lua的性能优化
2024-08-25 19:17:08
Roberto Ierusalimschy写过经典的Lua 性能提示的文章,链接地址>>
我通过实际的代码来验证,发现一个问题。当我使用 LuaStudio 运行时,发现结果反而与提示相反,甚是奇怪,而使用luac进行运行,与作者给予的提示相符,在某些地方性能可能有优化,比如读取35kb的文件时,时间还是比较快的(可能5.1版本做过优化了)。
日常的Lua编码中,需要注意以下几点:
1)多使用local
print(_VERSION) local startTime, endTime startTime = os.clock() for i = 1, 100 * 10000 do
local x = math.sin(i)
end endTime = os.clock() print("[local] used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock() local sin = math.sin
for i = 1, 100 * 10000 do
local x = sin(i)
end endTime = os.clock() print("[local] used time " .. (endTime - startTime) * 1000 .. " ms")

上面二段代码,唯一的区别就是使用 local sin 将 math.sin缓存起来。性能提升约 (107 - 74) / 107 ~= 30.8%,基本符合作者所说的30%的效率提升。
startTime = os.clock()
function foo(x)
for i = 1, 100 * 10000 do
x = x + math.sin(i)
end
return x
end foo(10) endTime = os.clock() print("[foo] used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
function foo2(x)
local sin = math.sin
for i = 1, 100 * 10000 do
x = x + sin(i)
end
return x
end foo2(10) endTime = os.clock() print("[foo2] used time " .. (endTime - startTime) * 1000 .. " ms")
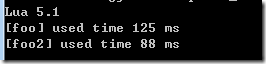
提升的时间是 (125 – 88) /125 = 29.6%,也约为30%(需要多次测试取平均值)
使用闭包,避免动态编译。
startTime = os.clock()
local lim = 10 * 10000
local a = {}
for i = 1, lim do
a[i] = loadstring(string.format("return %d", i))
end print(a[10]()) endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
function fk(k)
return function() return k end
end local lim = 10 * 10000
local a = {}
for i = 1, lim do
a[i] = fk(i)
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms")
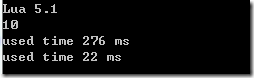
节省了约92%的时间,差异距大。
2) 字符串拼接,尽可能使用 table 替代
startTime = os.clock() local buff = ""
for line in io.lines("C:/Users/zhangyi/Desktop/xxx.txt") do
buff = buff .. line .. "\n"
end endTime = os.clock() print(collectgarbage("count") * 1024) print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock() local buff = ""
local tbl = {}
for line in io.lines("C:/Users/zhangyi/Desktop/xxx.txt") do
table.insert(tbl, line)
end buff = table.concat(table, "\n") endTime = os.clock() print(collectgarbage("count") * 1024) print("used time " .. (endTime - startTime) * 1000 .. " ms")
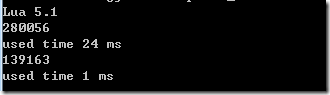
差异非常大,无论是内存还是时间,主要原因是:Lua中字符串的拼接都是新创建一个新的字符串,有一个新创建一块内存、copy字符串的动作,时间、空间上消耗都比较大。
3) table使用的优化
startTime = os.clock()
for i = 1, 100 * 10000 do
local a = {}
a[1] = 1
a[2] = 2
a[3] = 3
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
for i = 1, 100 * 10000 do
local a = {true, true, true}
a[1] = 1
a[2] = 2
a[3] = 3
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms")
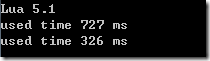
时间相差一倍,也就是说如果不给{}给定初时化大小,当赋值的时候,它会申请空间来存放相应的值。
local polyline= {}
for i = 0, 100 * 10000 do
table.insert(polyline, {x = i, y = 1})
end
print(collectgarbage("count") / 1024)
107.57151889801MB
local polyline= {}
for i = 0, 100 * 10000 do
table.insert(polyline, {i, 1})
end
print(collectgarbage("count") / 1024)
77.053853034973MB
local polyline= {
x = {},
y = {}
}
for i = 0, 100 * 10000 do
table.insert(polyline.x, i)
table.insert(polyline.y, i)
end
print(collectgarbage("count") / 1024)
32.019150733948MB
空间占用差距也非常大,从上面似乎可以得到这样的结论:尽可能减少table的长度,尽可能使用array 而不是 hash。
综上所述,尽可能多使用local,减少查询的性能损耗。json数据表如果需要转化为table时,改变数据的存储结构可能减少很大的内存使用。
最新文章
- x01.MagicCube: 简单操作
- C# 6.0 Feature list
- 9.3 js基础总结3
- Nginx + spawn-fcgi- Ubuntu中文
- python项目在windows下运行出现编码错误的解法
- SQL 变量
- java学习___File类的查看和删除
- java中读取文件以及向文件中追加数据的总结
- 个人软件过程(psp)需求文档
- 通过网络方式安装linux的五种方法
- Winform Krypton控件使用(一)
- the third assignment of software testing
- TREEVIEW拖拽对应修改目录
- 网络资源(1) - Hadoop视频
- 用GDB调试程序的设置 Segmentation fault(Core Dump)调试
- Swift:Foundation框架中的NS前缀的由来
- 为什么从前那些.NET开发者都不写单元测试呢?
- python3操作MySQL数据库,一次插入多条记录的方法
- 我的第一个python web开发框架(34)——后台管理系统权限设计
- Python turtle安装和使用教程