《Kubernetes权威指南第2版》学习(二)一个简单的例子
1: 安装VirtualBox, 并下载CentOS-7-x86_64-DVD-1708.iso, 安装centOS7,具体过程可以百度。
2:开启centOS的SSH, 步骤如下:
(1) yum list installed | grep openssh-server查看是否已经安装了SSH,如果没有安装则输入yum install openssh-server
(2)vim /etc/ssh/sshd_config,
打开监听端口和监听地址:
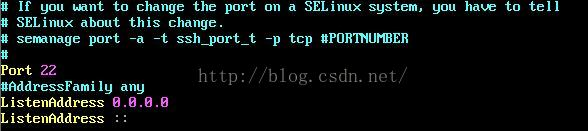
允许远程登录:

开启使用用户名密码来作为连接验证

(3)开启SSH服务:sudo service sshd start
检查 sshd 服务是否已经开启,输入ps -e | grep sshd
或者输入netstat -an | grep 22 检查 22 号端口是否开启监听
(4)ifconfig查看centOS地址,确保主机能PING通,如果不行,需要配置一下CentOS的网络类型:
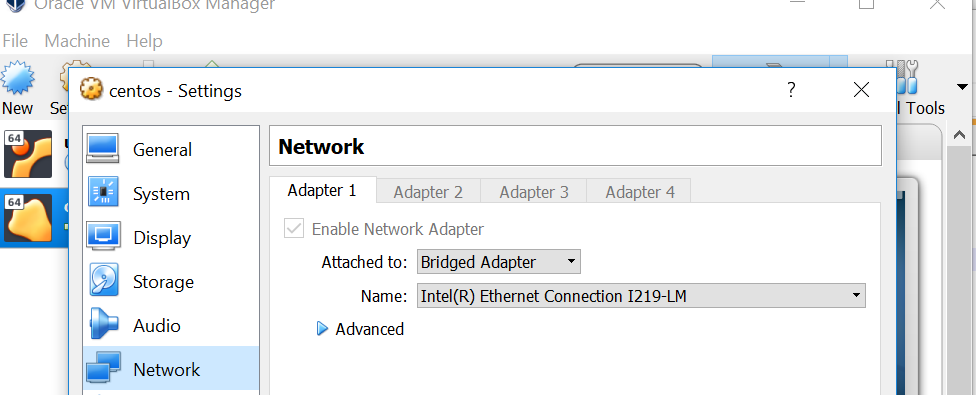
上面的配置是有线的情况下,如果是WIFI,要如下,选择无线的连接。
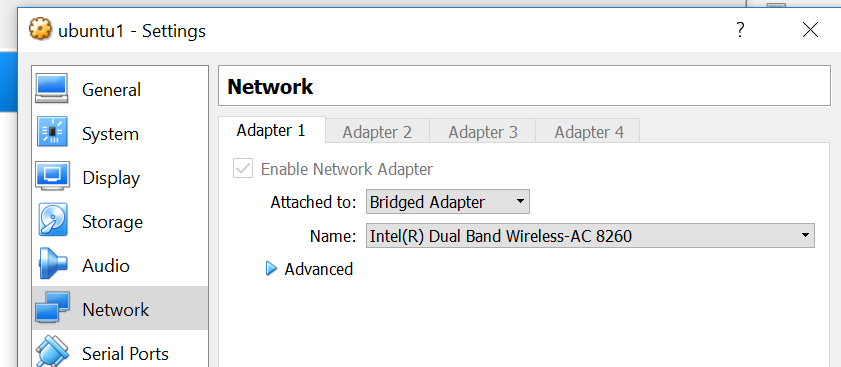
3: Kubernetes的安装和相关镜像下载
(1)关闭CentOS自带防火前服务
systemctl disable firewalld
systemtl stop firewalld
(2) 安装etcd和Kubernetes软件(会自动安装Docker软件)
yum install -y etcd kubernetes(如果yum还没安装要先安装: apt install yum-utils )
(3) 安装完后,修改两个配置文件:
Docker配置文件为 /etc/sysconfig/docker,其中options的内容设置为:
OPTIONS='--selinux-enabled=false --insecure-registry gcr.io'
Kubernetes apiserver配置文件为/etc/kubernetes/apiserver:
把--admission_control参数中的ServiceAccount删除。
(4)顺序启动所有服务:
systemctl start etcd
systemctl start docker
systemctl start kube-apiserver
systemctl start kube-controller-manager
systemctl start kube-scheduler
systemctl start kubelet
systemctl start kube-proxy
到此,一个单机版的kubernetes集群环境安装完毕。
4: 下载 web-app和mySQL的镜像:
docker pull kubeguide/tomcat-app:v2
docker pull daocloud.io/library/mysql:latest
最新文章
- C++11中自定义range
- Spring MVC重定向和转发及异常处理
- 【MongoDB】6.关于MongoDB存储文件的 命令执行+代码执行
- java中String、stringbuilder、stringbuffer区别
- 快速入门:十分钟学会Python
- 18.1---不用加号的加法(CC150)
- Unity 5.4 测试版本新特性---因吹丝停
- 【Valid Number】cpp
- TrineaAndroidCommon API Guide
- python——类
- ASP.NET MVC- 数据验证机制
- /etc/fstab一些信息
- JavaScript之面向对象的概念,对象属性和对象属性的特性简介
- java 报表到excel
- win10安装配置vs community 2015+opencv3.1.0
- Ruby 2.1: objspace.so
- Mybatis入门之动态sql
- mysql出现ERROR1698(28000):Access denied for user root@localhost错误解决方法
- netstat常见基本用法(转)
- 使用sysbench 0.5 对mysql 进行性能、压力测试