Spark Mllib里如何将数值特征字段用StandardScaler进行标准化(图文详解)
2024-08-30 07:31:54
不多说,直接上干货!
首先,要明白为什么有时候,数值特征字段需要进行标准化?
答:因为,当我们若用回归分析算法时,必须将数值特征字段进行标准化,这是因为数值特征字段单位不同,数字差异很大,所以无法彼此比较,这时,就需要使用标准化,使得数值特征字段具有共同的标准。
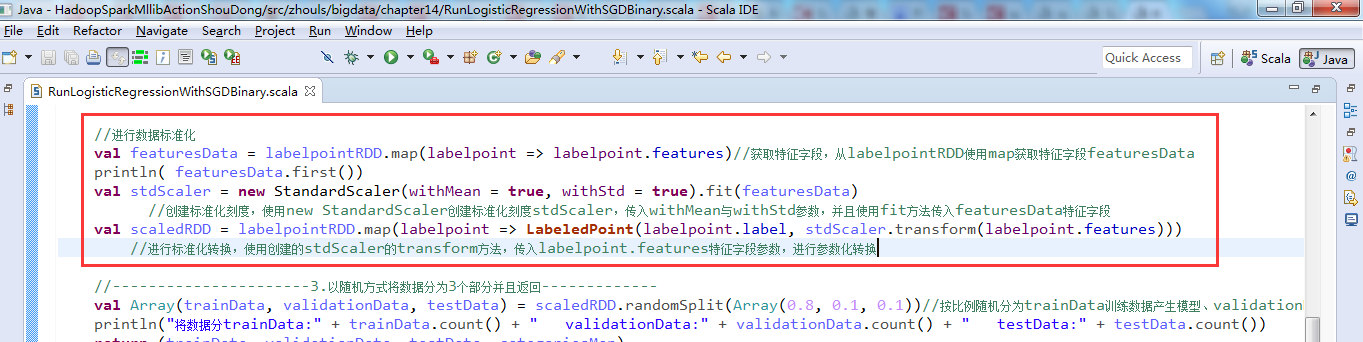
加入数据标准化 withMean = false
具体,见
Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第14章 使用逻辑回归二元分类算法来预测分类StumbleUpon数据集
最新文章
- 通过PowerShell启用AADC的密码同步功能
- Java 和C/C++的“语法”上的差异!
- javascript:算法之数组去重
- 【转】Firefox快捷键
- 【转】Java HashMap 源码解析(好文章)
- 保存form配置信息INI
- vue-resource插件使用
- linux 内核开发基础
- thinkphp5.0 生命周期
- java 读取excel
- WebGL学习(3) - 3D模型
- 用python程序来画花
- [python]标准库json格式化工具
- linux 修改history带有时间
- AIX stack_hard参数
- 关于redis实现分布式锁
- spring入门详细教程(五)
- GCD之Group
- 初识elasticsearch_2(查询和整合springboot)
- 【AtCoder】AGC020