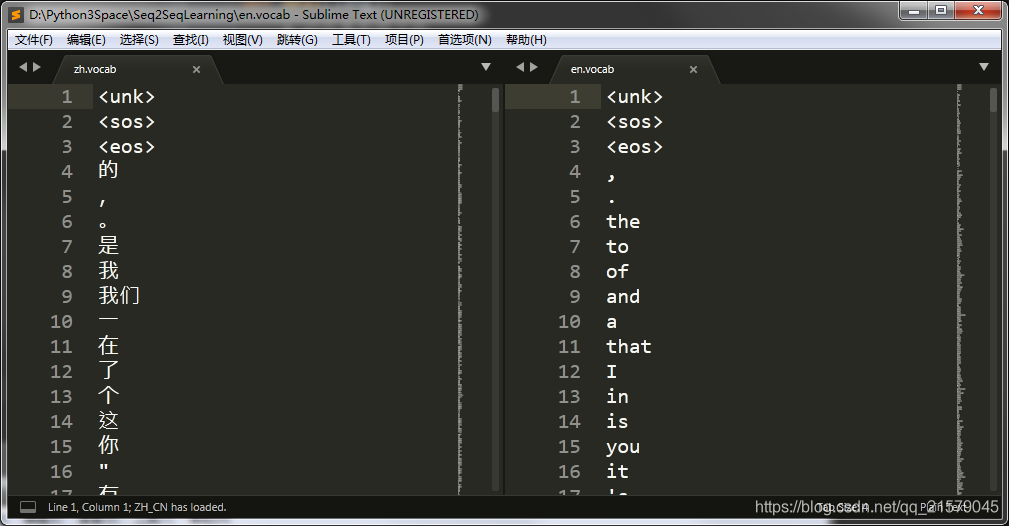
每个文件的内容如下:
在确定了词汇表之后,再讲训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件的行号。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: statistic_word2.py
@time: 2019/4/22 10:59
@desc: 在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。
"""
import codecs
def deal(lang):
# 训练集数据文件
ROOT_PATH = "D:/Python3Space/Seq2SeqLearning/"
if lang == "zh":
# 原始的训练集数据文件
RAW_DATA = ROOT_PATH + "test.zh"
# 上面生成的词汇表文件
VOCAB = ROOT_PATH + "zh.vocab"
# 将单词替换成为单词编号后的输出文件
OUTPUT_DATA = ROOT_PATH + "zh.number"
elif lang == "en":
RAW_DATA = ROOT_PATH + "test.en"
VOCAB = ROOT_PATH + "en.vocab"
OUTPUT_DATA = ROOT_PATH + "en.number"
else:
print("what?")
# 读取词汇表,并建立词汇到单词编号的映射。
with codecs.open(VOCAB, "r", "utf-8") as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
word_to_id = {k: v for (k, v) in zip(vocab, range(len(vocab)))}
# 如果出现了被删除的低频词,则替换为"<unk>"。
def get_id(word):
return word_to_id[word] if word in word_to_id else word_to_id["<unk>"]
fin = codecs.open(RAW_DATA, "r", "utf-8")
fout = codecs.open(OUTPUT_DATA, 'w', 'utf-8')
for line in fin:
# 读取单词并添加<eos>结束符
words = line.strip().split() + ["<eos>"]
# 将每个单词替换为词汇表中的编号
out_line = ' '.join([str(get_id(w)) for w in words]) + '\n'
fout.write(out_line)
fin.close()
fout.close()
if __name__ == "__main__":
# 处理的语言
lang = ["zh", "en"]
for i in lang:
deal(i)
在这里我不得不说一句!
我是真的看不懂这句代码
words = ["<sos>"] + line.strip().split() + ["<eos>"]
这句代码是我写的,但是在参考书中,还是我参考的别人的博客中。他们的都是下面这句
words = line.strip().split() + ["<eos>"]
书就不拍照了,嫌麻烦,别人的博客,我可以贴图为证:

我是真的佛了,书里面明明说的清清楚楚,我们讲道理
在后面处理机器翻译数据时,除了"<eos>",还需要将"<unk>"和句子起始符"<sos>"加入词汇表,并从词汇表中删除低频词汇。
我真的是找了全文,都没有看到哪里在每个句子的前面加了“<eos>”的,我才幡然醒悟,不就是在这里加入句子起始符吗?为啥句子结束符都加了,凭什么不加句子起始符啊。。。我真的是无语了,无话可说,搞不懂这些人的代码是怎么跑的通的。。。
对不起!上面写的都是放屁!
我希望所有跟我这样想的人,都要注意!这里只加<eos>是有道理的!,在下面batching的时候,会说为什么数据预处理的时候只在每个句子的后面加<eos>!
运行之后,就把原来的中英文文件,变成了两个中英文数字。
3. 数据的batching方法
在PTB的数据中,句子之间有上下文关联,因此可以直接将句子连接起来成为一个大的段落。
而在机器翻译的训练样本中,每个句子对通常都是作为独立的数据来训练的。由于每个句子的长短不一致,因此在将这些句子放到同一个batch时,需要将较短的句子补齐到与同 batch 内最长句子相同的长度。用于填充长度而填入的位置叫做填充(padding)。在TensorFlow中,tf.data.Dataset 的 padded_batch 函数可以解决这个问题。
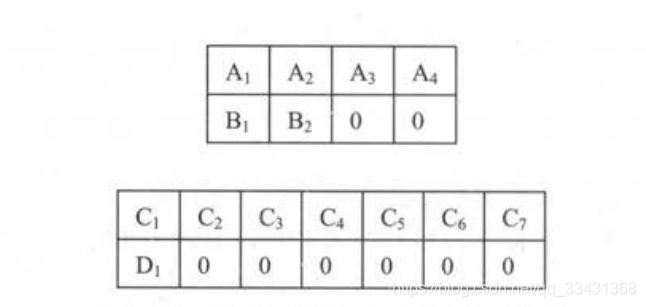
假设一个数据集中有4句话,分别是 ”A1A2A3A4”,“B1B2”,“C1C2C3C4C5C6C7”和“D1”,将它们加入必要的填充并组成大小为2 的batch后,得到的batch如下图所示:
循环神经网络在读取数据时会将填充位置的内容与其他内容一样纳入计算,因此为了不让填充影响训练,可能会影响训练结果和loss的计算,所以需要以下两个解决对策:
第一,循环神经网络在读取填充时,应当跳过这一位置的计算。以编码器为例,如果编码器在读取填充时,像正常输入一样处理填充输入,那么在读取"B1B200”之后产生的最后一位隐藏序列就和读取“B1B2”之后的隐藏状态不同,会产生错误的结果。通俗一点来说就是通过编码器预测,输入原始数据+padding数据产生的结果变了。
但是TensorFlow提供了 tf.nn.dynamic_rnn函数来很方便的实现这一功能,解决这个问题。dynamic_rnn 对每一个batch的数据读取两个输入。
①输入数据的内容(维度为[batch_size, time])
②输入数据的长度(维度为[time])
对于输入batch里的每一条数据,在读取了相应长度的内容后,dynamic_rnn就跳过后面的输入,直接把前一步的计算结果复制到后面的时刻。这样可以保证padding是否存在不影响模型效果。通俗来说就是用一个句子的长度也就是time来把控这一点。
并且使用dynamic_rnn时每个batch的最大序列长度不需要相同。例如上面的例子,batch大小为2,第一个batch的维度是2x4,而第二个batch的维度是2x7。在训练中dynamic_rnn会根据每个batch的最大长度动态展开到需要的层数,其实就是对每个batch本身的最大长度没有关系,函数会自动动态(dynamic)调整。
第二,在设计损失函数时需要特别将填充位置的损失权重设置为 0 ,这样在填充位置产生的预测不会影响梯度的计算。下面的代码使用
tf.data.Dataset.padded_batch来进行填充和 batching,并记录每个句子的序列长度以用作dynamic_rnn的输入。与上篇文章PTB的例子不同,这里没有将所有的数据读入内存,而是使用Dataset从磁盘动态读取数据。
没错,上面的我是抄的,抄的(别人抄书)的,为什么?
当然是因为我懒啊。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: statistic_word3.py
@time: 2019/4/22 15:13
@desc: 使用tf.data.Dataset.padded_batch来进行填充和batching,并记录每个句子的序列长度以用作dynamic_rnn的输入。
与前面PTB的例子不同,这里没有将所有数据读入内存,而是使用Dataset从磁盘动态读取数据。
"""
import tensorflow as tf
# 限定句子的最大单词数量
MAX_LEN = 50
# 目标语言词汇表中<sos>的ID
SOS_ID = 1
# 使用Dataset从一个文件中读取一个语言的数据
# 数据的格式为每行一句话,单词已经转化为单词的编号
def MakeDataset(file_path):
dataset = tf.data.TextLineDataset(file_path)
# 根据空格将单词编号切分开并放入一个一维向量
dataset = dataset.map(lambda string: tf.string_split([string]).values)
# 将字符串形式的单词编号转化为整数
dataset = dataset.map(lambda string: tf.string_to_number(string, tf.int32))
# 统计每个句子的单词数量,并与句子内容一起放入Dataset中。
dataset = dataset.map(lambda x: (x, tf.size(x)))
return dataset
# 从源语言文件src_path和目标语言文件trg_path中分别读取数据,并进行填充和batching操作
def MakeSrcTrgDataset(src_path, trg_path, batch_size):
# 首先分别读取源语言数据和目标语言数据。
src_data = MakeDataset(src_path)
trg_data = MakeDataset(trg_path)
# 通过zip操作将两个Dataset合并为一个Dataset。现在每个Dataset中每一项数据ds由4个张量组成。
# ds[0][0]是源句子
# ds[0][1]是源句子长度
# ds[1][0]是目标句子
# ds[1][1]是目标句子长度
dataset = tf.data.Dataset.zip((src_data, trg_data))
# 删除内容为空(只包含<eos>和<sos>)的句子和长度过长的句子
def FileterLength(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
src_len_ok = tf.logical_and(tf.greater(src_len, 1), tf.less_equal(src_len, MAX_LEN))
trg_len_ok = tf.logical_and(tf.greater(trg_len, 1), tf.less_equal(trg_len, MAX_LEN))
return tf.logical_and(src_len_ok, trg_len_ok)
dataset = dataset.filter(FileterLength)
# 解码器需要两种格式的目标句子:
# 1.解码器的输入(trg_input),形式如同"<sos> X Y Z"
# 2.解码器的目标输出(trg_label),形式如同"X Y Z <eos>"
# 上面从文件中读到的目标句子是"X Y Z <eos>"的形式,我们需要从中生成"<sos> X Y Z"
# 形式并加入到Dataset中。
def MakeTrgInput(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
trg_input = tf.concat([[SOS_ID], trg_label[:-1]], axis=0)
return (src_input, src_len), (trg_input, trg_label, trg_len)
dataset = dataset.map(MakeTrgInput)
# 随机打乱训练数据
dataset = dataset.shuffle(10000)
# 规定填充后输出的数据维度
padded_shapes = (
(tf.TensorShape([None]), # 源句子是长度未知的向量
tf.TensorShape([])), # 源句子长度是单个数字
(tf.TensorShape([None]), # 目标句子(解码器输入)是长度未知的向量
tf.TensorShape([None]), # 目标句子(解码器目标输出)是长度未知的向量
tf.TensorShape([])) # 目标句子长度是单个数字
)
# 调用padded_batch方法进行batching操作
batched_dataset = dataset.padded_batch(batch_size, padded_shapes)
return batched_dataset
你们看!这里就解释了上面所说的:为什么在数据预处理部分,只给每个句子的末尾加入<eos>!
# 解码器需要两种格式的目标句子:
# 1.解码器的输入(trg_input),形式如同"<sos> X Y Z"
# 2.解码器的目标输出(trg_label),形式如同"X Y Z <eos>"
# 上面从文件中读到的目标句子是"X Y Z <eos>"的形式,我们需要从中生成"<sos> X Y Z"
# 形式并加入到Dataset中。
至于为什么?别问!问我就是迷茫!反正我到现在已经被编码器,解码器输入,解码器输出给整糊涂了。有没有懂的大佬给解释一下!评论区等你!
我懂了!话不多说,一张图你就能懂!(知乎上的图,侵删)
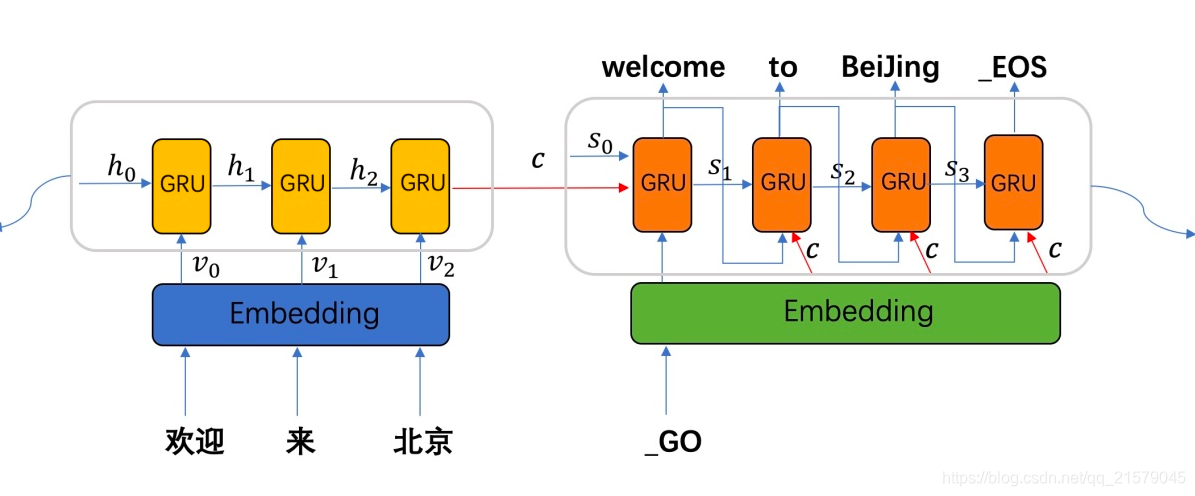
你们看右边的解码器!再配上我下面的这个图(这个是书上的图,但我从别人的博客上拔下来的哈哈)
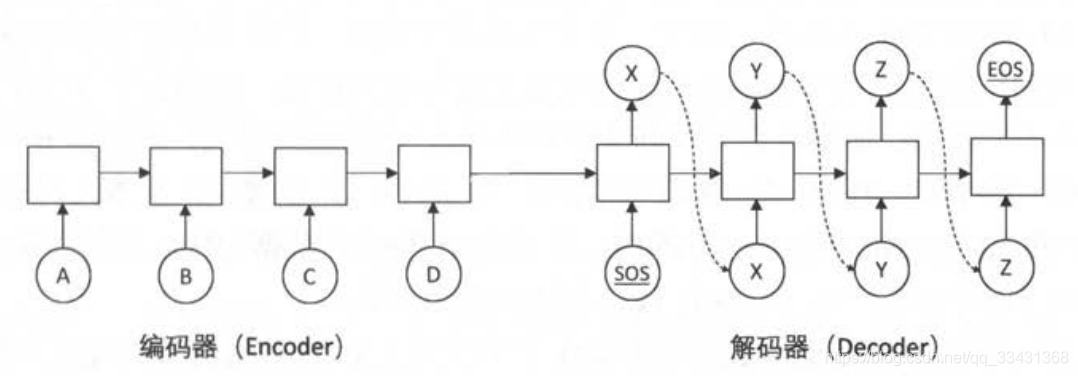
解码器输入的序列:<sos>, x, y, z
解码器输出的序列:x, y, z, <eos>
好,这个问题不用我再多说了吧,还是不懂的朋友,评论区见!
4. Seq2Seq模型的代码实现
4.1 模型训练
LSTM 作为循环神经网络的主体,并在 Softmax 层和词向量层之间共享参数,增加如下:
增加了一个循环神经网络作为编码器(如前面示意图)
使用 Dataset 动态读取数据,而不是直接将所有数据读入内存(这个就是Dataset输入数据的特点)
每个 batch 完全独立,不需要在batch之间传递状态(因为不是一个文件整条句子,每个句子之间没有传递关系)
每训练200步便将模型参数保存到一个 checkpoint 中,以后用于测试。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: statistic_word4.py
@time: 2019/4/23 9:50
@desc: 完整实现一个Seq2Seq模型。
"""
import tensorflow as tf
from translate.dynamic_rnn_test1 import MakeSrcTrgDataset
root_path = "D:/Python3Space/Seq2SeqLearning/"
# 输入数据已经转换成了单词编号的格式。
# 源语言输入文件
SRC_TRAIN_DATA = root_path + "en.number"
# 目标语言输入文件
TRG_TRAIN_DATA = root_path + "zh.number"
# checkpoint保存路径
CHECKPOINT_PATH = root_path + "seq2seq_ckpt"
# LSTM的隐藏层规模
HIDDEN_SIZE = 1024
# 深层循环神经网络中LSTM结构的层数
NUM_LAYERS = 2
# 源语言词汇表大小
SRC_VOCAB_SIZE = 10000
# 目标语言词汇表大小
TRG_VOCAB_SIZE = 4000
# 训练数据batch的大小
BATCH_SIZE = 100
# 使用训练数据的轮数
NUM_EPOCH = 5
# 节点不被dropout的概率
KEEP_PROB = 0.8
# 用于控制梯度膨胀的梯度大小上限
MAX_GRAD_NROM = 5
# 在Softmax层和词向量层之间共享参数
SHARE_EMB_AND_SOFTMAX = True
# 定义NMTModel类来描述模型
class NMTModel(object):
# 在模型的初始化函数中定义模型要用到的变量
def __init__(self):
# 定义编码器和解码器所使用的LSTM结构
self.enc_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
# 为源语言和目标语言分别定义词向量
self.src_embedding = tf.get_variable("src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 定义softmax层的变量
if SHARE_EMB_AND_SOFTMAX:
self.softmax_weight = tf.transpose(self.trg_embedding)
else:
self.softmax_weight = tf.get_variable("weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE])
self.softmax_bias = tf.get_variable("softmax_bias", [TRG_VOCAB_SIZE])
# 在forward函数中定义模型的前向计算图
# src_input, src_size, trg_input, trg_label, trg_size分别是上面MakeSrcTrgDataset函数产生的五种张量
def forward(self, src_input, src_size, trg_input, trg_label, trg_size):
batch_size = tf.shape(src_input)[0]
# 将输入和输出单词编号转为词向量
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
# 在词向量上进行dropout
src_emb = tf.nn.dropout(src_emb, KEEP_PROB)
trg_emb = tf.nn.dropout(trg_emb, KEEP_PROB)
# 使用dynamic构造编码器
# 编码器读取源句子每个位置的词向量,输出最后一步的隐藏状态enc_state
# 因为编码器是一个双层LSTM,因此enc_state是一个包含两个LSTMStateTuple类的tuple,每个LSTMStateTuple对应编码器中一层的状态。
# enc_outputs是顶层LSTM在每一步的输出,它的维度是[batch_size, max_time, HIDDEN_SIZE]。
# Seq2Seq模型中不需要用到enc_outputs,而在后面介绍的attention模型中会用到它。
with tf.variable_scope("encoder"):
enc_outputs, enc_state = tf.nn.dynamic_rnn(self.enc_cell, src_emb, src_size, dtype=tf.float32)
# 使用dynamic_rnn构造解码器
# 解码器读取目标句子每个位置的词向量,输出的dec_outputs为每一步顶层LSTM的输出。
# dec_outputs的维度是[batch_size, max_time, HIDDEN_SIZE]
# initial_state=enc_state表示用编码器的输出来初始化第一步的隐藏状态。
with tf.variable_scope("decoder"):
dec_outputs, _ = tf.nn.dynamic_rnn(self.dec_cell, trg_emb, trg_size, initial_state=enc_state)
# 计算解码器每一步的log perplexity。这一步与语言模型的代码相同。
output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE])
logits = tf.matmul(output, self.softmax_weight) + self.softmax_bias
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.reshape(trg_label, [-1]), logits=logits)
# 在计算平均损失时,需要将填充位置的权重设置为0,以避免无效位置的预测干扰模型的训练。
label_weights = tf.sequence_mask(trg_size, maxlen=tf.shape(trg_label)[1], dtype=tf.float32)
label_weights = tf.reshape(label_weights, [-1])
cost = tf.reduce_sum(loss * label_weights)
cost_per_token = cost / tf.reduce_sum(label_weights)
# 定义反向传播操作。反向操作的实现与语言模型代码相同。
trainable_variables = tf.trainable_variables()
# 控制梯度大小,定义优化方法和训练步骤。
grads = tf.gradients(cost / tf.to_float(batch_size), trainable_variables)
grads, _ = tf.clip_by_global_norm(grads, MAX_GRAD_NROM)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0)
train_op = optimizer.apply_gradients(zip(grads, trainable_variables))
return cost_per_token, train_op
# 使用给定的模型model上训练一个epoch,并返回全局步数
# 每训练200步便保存一个checkpoint
def run_epoch(session, cost_op, train_op, saver, step):
# 训练一个epoch
# 重复训练步骤直至遍历完Dataset中所有数据。
while True:
try:
# 运行train_op并计算损失值。训练数据在main()函数中以Dataset方式提供
cost, _ = session.run([cost_op, train_op])
if step % 10 == 0:
print("After %d steps, per token cost is %.3f" % (step, cost))
# 每200步保存一个checkoutpoint
if step % 200 == 0:
saver.save(session, CHECKPOINT_PATH, global_setp=step)
step += 1
except tf.errors.OutOfRangeError:
break
return step
def main():
# 定义初始化函数
initializer = tf.random_uniform_initializer(-0.05, 0.05)
# 定义训练用的循环神经网络模型
with tf.variable_scope("nmt_model", reuse=None, initializer=initializer):
train_model = NMTModel()
# 定义输入数据
data = MakeSrcTrgDataset(SRC_TRAIN_DATA, TRG_TRAIN_DATA, BATCH_SIZE)
iterator = data.make_initializable_iterator()
(src, src_size), (trg_input, trg_label, trg_size) = iterator.get_next()
# 定义输入数据
cost_op, train_op = train_model.forward(src, src_size, trg_input, trg_label, trg_size)
# 训练模型
saver = tf.train.Saver()
step = 0
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(NUM_EPOCH):
print("In iteration: %d" % (i + 1))
sess.run(iterator.initializer)
step = run_epoch(sess, cost_op, train_op, saver, step)
if __name__ == "__main__":
main()
我一直以来都有一个疑问:词向量究竟是啥意思,上述代码中的这段代码是啥意思?
# 为源语言和目标语言分别定义词向量
self.src_embedding = tf.get_variable("src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
参考:这个链接
下面是我对上面问题的理解啊,也不知道对不对,大家多担待:
- 首先,词向量有两种,一种是One-Hot Encoder,也就是以前常用的,当然现在也有用。
- 第二种,就是稠密向量,因为第一种每个词向量也太大了,如果词汇表有10000的话,那么对于某个词来说,它的词向量就是,一个1x10000的矩阵,其中的一个是1,其他9999都是0。
- 那么这第二种要怎么得到呢?(我的理解啊)就是用第一种方式转化得到的。第一种方法得到的词向量作为输入,然后经过一个10000 x hidden_layer(隐藏层大小)的矩阵,矩阵乘法得到1 x hidden_layer 的稠密矩阵,这个矩阵就是我所说的第二种词向量。
- 上述是我的理解,也不知道对不对。有大佬指点一下,我们就评论区见呗。
偷的别人博客中的图,侵删。。。
然后呢,我们再回到上面疑问的代码中来。
# 为源语言和目标语言分别定义词向量
self.src_embedding = tf.get_variable("src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
这部分代码定义的就是第一种词向量要乘的矩阵,shape是[词汇表大小,隐藏层]。
# 将输入和输出单词编号转为词向量
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
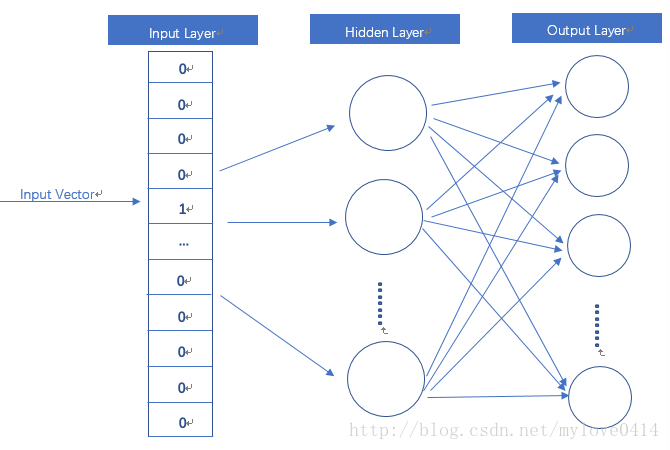
这一部分代码是计算第二种词向量的过程,虽然用的函数时tf.nn.embedding_lookup,实际上也就是矩阵乘法的意思。(附图,侵删)
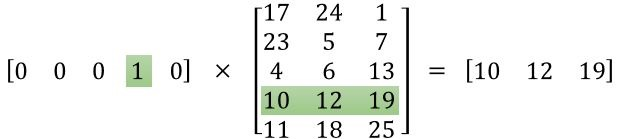
右边的就是我们所要求的的第二种词向量啦。(这里隐藏层是3,我们设置的隐藏层是1024,为什么?别问!问就是不知道!)
第二种词向量,也就是稠密词向量,有什么用呢!
如果隐藏层是二维,或者三维的,我们不就能绘制出每个词向量的图了吗!
比如说下面这个二维图:(网上拿的图,侵删)
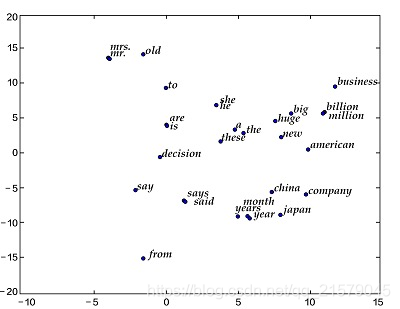
这不就能反映词与词之间的关系了!越接近的词,词义也越接近!
另外,在forward函数中定义模型的前向计算图中的代码好多根本没看懂。跑就完事儿了,构造编码器和解码器的过程我是真的蒙了。以后有新的想法,弄懂了之后再回来补充好了。
运行出来的结果如下:
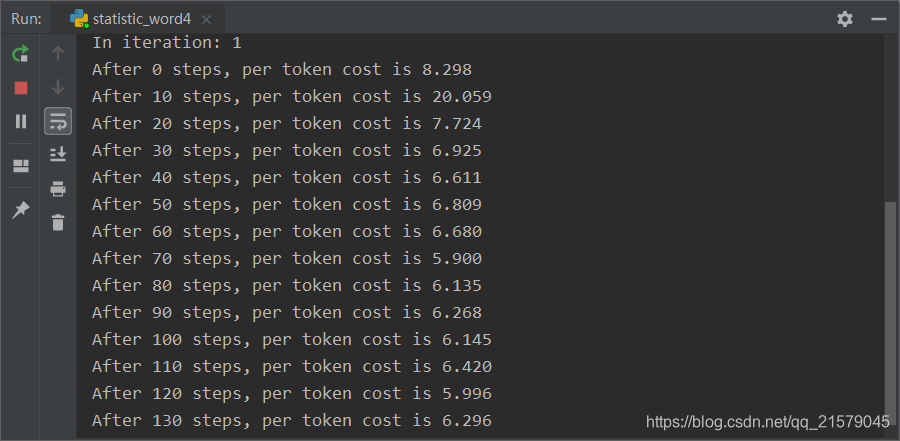
一万年过后。。。(没错,中途我还换了个电脑跑程序,跑了大概两天吧。。。)(这个截图我也是醉了的。。。)
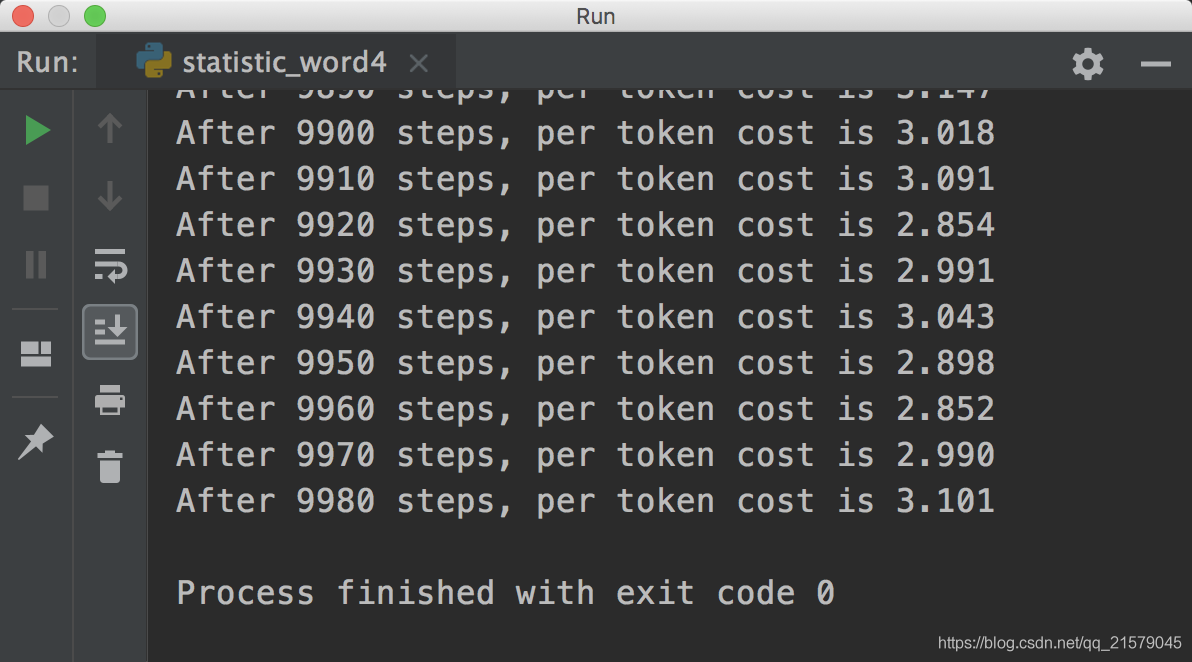
得到的模型如下:
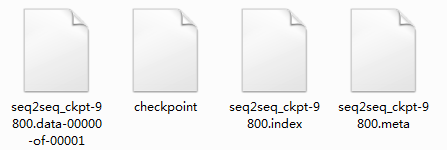
我保留了最后一个保存的模型(其他步保存的模型也有,但是太大太占位置了,就给删了,主要也就是用最后这个)
4.2 解码或推理程序
上面的程序完成了机器翻译模型的训练,并将训练好的模型保存在checkpoint中。
下面是讲解怎样从checkpoint中读取模型并对一个新的句子进行翻译。对新输入的句子进行翻译的过程也称为解码或推理。
在训练的时候解码器是可以从输入读取到完整的目标训练句子。
而在解码或推理的过程中模型只能看到输入句子,却看不到目标句子
具体过程:和图中描述的一样,解码器在第一步读取<sos> 符,预测目标句子的第一个单词,然后需要将这个预测的单词复制到第二步作为输入,再预测第二个单词,直到预测的单词为<eos>为止 。 这个过程需要使用一个循环结构来实现 。在TensorFlow 中,循环结构是由 tf.while_loop 来实现的 。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: statistic_word5.py
@time: 2019/4/29 10:39
@desc: 用tf.while_loop来实现解码过程
"""
import tensorflow as tf
import codecs
# 读取checkpoint的路径。9000表示是训练程序在第9000步保存的checkpoint
CHECKPOINT_PATH = "./seq2seq_ckpt-9800"
# 模型参数。必须与训练时的模型参数保持一致。
# LSTM的隐藏层规模
HIDDEN_SIZE = 1024
# 深层循环神经网络中LSTM结构的层数
NUM_LAYERS = 2
# 源语言词汇表大小
SRC_VOCAB_SIZE = 10000
# 目标语言词汇表大小
TRG_VOCAB_SIZE = 4000
# 在Softmax层和词向量层之间共享参数
SHARE_EMB_AND_SOFTMAX = True
# 词汇表中<sos>和<eos>的ID。在解码过程中需要用<sos>作为第一步的输入,并将检查是否是<eos>,因此需要知道这两个符号的ID
SOS_ID = 1
EOS_ID = 2
# 词汇表文件
SRC_VOCAB = "en.vocab"
TRG_VOCAB = "zh.vocab"
# 定义NMTModel类来描述模型
class NMTModel(object):
# 在模型的初始化函数中定义模型要用到的变量
def __init__(self):
# 与训练时的__init__函数相同。通常在训练程序和解码程序中复用NMTModel类以及__init__函数,以确保解码时和训练时定义的变量是相同的
# 定义编码器和解码器所使用的LSTM结构
self.enc_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
# 为源语言和目标语言分别定义词向量
self.src_embedding = tf.get_variable("src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 定义softmax层的变量
if SHARE_EMB_AND_SOFTMAX:
self.softmax_weight = tf.transpose(self.trg_embedding)
else:
self.softmax_weight = tf.get_variable("weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE])
self.softmax_bias = tf.get_variable("softmax_bias", [TRG_VOCAB_SIZE])
def inference(self, src_input):
# 虽然输入只有一个句子,但因为dynamic_rnn要求输入是batch的形式,因此这里将输入句子整理为大小为1的batch
src_size = tf.convert_to_tensor([len(src_input)], dtype=tf.int32)
src_input = tf.convert_to_tensor([src_input], dtype=tf.int32)
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
# 使用dynamic_rnn构造编码器。这一步与训练时相同
with tf.variable_scope("encoder"):
enc_outputs, enc_state = tf.nn.dynamic_rnn(self.enc_cell, src_emb, src_size, dtype=tf.float32)
# 设置解码的最大步数。这是为了避免在极端情况出现无限循环的问题。
MAX_DEC_LEN = 100
with tf.variable_scope("decoder/rnn/multi_rnn_cell"):
# 使用一个变长的TensorArray来存储生成的句子
init_array = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True, clear_after_read=False)
# 填入第一个单词<sos>作为解码器的输入
init_array = init_array.write(0, SOS_ID)
# 构建初始的循环状态。循环状态包含循环神经网络的隐藏状态,保存生成句子的TensorArray,以及记录解码步数的一个整数step
init_loop_var = (enc_state, init_array, 0)
# tf.while_loop的循环条件
# 循环直到解码器输出<eos>,或者达到最大步数为止。
def continue_loop_condition(state, trg_ids, step):
return tf.reduce_all(tf.logical_and(tf.not_equal(trg_ids.read(step), EOS_ID), tf.less(step, MAX_DEC_LEN-1)))
def loop_body(state, trg_ids, step):
# 读取最后一步输出的单词,并读取其词向量
trg_input = [trg_ids.read(step)]
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
# 这里不使用dynamic_rnn,而是直接调用dec_cell向前计算一步。
dec_outputs, next_state = self.dec_cell.call(state=state, inputs=trg_emb)
# 计算每个可能的输出单词对应的logit,并选取logit值最大的单词作为这一步的输出。
output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE])
logits = (tf.matmul(output, self.softmax_weight) + self.softmax_bias)
next_id = tf.argmax(logits, axis=1, output_type=tf.int32)
# 将这一步输出的单词写入循环状态的trg_ids中
trg_ids = trg_ids.write(step+1, next_id[0])
return next_state, trg_ids, step+1
# 执行tf.while_loop,返回最终状态
state, trg_ids, step = tf.while_loop(continue_loop_condition, loop_body, init_loop_var)
return trg_ids.stack()
def main():
# 定义训练用的循环神经网络模型
with tf.variable_scope("nmt_model", reuse=None):
model = NMTModel()
# 定义一个测试的例子
test_sentence = "This is a test ."
print(test_sentence)
# 根据英文词汇表,将测试句子转为单词ID。结尾加上<eos>的编号
test_sentence = test_sentence + " <eos>"
with codecs.open(SRC_VOCAB, 'r', 'utf-8') as vocab:
src_vocab = [w.strip() for w in vocab.readlines()]
# 运用dict,将单词和id对应起来组成字典,用于后面的转换
src_id_dict = dict((src_vocab[x], x) for x in range(SRC_VOCAB_SIZE))
test_en_ids = [(src_id_dict[en_text] if en_text in src_id_dict else src_id_dict['<unk>'])
for en_text in test_sentence.split()]
print(test_en_ids)
# 建立解码所需的计算图
output_op = model.inference(test_en_ids)
sess = tf.Session()
saver = tf.train.Saver()
saver.restore(sess, CHECKPOINT_PATH)
# 读取翻译结果
output_ids = sess.run(output_op)
print(output_ids)
# 根据中文词汇表,将翻译结果转换为中文文字。
with codecs.open(TRG_VOCAB, "r", "utf-8") as f_vocab:
trg_vocab = [w.strip() for w in f_vocab.readlines()]
output_text = ''.join([trg_vocab[x] for x in output_ids[1:-1]])
# 输出翻译结果
print(output_text)
sess.close()
if __name__ == "__main__":
main()
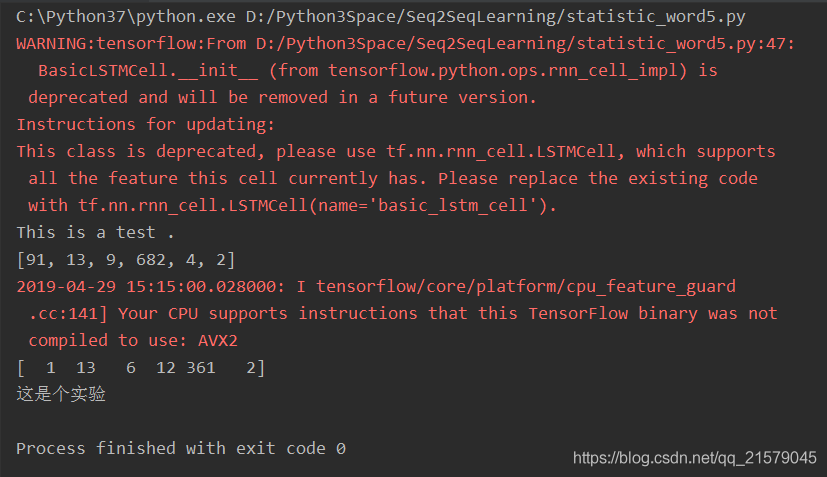
OK!终于大功告成。。。让我们来运行一下吧!
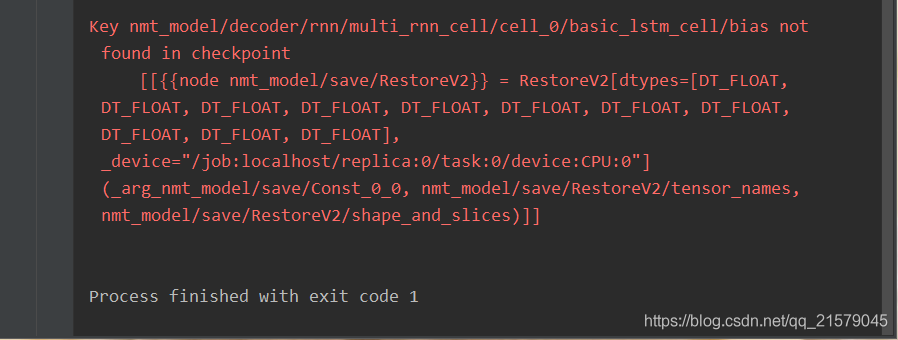
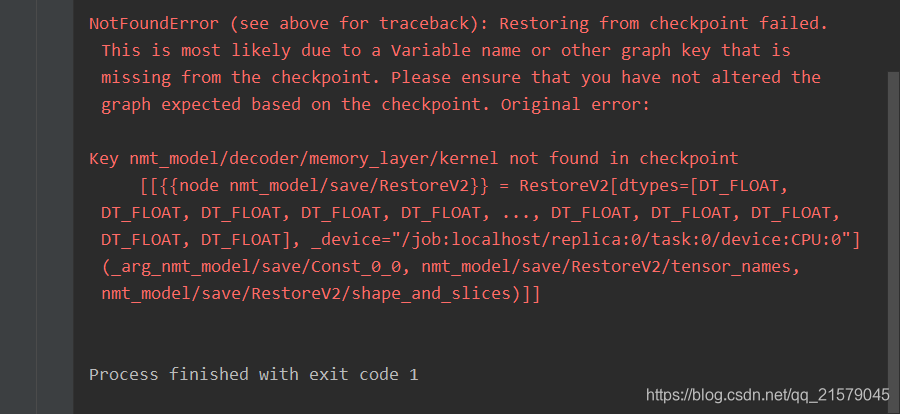
我哭了。真的。辛辛苦苦一顿操作,怎么就报错了?我研读了一下,发现上面说读取的模型与我们定义的变量名不一致,报错的变量名是
nmt_model/decoder/rnn/multi_rnn_cell/cell_0/basic_lstm_cell/bias
我去网上找了找解决办法。。。啥也没找到。算了,先想办法看一下模型里面的变量是什么。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: find_error.py
@time: 2019/4/29 12:17
@desc: 报错参数名字不一样,检查问题
"""
import os
from tensorflow.python import pywrap_tensorflow
model_dir = './'
checkpoint_path = os.path.join(model_dir, 'seq2seq_ckpt-9800')
reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path)
var_to_shape_map = reader.get_variable_to_shape_map()
for key in var_to_shape_map:
print("tensor_name: ", key)
print(reader.get_tensor(key))
运行后:
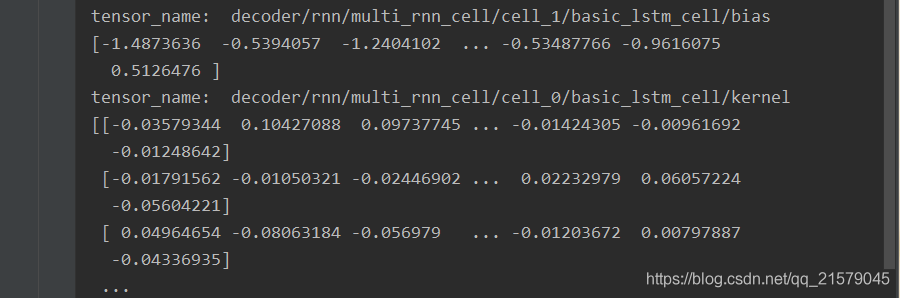
为什么!!!解码器和编码器的参数前面都少了一个nmt_model。。。(有大佬知道吗,求评论区解释一下,我现在还没搞懂。。。)
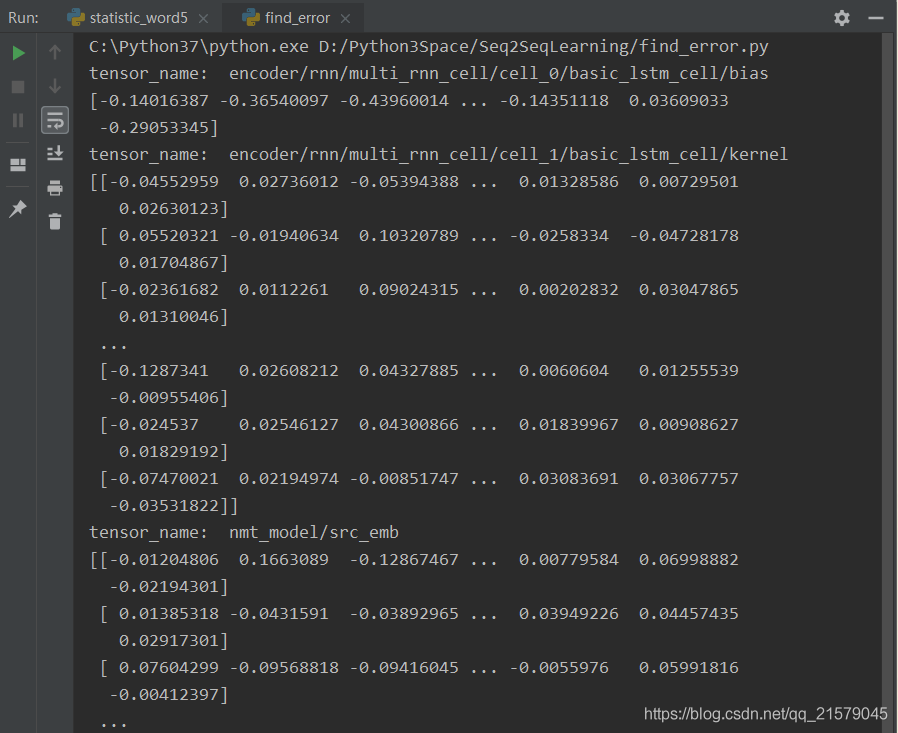
你们看其他的变量就正常的有nmt_model名。。。
我也是醉了。
然后我就去找有没有修改已训练模型变量名字的方法。。。
找了好久总算是让我找到了!
参考:干货!如何修改在TensorFlow框架下训练保存的模型参数名称
所以我们只需要把那些不知道为什么没有"nmt_model/"前缀的tensor_name给他们加上这个前缀就OK了,下面贴代码,我做了一定的修改
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: rename.py
@time: 2019/4/29 14:23
@desc: 修改TensorFlow训练保存的参数名
"""
import tensorflow as tf
import argparse
import os
parser = argparse.ArgumentParser(description='')
# 原参数路径
parser.add_argument("--checkpoint_path", default='./seq2seq_ckpt-9800', help="restore ckpt")
# 新参数保存路径
parser.add_argument("--new_checkpoint_path", default='./', help="path_for_new ckpt")
# 新参数名称中加入的前缀名
parser.add_argument("--add_prefix", default='nmt_model/', help="prefix for addition")
args = parser.parse_args()
l = ["encoder", "decoder"]
def main():
# 如果改之后的模型路径不存在就建立这个路径
if not os.path.exists(args.new_checkpoint_path):
os.makedirs(args.new_checkpoint_path)
with tf.Session() as sess:
# 新建一个空列表存储更新后的Variable变量
new_var_list = []
# 得到checkpoint文件中所有的参数(名字,形状)元组
for var_name, _ in tf.contrib.framework.list_variables(args.checkpoint_path):
# 得到上述参数的值
var = tf.contrib.framework.load_variable(args.checkpoint_path, var_name)
# 如果参数名是我们要修改的l中的两个中的一个,我们就在前面加上nmt_model/
if l[0] in var_name or l[1] in var_name:
new_name = var_name
# 在这里加入了名称前缀,大家可以自由地作修改
new_name = args.add_prefix + new_name
else:
new_name = var_name
# 除了修改参数名称,还可以修改参数值(var)
print('Renaming %s to %s.' % (var_name, new_name))
# 使用加入前缀的新名称重新构造了参数
renamed_var = tf.Variable(var, name=new_name)
# 把赋予新名称的参数加入空列表
new_var_list.append(renamed_var)
print('starting to write new checkpoint !')
# 构造一个保存器
saver = tf.train.Saver(var_list=new_var_list)
# 初始化一下参数(这一步必做)
sess.run(tf.global_variables_initializer())
# 构造一个保存的模型名称
model_name = 'new_seq2seq_ckpt'
# 构造一下保存路径
checkpoint_path = os.path.join(args.new_checkpoint_path, model_name)
# 直接进行保存
saver.save(sess, checkpoint_path)
print("done !")
if __name__ == '__main__':
main()
运行之后:
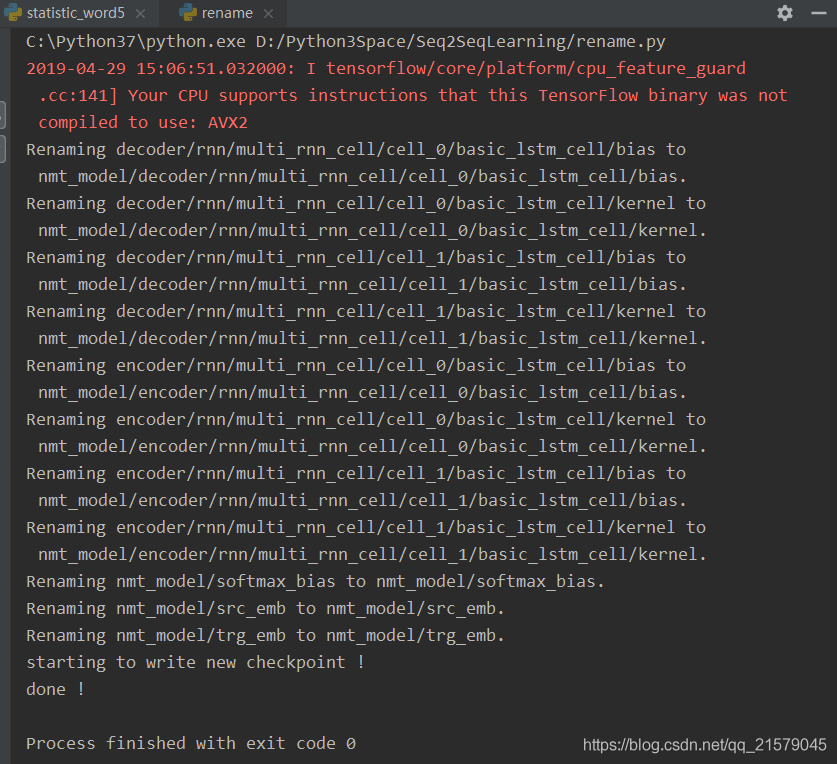
完事儿!开心!
我们再看一眼修改后模型的变量名是不是真的改了吧!(跟上面的代码一样,该个文件名,运行)
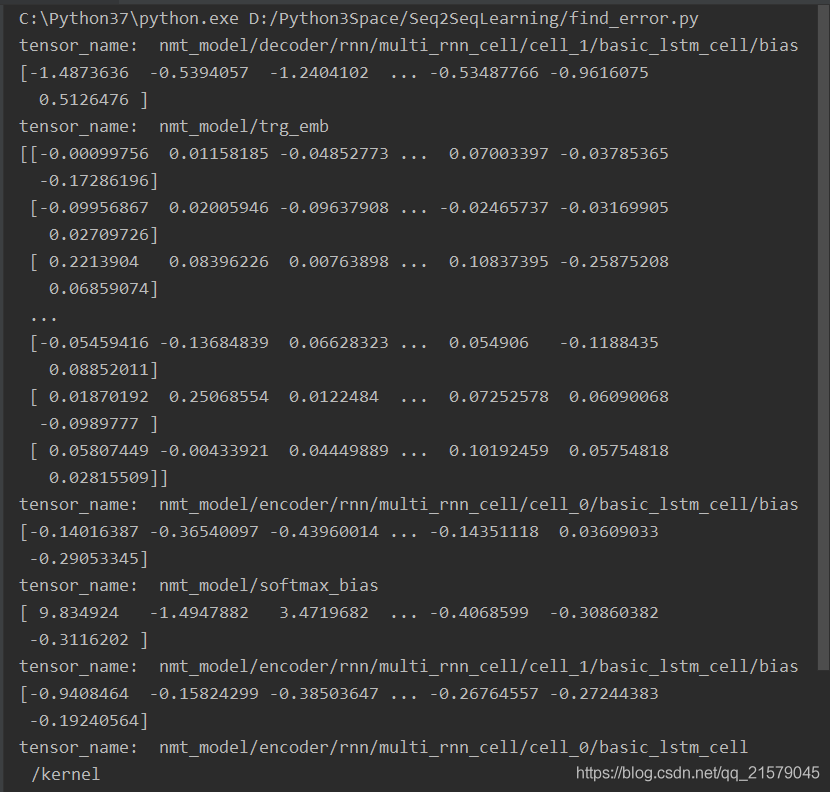
大功告成!!!
好,我们现在运行原来的翻译程序吧!!!(改成修改后的模型)
CHECKPOINT_PATH = "./new_seq2seq_ckpt"
欧耶!!!翻译成功!
5 Attention机制(注意力机制)
为什么需要Attention机制(参考链接)
最基本的seq2seq模型包含一个encoder和一个decoder,通常的做法是将一个输入的句子编码成一个固定大小的state,然后作为decoder的初始状态(当然也可以作为每一时刻的输入),但这样的一个状态对于decoder中的所有时刻都是一样的。
attention即为注意力,人脑在对于的不同部分的注意力是不同的。需要attention的原因是非常直观的,比如,我们期末考试的时候,我们需要老师划重点,划重点的目的就是为了尽量将我们的attention放在这部分的内容上,以期用最少的付出获取尽可能高的分数;再比如我们到一个新的班级,吸引我们attention的是不是颜值比较高的人?普通的模型可以看成所有部分的attention都是一样的,而这里的attention-based model对于不同的部分,重要的程度则不同。
其他细节就不赘述了,大家想要深入了解原理的话看参考链接。这里我主要弄代码部分。
加入attention机制后模型训练代码(部分内容做了修改):
1. 需要修改的部分主要是把原来编码器的多层rnn结构变成了一个双向的rnn:
# 前向
self.enc_cell_fw = tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE)
# 反向
self.enc_cell_bw = tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE)
2. forward函数中的"encoder"和"decoder"部分都做了些许的修改。这里就不贴代码了,大家一看便知。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: attention_train.py
@time: 2019/4/29 16:14
@desc: 注意力机制需要修改训练中的代码
"""
import tensorflow as tf
from Seq2SeqLearning.statistic_word3 import MakeSrcTrgDataset
root_path = "D:/Python3Space/Seq2SeqLearning/"
# 输入数据已经转换成了单词编号的格式。
# 源语言输入文件
SRC_TRAIN_DATA = root_path + "en.number"
# 目标语言输入文件
TRG_TRAIN_DATA = root_path + "zh.number"
# checkpoint保存路径
CHECKPOINT_PATH = root_path + "attention_ckpt"
# LSTM的隐藏层规模
HIDDEN_SIZE = 1024
# 深层循环神经网络中LSTM结构的层数
NUM_LAYERS = 2
# 源语言词汇表大小
SRC_VOCAB_SIZE = 10000
# 目标语言词汇表大小
TRG_VOCAB_SIZE = 4000
# 训练数据batch的大小
BATCH_SIZE = 100
# 使用训练数据的轮数
NUM_EPOCH = 5
# 节点不被dropout的概率
KEEP_PROB = 0.8
# 用于控制梯度膨胀的梯度大小上限
MAX_GRAD_NROM = 5
# 在Softmax层和词向量层之间共享参数
SHARE_EMB_AND_SOFTMAX = True
# 定义NMTModel类来描述模型,attention模型中 编码器双向循环,解码器单向循环
class NMTModel(object):
# 在模型的初始化函数中定义模型要用到的变量
def __init__(self):
# 定义编码器和解码器所使用的LSTM结构
# 前向
self.enc_cell_fw = tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE)
# 反向
self.enc_cell_bw = tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE)
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
# 为源语言和目标语言分别定义词向量
self.src_embedding = tf.get_variable("src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 定义softmax层的变量,只有解码器需要用到softmax
if SHARE_EMB_AND_SOFTMAX:
self.softmax_weight = tf.transpose(self.trg_embedding)
else:
self.softmax_weight = tf.get_variable("weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE])
self.softmax_bias = tf.get_variable("softmax_bias", [TRG_VOCAB_SIZE])
# 在forward函数中定义模型的前向计算图
# src_input, src_size, trg_input, trg_label, trg_size分别是上面MakeSrcTrgDataset函数产生的五种张量
def forward(self, src_input, src_size, trg_input, trg_label, trg_size):
batch_size = tf.shape(src_input)[0]
# 将输入和输出单词编号转为词向量
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
# 在词向量上进行dropout
src_emb = tf.nn.dropout(src_emb, KEEP_PROB)
trg_emb = tf.nn.dropout(trg_emb, KEEP_PROB)
# 使用dynamic构造编码器
# 编码器读取源句子每个位置的词向量,输出最后一步的隐藏状态enc_state
# 因为编码器是一个双层LSTM,因此enc_state是一个包含两个LSTMStateTuple类的tuple,每个LSTMStateTuple对应编码器中一层的状态。
# enc_outputs是顶层LSTM在每一步的输出,它的维度是[batch_size, max_time, HIDDEN_SIZE]。
# Seq2Seq模型中不需要用到enc_outputs,而在后面介绍的attention模型中会用到它。
with tf.variable_scope("encoder"):
# 构造编码器时,使用bidirectional_dynamic_rnn构造双向循环网络。
# 双向循环网络的顶层输出enc_outputs是一个包含两个张量的tuple,每个张量的
# 维度都是[batch_size, max_time, HIDDEN_SIZE],代表两个LSTM在每一步的输出。
enc_outputs, enc_state = tf.nn.bidirectional_dynamic_rnn(self.enc_cell_fw, self.enc_cell_bw, src_emb, src_size, dtype=tf.float32)
# 将两个LSTM的输出拼接为一个张量。
enc_outputs = tf.concat([enc_outputs[0], enc_outputs[1]], -1)
# 使用dynamic_rnn构造解码器
# 解码器读取目标句子每个位置的词向量,输出的dec_outputs为每一步顶层LSTM的输出。
# dec_outputs的维度是[batch_size, max_time, HIDDEN_SIZE]
# initial_state=enc_state表示用编码器的输出来初始化第一步的隐藏状态。
with tf.variable_scope("decoder"):
# 选择注意力权重的计算模型。BahdanauAttention是使用一个隐藏层的前馈网络。
# memory_sequence_length是一个维度为[batch_size]的张量,代表batch
# 中每个句子的长度,Attention需要根据这个信息把填充位置的注意力权重设置为0。
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(HIDDEN_SIZE, enc_outputs, memory_sequence_length=src_size)
# 将解码器的循环神经网络self.dec_cell和注意力一起封装成更高层的循环神经网络。
attention_cell = tf.contrib.seq2seq.AttentionWrapper(self.dec_cell, attention_mechanism, attention_layer_size=HIDDEN_SIZE)
# 使用attention_cell和dynamic_rnn构造编码器。
# 这里没有指定init_state,也就是没有使用编码器的输出来初始化输入,而完全依赖注意力作为信息来源。
dec_outputs, _ = tf.nn.dynamic_rnn(attention_cell, trg_emb, trg_size, dtype=tf.float32)
# 计算解码器每一步的log perplexity。这一步与语言模型的代码相同。
output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE])
logits = tf.matmul(output, self.softmax_weight) + self.softmax_bias
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.reshape(trg_label, [-1]), logits=logits)
# 在计算平均损失时,需要将填充位置的权重设置为0,以避免无效位置的预测干扰模型的训练。
label_weights = tf.sequence_mask(trg_size, maxlen=tf.shape(trg_label)[1], dtype=tf.float32)
label_weights = tf.reshape(label_weights, [-1])
cost = tf.reduce_sum(loss * label_weights)
cost_per_token = cost / tf.reduce_sum(label_weights)
# 定义反向传播操作。反向操作的实现与语言模型代码相同。
trainable_variables = tf.trainable_variables()
# 控制梯度大小,定义优化方法和训练步骤。
grads = tf.gradients(cost / tf.to_float(batch_size), trainable_variables)
grads, _ = tf.clip_by_global_norm(grads, MAX_GRAD_NROM)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0)
train_op = optimizer.apply_gradients(zip(grads, trainable_variables))
return cost_per_token, train_op
# 使用给定的模型model上训练一个epoch,并返回全局步数
# 每训练200步便保存一个checkpoint
def run_epoch(session, cost_op, train_op, saver, step):
# 训练一个epoch
# 重复训练步骤直至遍历完Dataset中所有数据。
while True:
try:
# 运行train_op并计算损失值。训练数据在main()函数中以Dataset方式提供
cost, _ = session.run([cost_op, train_op])
if step % 10 == 0:
print("After %d steps, per token cost is %.3f" % (step, cost))
# 每200步保存一个checkoutpoint
if step % 200 == 0:
saver.save(session, CHECKPOINT_PATH, global_step=step)
step += 1
except tf.errors.OutOfRangeError:
break
return step
def main():
# 定义初始化函数
initializer = tf.random_uniform_initializer(-0.05, 0.05)
# 定义训练用的循环神经网络模型
with tf.variable_scope("nmt_model", reuse=None, initializer=initializer):
train_model = NMTModel()
# 定义输入数据
data = MakeSrcTrgDataset(SRC_TRAIN_DATA, TRG_TRAIN_DATA, BATCH_SIZE)
iterator = data.make_initializable_iterator()
(src, src_size), (trg_input, trg_label, trg_size) = iterator.get_next()
# 定义前向计算图。输入数据以张量形式提供给forward函数。
cost_op, train_op = train_model.forward(src, src_size, trg_input, trg_label, trg_size)
# 训练模型
saver = tf.train.Saver()
step = 0
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(NUM_EPOCH):
print("In iteration: %d" % (i + 1))
sess.run(iterator.initializer)
step = run_epoch(sess, cost_op, train_op, saver, step)
if __name__ == "__main__":
main()
跑模型实在是太耗时了,我挂了一夜就跑了2800步,旨在学习,就不像上面那样跑两天两夜了。
运行结果:
我们就将就着2800步的模型用起来了。
加入attention机制后模型解码代码(部分内容做了修改,这里就不贴哪里修改了,跟训练模型需要修改的地方相似):
在这里我们要注意,解码的时候初始状态并不是之前编码器最后的隐藏状态,而是什么都没有的初始状态:
init_loop_var = (attention_cell.zero_state(batch_size=1, dtype=tf.float32), init_array, 0)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: attention_decoding.py
@time: 2019/4/29 16:35
@desc: 注意力机制需要修改解码中的代码
"""
import tensorflow as tf
import codecs
# 读取checkpoint的路径。9000表示是训练程序在第9000步保存的checkpoint
CHECKPOINT_PATH = "./attention_ckpt-2800"
# 模型参数。必须与训练时的模型参数保持一致。
# LSTM的隐藏层规模
HIDDEN_SIZE = 1024
# 深层循环神经网络中LSTM结构的层数
NUM_LAYERS = 2
# 源语言词汇表大小
SRC_VOCAB_SIZE = 10000
# 目标语言词汇表大小
TRG_VOCAB_SIZE = 4000
# 在Softmax层和词向量层之间共享参数
SHARE_EMB_AND_SOFTMAX = True
# 词汇表中<sos>和<eos>的ID。在解码过程中需要用<sos>作为第一步的输入,并将检查是否是<eos>,因此需要知道这两个符号的ID
SOS_ID = 1
EOS_ID = 2
# 词汇表文件
SRC_VOCAB = "en.vocab"
TRG_VOCAB = "zh.vocab"
# 定义NMTModel类来描述模型
class NMTModel(object):
# 在模型的初始化函数中定义模型要用到的变量
def __init__(self):
# 与训练时的__init__函数相同。通常在训练程序和解码程序中复用NMTModel类以及__init__函数,以确保解码时和训练时定义的变量是相同的
# 定义编码器和解码器所使用的LSTM结构
# 前向
self.enc_cell_fw = tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE)
# 反向
self.enc_cell_bw = tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE)
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
# 为源语言和目标语言分别定义词向量
self.src_embedding = tf.get_variable("src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 定义softmax层的变量
if SHARE_EMB_AND_SOFTMAX:
self.softmax_weight = tf.transpose(self.trg_embedding)
else:
self.softmax_weight = tf.get_variable("weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE])
self.softmax_bias = tf.get_variable("softmax_bias", [TRG_VOCAB_SIZE])
def inference(self, src_input):
# 虽然输入只有一个句子,但因为dynamic_rnn要求输入是batch的形式,因此这里将输入句子整理为大小为1的batch
src_size = tf.convert_to_tensor([len(src_input)], dtype=tf.int32)
src_input = tf.convert_to_tensor([src_input], dtype=tf.int32)
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
# 构造编码器时,使用bidirectional_dynamic_rnn构造双向循环网络。这一步与训练时相同
with tf.variable_scope("encoder"):
# 构造编码器时,使用bidirectional_dynamic_rnn构造双向循环网络。
# 双向循环网络的顶层输出enc_outputs是一个包含两个张量的tuple,每个张量的
# 维度都是[batch_size, max_time, HIDDEN_SIZE],代表两个LSTM在每一步的输出。
enc_outputs, enc_state = tf.nn.bidirectional_dynamic_rnn(self.enc_cell_fw, self.enc_cell_bw, src_emb, src_size, dtype=tf.float32)
# 将两个LSTM的输出拼接为一个张量。
enc_outputs = tf.concat([enc_outputs[0], enc_outputs[1]], -1)
with tf.variable_scope("decoder"):
# 选择注意力权重的计算模型。BahdanauAttention是使用一个隐藏层的前馈网络。
# memory_sequence_length是一个维度为[batch_size]的张量,代表batch
# 中每个句子的长度,Attention需要根据这个信息把填充位置的注意力权重设置为0。
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(HIDDEN_SIZE, enc_outputs, memory_sequence_length=src_size)
# 将解码器的循环神经网络self.dec_cell和注意力一起封装成更高层的循环神经网络。
attention_cell = tf.contrib.seq2seq.AttentionWrapper(self.dec_cell, attention_mechanism, attention_layer_size=HIDDEN_SIZE)
# 设置解码的最大步数。这是为了避免在极端情况出现无限循环的问题。
MAX_DEC_LEN = 100
with tf.variable_scope("decoder/rnn/attention_wrapper"):
# 使用一个变长的TensorArray来存储生成的句子
init_array = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True, clear_after_read=False)
# 填入第一个单词<sos>作为解码器的输入
init_array = init_array.write(0, SOS_ID)
# 构建初始的循环状态。循环状态包含循环神经网络的隐藏状态,保存生成句子的TensorArray,以及记录解码步数的一个整数step
init_loop_var = (attention_cell.zero_state(batch_size=1, dtype=tf.float32), init_array, 0)
# tf.while_loop的循环条件
# 循环直到解码器输出<eos>,或者达到最大步数为止。
def continue_loop_condition(state, trg_ids, step):
return tf.reduce_all(tf.logical_and(tf.not_equal(trg_ids.read(step), EOS_ID), tf.less(step, MAX_DEC_LEN-1)))
def loop_body(state, trg_ids, step):
# 读取最后一步输出的单词,并读取其词向量
trg_input = [trg_ids.read(step)]
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
# 这里不使用dynamic_rnn,而是直接调用dec_cell向前计算一步。
dec_outputs, next_state = attention_cell.call(state=state, inputs=trg_emb)
# 计算每个可能的输出单词对应的logit,并选取logit值最大的单词作为这一步的输出。
output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE])
logits = (tf.matmul(output, self.softmax_weight) + self.softmax_bias)
next_id = tf.argmax(logits, axis=1, output_type=tf.int32)
# 将这一步输出的单词写入循环状态的trg_ids中
trg_ids = trg_ids.write(step+1, next_id[0])
return next_state, trg_ids, step+1
# 执行tf.while_loop,返回最终状态
state, trg_ids, step = tf.while_loop(continue_loop_condition, loop_body, init_loop_var)
return trg_ids.stack()
def main():
# 定义训练用的循环神经网络模型
with tf.variable_scope("nmt_model", reuse=None):
model = NMTModel()
# 定义一个测试的例子
test_sentence = "This is a test ."
print(test_sentence)
# 根据英文词汇表,将测试句子转为单词ID。结尾加上<eos>的编号
test_sentence = test_sentence + " <eos>"
with codecs.open(SRC_VOCAB, 'r', 'utf-8') as vocab:
src_vocab = [w.strip() for w in vocab.readlines()]
# 运用dict,将单词和id对应起来组成字典,用于后面的转换
src_id_dict = dict((src_vocab[x], x) for x in range(SRC_VOCAB_SIZE))
test_en_ids = [(src_id_dict[en_text] if en_text in src_id_dict else src_id_dict['<unk>'])
for en_text in test_sentence.split()]
print(test_en_ids)
# 建立解码所需的计算图
output_op = model.inference(test_en_ids)
sess = tf.Session()
saver = tf.train.Saver()
saver.restore(sess, CHECKPOINT_PATH)
# 读取翻译结果
output_ids = sess.run(output_op)
print(output_ids)
# 根据中文词汇表,将翻译结果转换为中文文字。
with codecs.open(TRG_VOCAB, "r", "utf-8") as f_vocab:
trg_vocab = [w.strip() for w in f_vocab.readlines()]
output_text = ''.join([trg_vocab[x] for x in output_ids[1:-1]])
# 输出翻译结果
print(output_text)
sess.close()
if __name__ == "__main__":
main()
OK!来吧,运行吧!!!
???我绝望了。。。又跟上面的一样???我酸了。。。
又是变量名的原因??
行吧,这次我就不用上面的解决办法了,不改模型了,我要修改解码代码中的变量名。。。
1. 首先去掉主函数的模型名,然后下面的代码缩进。这样所有的变量名前面都没有nmt_model了。

2. 然后修改模型类里面初始化函数里面的变量名,给他们加上nmt_model
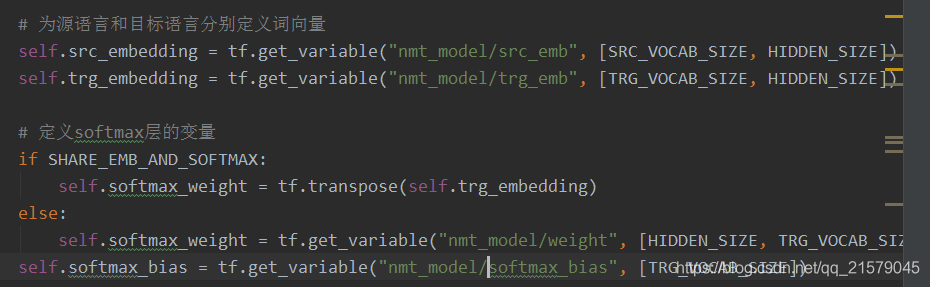
3. 这样就满足了模型中,有的变量名有nmt_model前缀,有的没有的问题了,而不是直接修改模型里面的。。。(修改模型后meta文件变得特别大,不知道为什么。总之就是绝望。。。)运行!!!
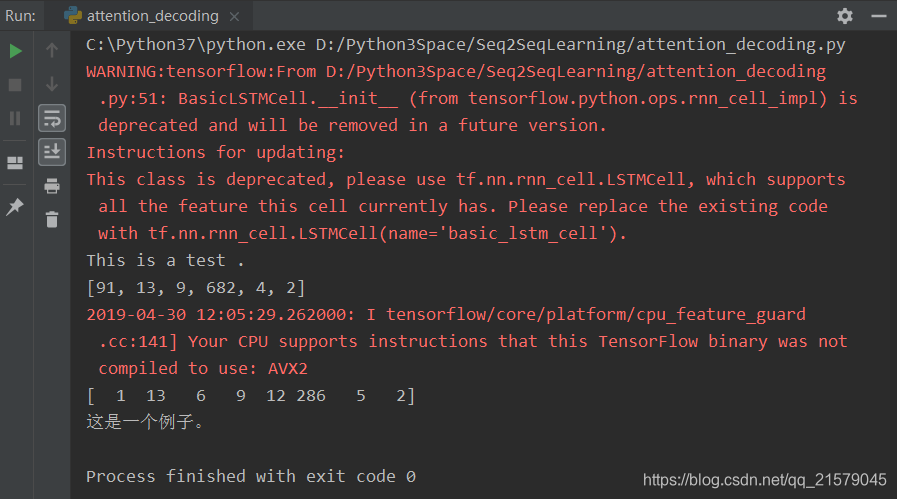
成功!欧耶!完事儿!
这次把句号翻译出来了,有进步!
6. 总结
在Attention机制这部分,原书里面就给了训练模型需要修改的部分,也并没有拿出来说明,哪里修改了,怎么修改的。最可怕的是原书中没有给出跑出模型后解码的部分,更别说学习书里面除了语言模型之外的那些模型了,我简直就是双眼一抹黑,口吐芬芳。轻叹一口气,学习果然还是得靠自己下功夫啊。十分感谢这篇文章给出的完整代码,给了我从头到尾体验Seq2Seq的机会。希望大家在学习过程中也依然保有耐心,永不言弃。
如果有读者,真的从头到尾,看完我的文章,真的是非常不容易,祝贺你,你不仅努力勤奋,还很坚强,脾气一定很好吧哈哈哈。如果有任何问题,欢迎跟我一起探讨。
最后附上整个代码的github地址,欢迎大家Watch,Star,Fork~
https://github.com/TinyHandsome/BookStudy/tree/master/book2/Seq2SeqLearning
最新文章
- 【JBOSS】数据库连接配置小结
- 开源消息队列:NetMQ
- Global.asax 文件是什么
- coursera机器学习-聚类,降维,主成分分析
- asp.net文本编辑器FCKeditor使用方法详解
- vs 引用sqlite的问题
- ThinkPHP实现联动菜单;
- [HNOI 2014]世界树
- JQuery 常用的那些东西
- 小程序webview实践
- MySQL安装-二进制软件包安装
- [daily] docker
- 安装sqlserver2008中出现的问题小结
- 在线linux 平台
- hdfs1.0和2.0复习
- WPF的DataTrigger绑定自身属性
- Vue 使用 prerender-spa-plugin 添加loading
- 如何安装Node.js环境
- jenkins持续集成python cases
- Activity相关知识点总结