python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧。至少证明着我是有些许进步的,愿你也是一样!
下面是它的姊妹篇,介绍使用requests和bs4(BeautifulSoup)库来爬取静态网页中的信息。
爬虫从黑盒的角度来看,就是给出网页的链接,输出你想要的信息的一段程序。大概会涉及这几个步骤:

1. 使用requests+re正则
单纯使用requests库来做,需要会写正则表达式,这里借助之前的那篇 爬取猫眼Top100榜单 来讲。
第一步——获取HTML代码
一般使用requests库get()方法,这里封装成为一个函数
def get_one_page(url):
try:
headers = {
'user-agent':'Mozilla/5.0'
}
# use headers to avoid 403 Forbidden Error(reject spider)
response = requests.get(url, headers=headers)
if response.status_code == 200 :
return response.text
return None
except RequestException:
return None
第二部——分析页面HTML代码,写正则表达式,提取信息
先来看页面
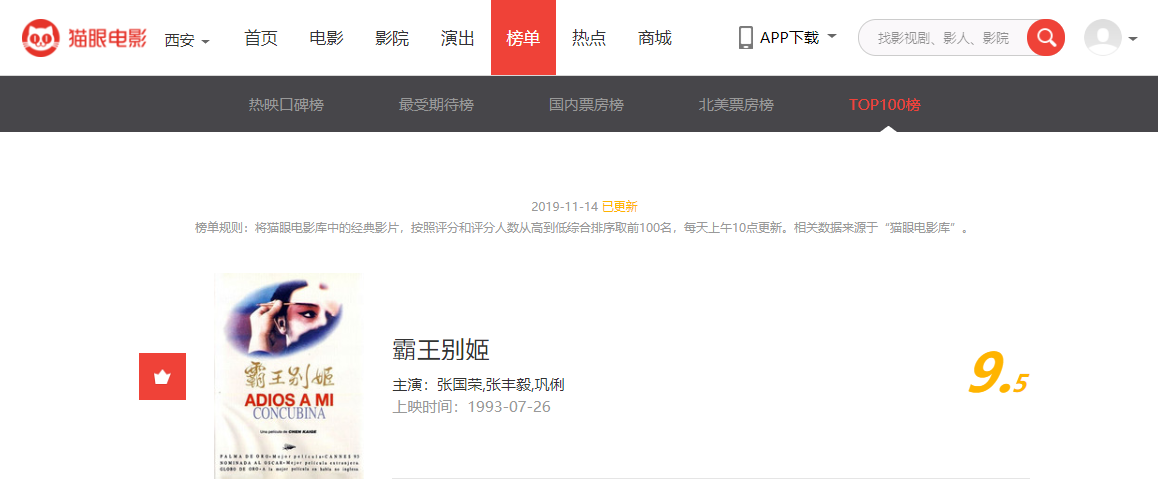
分析它的HTML,我目前需要排名、片名、主演、上映时间和评分信息。
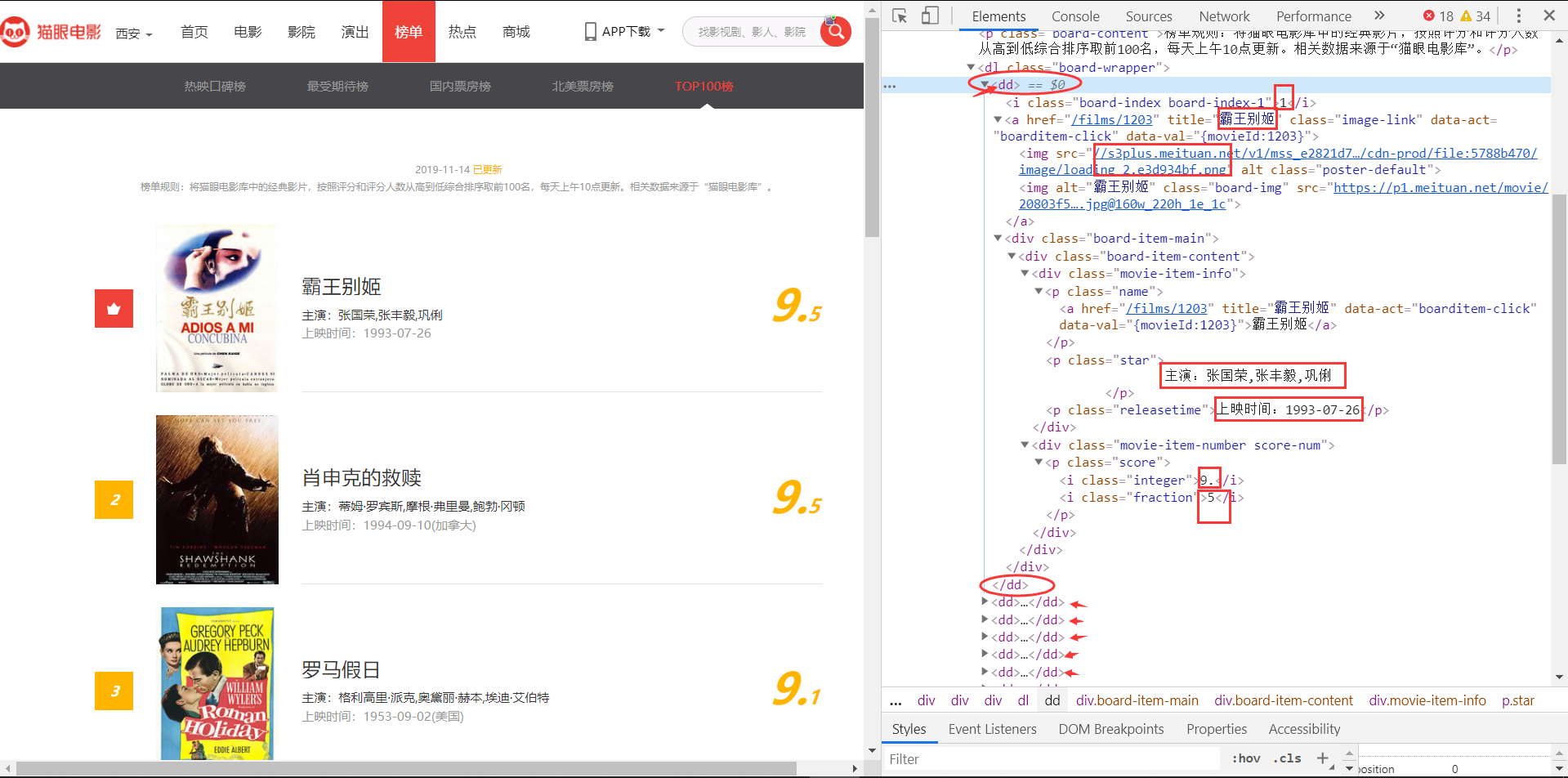
可以看到,榜单中每一个电影条目都在一组<dd></dd>标签中,而且所需的信息也很明确,我们来写正则,正则的关键在于找好独一无二的参照(已在途中方格标出)
re_text =
'<dd>.*?board-index.*?>(\d+)<.*?<a.*?title="(.*?)"'
+'.*?data-src="(.*?)".*?</a>.*?star">[\\s]*(.*?)[\\n][\\s]*</p>.*?'
+'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?'
+'fraction">(.*?)</i>.*?</dd>'
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)<.*?<a.*?title="(.*?)"'
+'.*?data-src="(.*?)".*?</a>.*?star">[\\s]*(.*?)[\\n][\\s]*</p>.*?'
+'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?'
+'fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
return items
先编译正则表达式成为pattern,然后在页面中findall符合条件的信息。这样就会将正则表达式匹配到的所有信息,以一个列表的形式返回。
第三部——持久化存储数据
我所做的实践由于数据量较小,目前都是采用excel(*.xlsx)来存储。需要用到一个openpyxl库,自行安装即可,它的使用教程有很多,不是我所述的主要内容,烦请自行学习。
已经爬到的数据
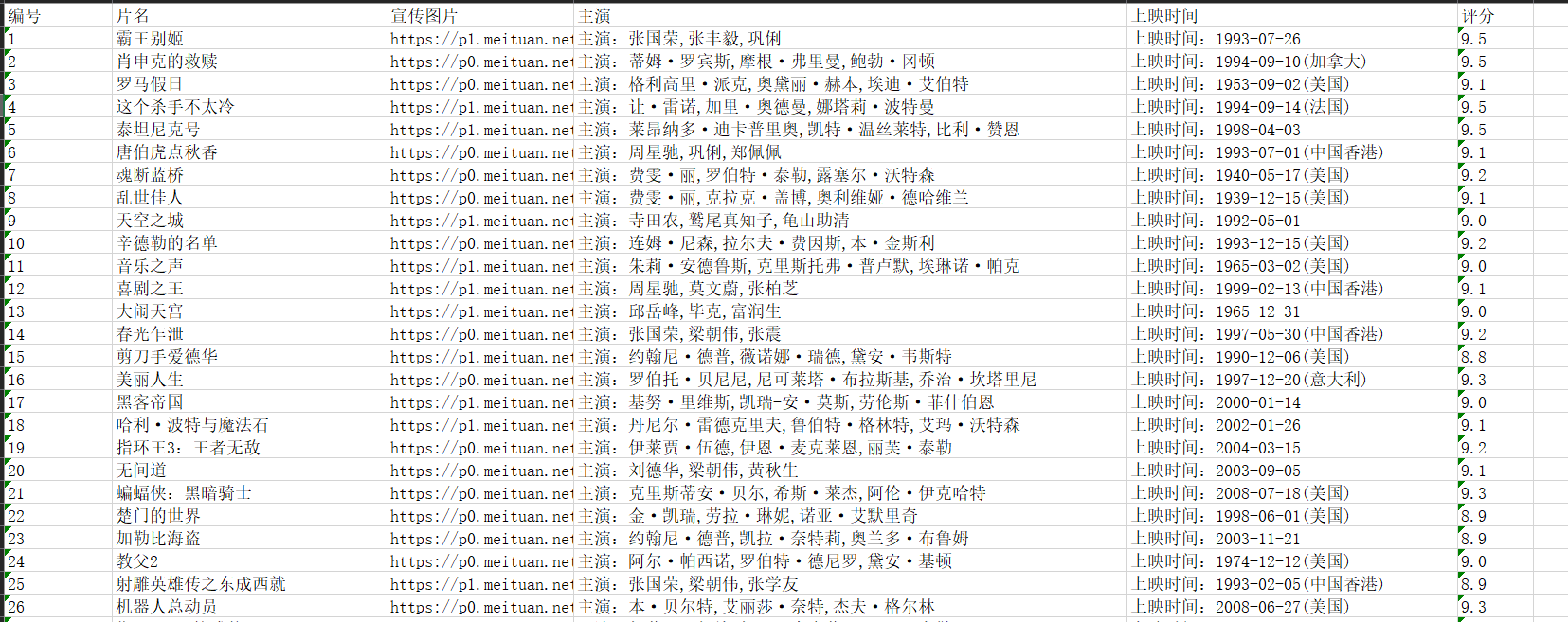
注意:上面所讲的是获取一个页面(含20条信息,该榜单有100条,势必会有分页),所以URL肯定需要替换,但是肯定是有规律的(具体的看这篇博客吧 猫眼top100 )
2. 使用bs4(BeautifulSoup)筛选器
使用bs4库,需要先自己安装一下。
所谓筛选器,即相当于我们上面正则表达式中的“参考”,即:锚点。通过筛选器,可以非常方便的获取页面当中的信息。下面讲一个例子,就明白了。
栗子:
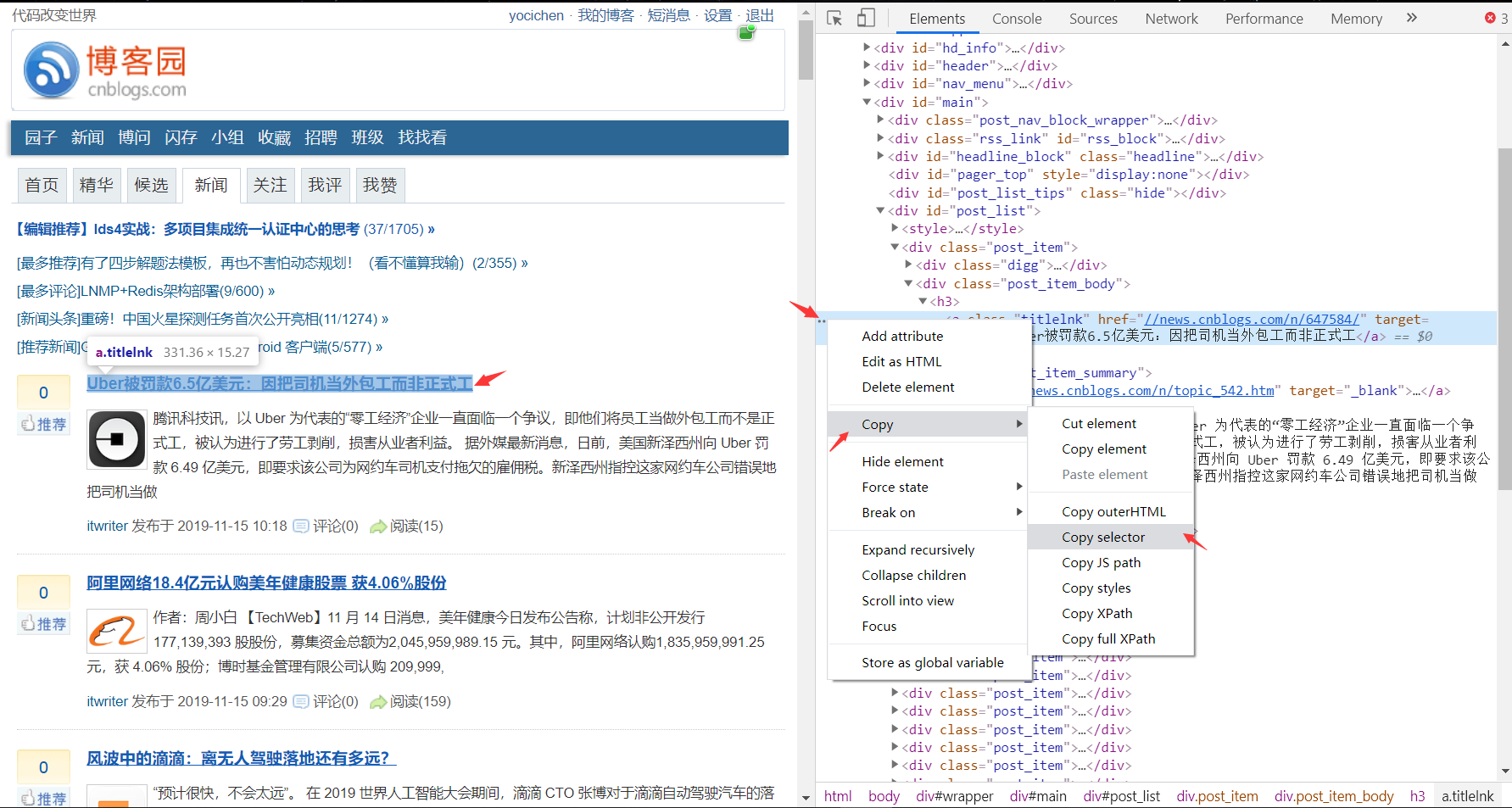
获取博客园新闻板块第一条的新闻title,先来瞧瞧HTML和selector。
代码:
# -*- coding: utf-8 -*-
# @Author : yocichen
# @Email : yocichen@126.com
# @File : test_bs4.py
# @Software: PyCharm
# @Time : 2019/11/15 10:23 import requests
from bs4 import BeautifulSoup
import lxml url = 'https://www.cnblogs.com/news/'
headers = {
'user-agent':'Mozilla/5.0'
}
# 获取HTML
html = requests.get(url, headers=headers)
# 解析HTML
soup = BeautifulSoup(html.text, 'lxml')
# 筛选器筛选信息
selector = '#post_list > div:nth-child(2) > div.post_item_body > h3 > a'
res = soup.select(selector)
print('博客园新闻板块第一条title\n', res[0].string)
结果:

可以看到,获取selector十分简单,chrome浏览器或者其他浏览器也有支持,这样一来就避免了去写繁杂的正则表达还写不出来的窘境。
最终的持久化存储过程,同上,不再赘述。
后记
python爬虫入门篇就此结束了,爬虫深入的话还涉及到防止反爬,以及爬取动态页面等问题,有机会的话会再学习再写一篇。
以上内容其实是对我最近所学所做的总结,如果你从中也有些许收获,不妨点个“推荐”吧!
最新文章
- mysql awr 1.0.5 GA正式版发布
- yii的验证码
- JVM生产环境参数实例及分析[转]
- 解决 No resource found that matches the given name (at 'icon' with value '@drawable/icon') 问题
- Windows KB2984972安装后堵住了一个windows 7 桌面可以多个用户远程访问桌面的漏洞。
- 关于action script与js相互调用的Security Error问题
- How To Create a New User and Grant Permissions in MySQL
- JAVA首选五款开源Web开发框架
- hpu第五届acm比赛
- 运动检测(前景检测)之(一)ViBe
- 获取时间SQL函数语句
- Entity Framework 学习中级篇1—EF支持复杂类型的实现
- GridView的RowCreated与RowDataBound事件区别
- Win10 部署 依赖 NET3.5 项目,报错 无法安装 NET3.5 ,该如何解决?
- 我的第一个chrome浏览器扩展 5分钟学习搞定
- framework7 入门(数据获取和传递)
- #Java学习之路——基础阶段(第三篇)
- springIOplatform
- leetcode — count-and-say
- java泛型-自定义泛型方法与类型推断总结