linux运维、架构之路-正则表达式
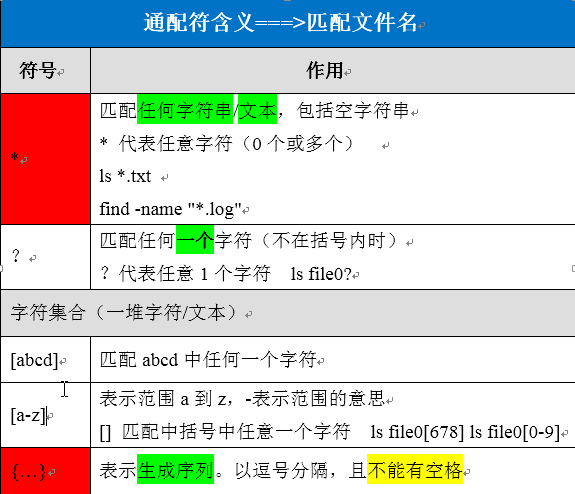
一、通配符的含义
|
符号 |
参数说明 |
其他说明 |
|
| |
管道 |
把前一个命令结果通过管道传递给后面一个命令 |
|
; |
命令的分隔符 |
ll /oldboy/;cat oldboy.tx |
|
. |
表示当前目录 |
|
|
* |
匹配文本或字符串 |
ls *.txt,ls *.log |
|
/ |
根或路径的分隔符 |
|
|
&& |
命令分隔 |
表示并且,前一个执行成功才会执行后面的 |
|
$ |
取变量的值 |
echo $PATH |
|
{} |
配合echo打印序列 |
echo {1..6} |
通配符中以*和{}最为常用
1、举例说明
①查找/oldboy下所有.txt文件
[root@oldboyedu37 oldboy]# find /oldboy -type f -name "*.txt"
/oldboy/abc.txt
/oldboy/oldboy.txt
/oldboy/a.txt
②在/oldboy目录下批量创建10个以文件,例如:oldboy1-oldboy10.txt
[root@oldboyedu37 oldboy]# touch oldboy{..}.txt
[root@oldboyedu37 oldboy]# ls -lrt
-rw-r--r-- root root Jun : oldboy9.txt
-rw-r--r-- root root Jun : oldboy8.txt
-rw-r--r-- root root Jun : oldboy7.txt
-rw-r--r-- root root Jun : oldboy6.txt
-rw-r--r-- root root Jun : oldboy5.txt
-rw-r--r-- root root Jun : oldboy4.txt
-rw-r--r-- root root Jun : oldboy3.txt
-rw-r--r-- root root Jun : oldboy2.txt
-rw-r--r-- root root Jun : oldboy1.txt
-rw-r--r-- root root Jun : oldboy10.txt
③{}备份文件作用
[root@oldboyedu37 oldboy]# cp oldboy.txt{,.bak}
-rw-r--r-- root root Jun : oldboy.txt.bak
二、正则表达式
1、基本正则表达式(BRE,basic)
|
符号 |
参数说明 |
其他说明 |
|
^ |
以……开始 |
^word表示以word开始的行或字符串 |
|
[^] |
在[]里面^表示非 |
[^word]不包含word的行或字符串 |
|
$ |
以……结尾 |
word$表示以word结尾的行或字符串 |
|
. |
代表任意一个字符 |
|
|
* |
匹配前一个字符0次或多次 |
|
|
.* |
匹配所有 |
|
|
+ |
匹配前一个字符1次或多次 |
|
|
^$ |
表示空行 |
可以理解为以结尾开始,或以开始结尾 |
|
{n,m} |
匹配前一个字符n到m次 |
|
|
\ |
转译符号 |
让一个特殊的字符还原它本来的意义 |
2、扩展正则表达式(ERE)
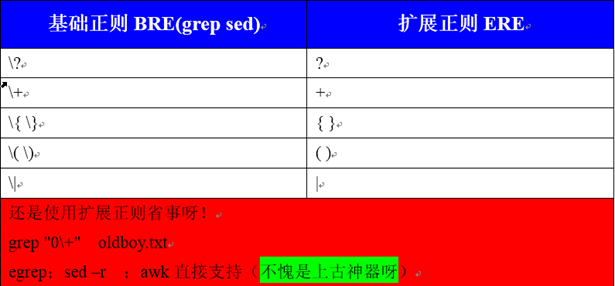
3、正则表达式应用——别名环境变更配置vi/etc/profile

主要是给grep和egrep加—color过滤出的内容显示颜色
4、正则表达式使用案例
①模拟环境
[root@oldboyedu37 tmp]# cat oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is .
not .
my god ,i am not oldbey,but OLDBOY!
②过滤出oldboy.txt以my开头的行
[root@oldboyedu37 tmp]# grep "^my" oldboy.txt
my blog is http://oldboy.blog.51cto.com
my qq num is .
my god ,i am not oldbey,but OLDBOY!
③过滤出oldboy.txt以m结尾的行
[root@oldboyedu37 tmp]# grep "m$" oldboy.txt
my blog is http://oldboy.blog.51cto.com
④^$、过滤出oldboy.txt文件的空行
[root@oldboyedu37 tmp]# grep -n "^$" oldboy.txt
:
:
⑤\. 过滤出oldboy.txt以.结尾的行 .在与三剑客配置中有特殊意义,所以使用撬棍\转译
[root@oldboyedu37 tmp]# grep "\.$" oldboy.txt
I teach linux.
my qq num is .
not .
⑥.*匹配所有内容 grep ".*" oldboy.txt
[root@oldboyedu37 tmp]# grep ".*" oldboy.txt
I am oldboy teacher!
I teach linux. I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is . not .
my god ,i am not oldbey,but OLDBOY!
⑦[ABC]过滤出oldboy.txt文件中以m或n或o开头的行,并且以m或g结尾的行
法一:[root@oldboyedu37 tmp]# grep "^[mon]" oldboy.txt|grep "[mg]$"
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
法二:[root@oldboyedu37 tmp]# grep "^[mon].*[mg]$" oldboy.txt
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
⑧[^ABC] 排除oldboy.txt文件中以m或n的行
[root@oldboyedu37 tmp]# grep "^[^mn]" oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
our site is http://www.etiantian.org
5、扩展正则表达式(ERE)egrep
①+匹配前一个字符连续出现1次或多次
[root@oldboyedu37 tmp]# egrep "0+" oldboy.txt
my qq num is .
not .
②|配合egrep同时可以过滤多个字符串
[root@oldboyedu37 tmp]# egrep "3306|1521" /etc/services
mysql /tcp # MySQL
mysql /udp # MySQL
ncube-lm /tcp # nCube License Manager
ncube-lm /udp # nCube License Manager
③{n,m} 重复前面的字符n到m次
[root@oldboyedu37 tmp]# egrep "0{1,5}" oldboy.txt
my qq num is .
not .
6、小试牛刀
①利用sed取ip地址
方法一:
定位到ip地址所在的行
[root@oldboyedu37 tmp]# ifconfig eth0|sed -n '2p'
inet addr:10.0.0.8 Bcast:10.0.0.255 Mask:255.255.255.0
匹配掐头去尾取想要的内容
[root@oldboyedu37 tmp]# ifconfig eth0|sed -n '2p'|sed 's#^.*ddr:##g'|sed 's# Bc.*$##g'
10.0.0.8 方法二:[root@oldboyedu37 tmp]# ifconfig eth0|sed -n '2p'|sed -r 's#^.*ddr:|Bc.*$##g'
10.0.0.8 方法三:利用sed的后向引用
[root@oldboyedu37 tmp]# ifconfig eth0|sed -n '2p'|sed -r 's#^.*ddr:(.*)Bc.*$#\1#g'
10.0.0.8 方法四:sed直接定位所取的行并匹配替换
[root@oldboyedu37 tmp]# ifconfig eth0|sed -nr '2s#^.*ddr:(.*)Bc.*$#\1#gp'
10.0.0.8
②取/etc/hosts文件属性权限
方法一:[root@oldboyedu37 tmp]# stat /etc/hosts|sed -nr '4s#^.*\(0(.*)/-.*$#\1#gp'
方法二:[root@oldboyedu37 tmp]# stat /etc/hosts|sed -n '4p'|sed 's#^.*(0##g'|sed 's#/-.*$##g'
方法三:利用stat命令带的参数直接取出
[root@oldboyedu37 tmp]# stat -c %a /etc/hosts
7、date显示时间
①工作中常配合tar命令打包使用
[root@oldboyedu37 /]# tar zcvf oldboy_$(date +%F).tar.gz oldboy/
oldboy/
oldboy/netstat.log
oldboy/web_url.log
oldboy/oldboy.txt
oldboy/t1.awk
oldboy/access-test.log
oldboy/.bak
oldboy/oldboy.log
②简写几天前、几天后
date -d '+3day' #——>显示3天后的日期时间
date -d '-3day' #——>显示3天前的日期时间
date -d '-3hour' #——>显示3小时前的日期时间
[root@oldboyedu37 /]# date +%F -d '-1day'——工作中常用方法打包,打包一天前
三、AWK格式及使用正则
1、通过awk取出passwd的第5行内容
[root@nfs-server oldboy]# awk 'NR==5' passwd
lp:x:::lp:/var/spool/lpd:/sbin/nologin
2、显示passwd第五行的最后一列
[root@nfs-server oldboy]# awk -F ":" 'NR==5{print $NF}' passwd
/sbin/nologin
3、找出passwd中以root开头的行
[root@nfs-server oldboy]# awk '/^root/' passwd
root:x:::root:/root:/bin/bash
4、找出passwd第六列中包含home的行
[root@nfs-server oldboy]# awk -F ":" '$6~/home/' /etc/passwd
salt:x::::/home/salt:/bin/bash
小题:
已知[root@nfs-server files]# cat reg.txt
Zhang Dandan :::
Zhang Xiaoyu :::
Meng Feixue :::
Wu Waiwai :::
Liu Bingbing :::
Wang Xiaoai :::
Zi Gege :::
Li Youjiu :::
Lao Nanhai :::
说明:
###第一列是姓氏
###第二列是名字
###第一第二列合起来就是姓名
###第三列是对应的ID号码
###最后三列是三次捐款数量
①姓氏是Zhang的人,显示他的第二次捐款金额及她的名字
[root@nfs-server files]# awk -F "[ :]+" '/^Zhang/{print $1,$2,$5}' reg.txt
Zhang Dandan
Zhang Xiaoyu
②显示Xiaoyu的姓氏和ID号码
[root@nfs-server files]# awk '$2~/Xiaoyu/{print $1,$3}' reg.txt
Zhang
③显示所有以41开头的ID号码的人的全名和ID号码
[root@nfs-server files]# awk '$3~/^41/{print $1,$2,$3}' reg.txt
Zhang Dandan
Liu Bingbing
④显示所有以一个D或X开头的人名全名
[root@nfs-server files]# awk '$2~/^[DX]/{print $1,$2}' reg.txt
Zhang Dandan
Zhang Xiaoyu
Wang Xiaoai
⑤显示所有ID号码最后一位数字是1或5的人的全名
[root@nfs-server files]# awk '$3~/[15]$/{print $1,$2}' reg.txt
Zhang Xiaoyu
Wu Waiwai
Wang Xiaoai
Li Youjiu
Lao Nanhai
⑥显示Xiaoyu的捐款.每个值时都有以$开头.如$520$200$135
方法一:[root@nfs-server files]# awk '/Xiaoyu/{print $4}' reg.txt|tr ":" "$"
$$$
方法二:
[root@nfs-server files]# awk '/Xiaoyu/{gsub(/:/,"$",$NF);print $NF}' reg.txt
$$$
方法三:
[root@nfs-server files]# awk '/Xiaoyu/{print $4}' reg.txt|sed 's#:#$#g'
$$$
⑦显示所有人的全名,以姓,名的格式显示,如Meng,Feixue
[root@nfs-server files]# awk '{print $1","$2}' reg.txt
Zhang,Dandan
Zhang,Xiaoyu
Meng,Feixue
Wu,Waiwai
Liu,Bingbing
Wang,Xiaoai
Zi,Gege
Li,Youjiu
Lao,Nanhai
四、 AWK数组计算
1、计算/etc/services 文件有多少个空行 awk
[root@nfs-server files]# awk '/^$/{i=i+1}END{print i}' /etc/services
2、已知:cat url.txt,计算出域名出现的次数
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
方法一:[root@nfs-server files]# awk -F "[/.]+" '{print $2}' url.txt|sort|uniq -c
mp3
post
www
方法二:数组方法:[root@nfs-server files]# awk -F "[/.]+" '{hotel[$2]++}END{for(pol in hotel)print pol,hotel[pol]}' url.txt
www
mp3
post
3、使用awk计算1加到100
方法一:[root@nfs-server files]# awk 'BEGIN{ for(i=1;i<=100;i++) sum=sum+i;print sum}'
方法二:
[root@nfs-server files]# seq |awk '{hotel=hotel+$1}END{print hotel}'
4、假如现在有个文本,格式如下:
a 1
b 3
c 2
d 7
b 5
a 3
g 2
f 6
d 9
即左边是随机字母,右边是随机数字,要求写个脚本使其输出格式为:
a 4
b 8
c 2
d 16
f 6
g 2
解答:
[root@nfs-server files]# awk '{hotel[$1]=hotel[$1]+$2}END{for(pol in hotel)print pol,hotel[pol]}' a.txt
a
b
c
d
f
g
最新文章
- python 安装easy_install和pip
- (旧)子数涵数·PS——文字人物
- BZOJ2191Splite
- C# 6 与 .NET Core 1.0 高级编程 - 41 ASP.NET MVC(中)
- 爬虫协议robots
- Pycharm快捷键的使用
- Java课程设计 - 学生基本信息管理
- 基于springboot的freemarker创建指定格式的word文档
- 新概念英语(1-101)A Card From Jimmy
- scala求交集、并集、差集命令
- Java网络爬虫Hello world实现——Httpclient爬取百度首页
- 窗体焦点监听事件WindowFocusListener
- windows 邮槽mailslot 在服务程序内建立后客户端无权限访问(GetLastError() == 5)的问题
- 6月17 ThinkPHP连接数据库------数据的修改及删除
- canvas文字自动换行、圆角矩形画法、生成图片手机长按保存、方形图片变圆形
- 816B. Karen and Coffee 前缀和思维 或 线段树
- uiautomatorviewer定位App元素
- MSSQL Export Excel
- 3年工作经验的Java程序员面试经
- rem布局原理