爬虫值requests库
2024-09-20 12:51:24
requests简介
简介
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库
,使用起来比urllib简洁很多
因为是第三方库,所以使用前需要cmd安装
pip install requests
安装完成后import一下,正常则说明可以开始使用了。
基本用法:
requests.get()用于请求目标网站,类型是一个HTTPresponse类型
import requests
response = requests.get('http://www.baidu.com')
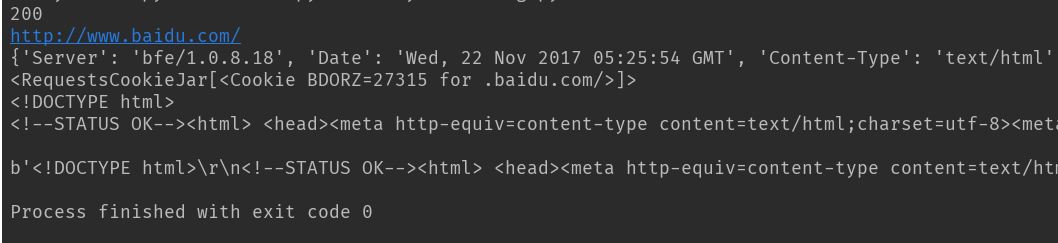
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
运行结果:
状态码:200
url:www.baidu.com
headers信息
各种请求方式:
import requests
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
基本的get请求
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
结果

带参数的GET请求:
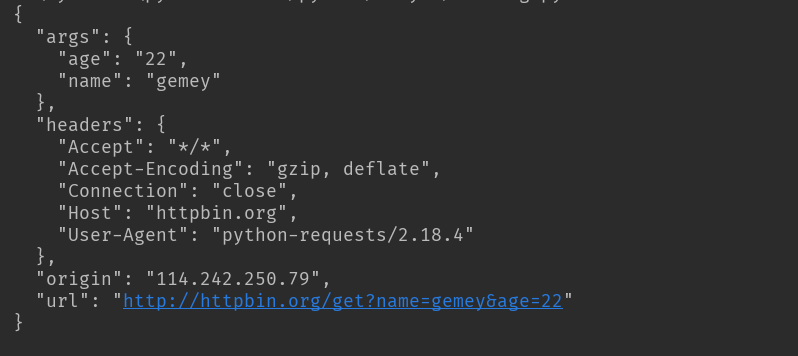
第一种直接将参数放在url内
import requests response = requests.get(http://httpbin.org/get?name=gemey&age=22)
print(response.text)
结果
另一种先将参数填写在dict中,发起请求时params参数指定为dict
import requests
data = {
'name': 'tom',
'age': 20
}
response = requests.get('http://httpbin.org/get', params=data)
print(response.text)
结果同上
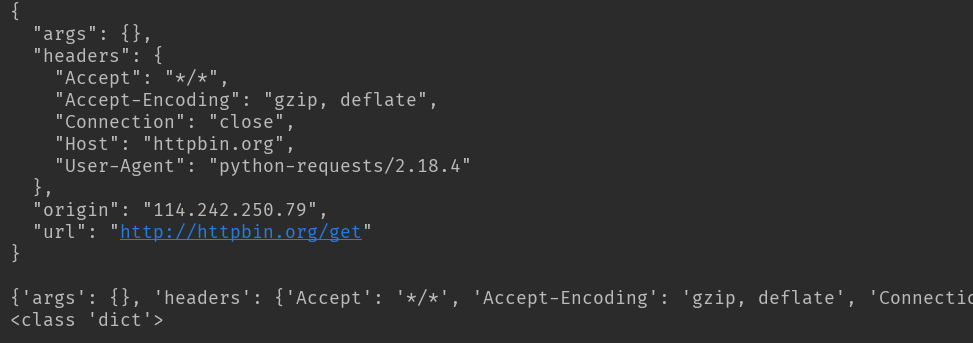
解析json
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
print(response.json()) #response.json()方法同json.loads(response.text)
print(type(response.json()))
结果
简单保存一个二进制文件
二进制内容为response.content
import requests
response = requests.get('http://img.ivsky.com/img/tupian/pre/201708/30/kekeersitao-002.jpg')
b = response.content
with open('F://fengjing.jpg','wb') as f:
f.write(b)
为请求添加头信息
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
使用代理
同添加headers方法,代理参数也要是一个dict
这里使用requests库爬取了IP代理网站的IP与端口和类型
因为是免费的,使用的代理地址很快就失效了。
import requests
import re def get_html(url):
proxy = {
'http': '120.25.253.234:812',
'https' '163.125.222.244:8123'
}
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
req = requests.get(url, headers=heads,proxies=proxy)
html = req.text
return html def get_ipport(html):
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="类型">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
for i in iplist:
for p in portlist:
for t in typelist:
pass
pass
a = t+','+i + ':' + p
sumray.append(a)
print('高匿代理')
print(sumray) if __name__ == '__main__':
url = 'http://www.kuaidaili.com/free/'
get_ipport(get_html(url))
结果:

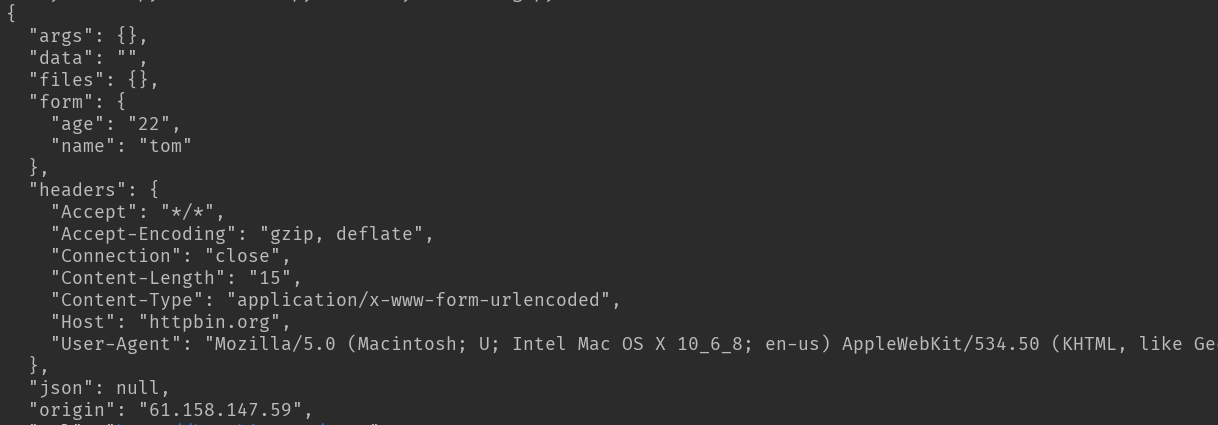
基本POST请求:
import requests
data = {'name':'tom','age':''}
response = requests.post('http://httpbin.org/post', data=data)
获取cookie
#获取cookie
import requests response = requests.get('http://www.baidu.com')
print(response.cookies)
print(type(response.cookies))
for k,v in response.cookies.items():
print(k+':'+v)
结果:

会话维持
import requests session = requests.Session()
session.get('http://httpbin.org/cookies/set/number/12345')
response = session.get('http://httpbin.org/cookies')
print(response.text)
结果:

证书验证设置
import requests
from requests.packages import urllib3 urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code) 打印结果:200
超时异常捕获
import requests
from requests.exceptions import ReadTimeout try:
res = requests.get('http://httpbin.org', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print(timeout)
异常处理
在你不确定会发生什么错误时,尽量使用try...except来捕获异常
所有的requests exception:
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
最新文章
- 利用Eclipse使用Java OpenCV(Using OpenCV Java with Eclipse)
- Tomcat常见问题汇总
- Dwz下拉菜单的二级联动
- python学习之for语句
- Android--Fragment的懒加载
- C# ASP .NET WEB方向和WPF方向,我该如何去选择
- mac 下 sphinx + mysql + php 实现全文搜索(xampp)(1)
- java eclipse 连接数据库全过程
- [Mugeda HTML5技术教程之14]案例分析:制作网页游戏
- [cocos2d-x]针对不同的设备,选取不同的自适应图片
- Android布局及属性归总(查询用)
- Python文件读写 - 文件r+ a+ open读写实际表现[示例]
- Java数据持久层框架 MyBatis之API学习七(动态 SQL详解)
- js实现二叉树
- js常见的面试题
- Jmeter性能测试之关联(三)
- 理解ThreadPoolExecutor线程池的corePoolSize、maximumPoolSize和poolSize
- WebStrom直接启动VUE项目
- ES6的export和import
- (原创)composite模式和bridge模式是天生的好朋友