[DB] Spark Streaming
2024-09-04 09:00:24
概述
- 流式计算框架,类似Storm
- 严格来说不是真正的流式计算(实时计算),而是把连续的数据当做不连续的RDD处理,本质是离散计算
- Flink:和 Spark Streaming 相反,把离散数据当成流式数据处理
基础
- 易用,已经集成在Spark中
- 容错性,底层也是RDD
- 支持Java、Scala、Python

WordCount
- nc -l -p 1234
- bin/run-example streaming.NetworkWordCount localhost 1234
- cpu核心数必须>1,不记录之前的状态


1 import org.apache.spark.SparkConf
2 import org.apache.spark.storage.StorageLevel
3 import org.apache.spark.streaming.{Seconds, StreamingContext}
4
5 // 创建一个StreamingContext,创建一个DSteam(离散流)
6 // DStream表现形式:RDD
7 // 使用DStream把连续的数据流变成不连续的RDD
8 object MyNetworkWordCount {
9 def main(args: Array[String]): Unit = {
10 // 创建一个StreamingContext对象,以local模式为例
11 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
12 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
13
14 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
15 val ssc = new StreamingContext(conf,Seconds(3))
16
17 // 创建DStream,从netcat服务器接收数据
18 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
19
20 // 进行单词计数
21 val words = lines.flatMap(_.split(" "))
22
23 // 计数
24 val wordCount = words.map((_,1)).reduceByKey(_+_)
25
26 // 打印结果
27 wordCount.print()
28
29 // 启动StreamingContext,进行计算
30 ssc.start()
31
32 // 等待任务结束
33 ssc.awaitTermination()
34 }
35 }

高级特性
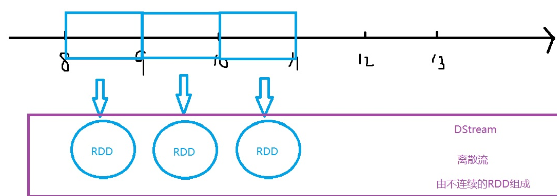
- 什么是DStream:离散流,把连续的数据流变成不连续的RDD
- transform
- updateStateByKey(func):累加之前的结果,设置检查点,把之前的结果保存到检查点目录下
- hdfs dfs -mkdir -p /day0614/ckpt
- hdfs dfs -ls /day0614/ckpt
1 import org.apache.spark.SparkConf
2 import org.apache.spark.storage.StorageLevel
3 import org.apache.spark.streaming.{Seconds, StreamingContext}
4
5 // 创建一个StreamingContext,创建一个DSteam(离散流)
6 // DStream表现形式:RDD
7 // 使用DStream把连续的数据流变成不连续的RDD
8 object MyTotalNetworkWordCount {
9 def main(args: Array[String]): Unit = {
10 // 创建一个StreamingContext对象,以local模式为例
11 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
12 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
13
14 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
15 val ssc = new StreamingContext(conf,Seconds(3))
16
17 // 设置检查点目录,保存之前状态
18 ssc.checkpoint("hdfs://192.168.174.111:9000/day0614/ckpt")
19
20 // 创建DStream,从netcat服务器接收数据
21 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
22
23 // 进行单词计数
24 val words = lines.flatMap(_.split(" "))
25
26 // 计数
27 val wordPair = words.map(w => (w,1))
28
29 // 定义值函数
30 // 两个参数:1.当前的值 2.之前的结果
31 val addFunc = (curreValues:Seq[Int],previousValues:Option[Int])=>{
32 // 把当前序列进行累加
33 val currentTotal = curreValues.sum
34
35 // 在之前的值上再累加
36 // 如果之前没有值,返回0
37 Some(currentTotal + previousValues.getOrElse(0))
38 }
39
40 // 累加计算
41 val total = wordPair.updateStateByKey(addFunc)
42
43 total.print()
44
45 ssc.start()
46
47 ssc.awaitTermination()
48
49 }
50 }

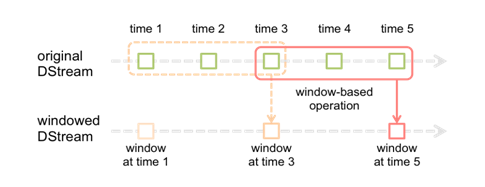
- 窗口操作
- 只统计在窗口中的数据
- Exception in thread "main" java.lang.Exception: The slide duration of windowed DStream (10000 ms) must be a multiple of the slide duration of parent DStream (3000 ms)
- 滑动距离必须是采样频率的整数倍
1 package day0614
2
3 import org.apache.log4j.{Level, Logger}
4 import org.apache.spark.SparkConf
5 import org.apache.spark.storage.StorageLevel
6 import org.apache.spark.streaming.{Seconds, StreamingContext}
7
8
9 object MyNetworkWordCountByWindow {
10 def main(args: Array[String]): Unit = {
11 // 不打印日志
12 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
13 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
14 // 创建一个StreamingContext对象,以local模式为例
15 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
16 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
17
18 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
19 val ssc = new StreamingContext(conf,Seconds(3))
20
21 // 创建DStream,从netcat服务器接收数据
22 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
23
24 // 进行单词计数
25 val words = lines.flatMap(_.split(" ")).map((_,1))
26
27 // 每9s,把过去30s的数据进行WordCount
28 // 参数:1.操作 2.窗口大小 3.窗口滑动距离
29 val result = words.reduceByKeyAndWindow((x:Int,y:Int)=>(x+y),Seconds(30),Seconds(9))
30
31 result.print()
32 ssc.start()
33 ssc.awaitTermination()
34 }
35 }
- 集成Spark SQL
- 使用SQL语句分析流式数据
1 package day0614
2
3 import org.apache.log4j.{Level, Logger}
4 import org.apache.spark.SparkConf
5 import org.apache.spark.sql.SparkSession
6 import org.apache.spark.storage.StorageLevel
7 import org.apache.spark.streaming.{Seconds, StreamingContext}
8
9 object MyNetworkWordCountWithSQL {
10 def main(args: Array[String]): Unit = {
11 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
12 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
13 // 创建一个StreamingContext对象,以local模式为例
14 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
15 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
16
17 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
18 val ssc = new StreamingContext(conf,Seconds(3))
19
20 // 创建DStream,从netcat服务器接收数据
21 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
22
23 // 进行单词计数
24 val words = lines.flatMap(_.split(" "))
25
26 // 集成Spark SQL,使用SQL语句进行WordCount
27 words.foreachRDD(rdd=> {
28 // 创建SparkSession对象
29 val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
30
31 // 把rdd转成DataFrame
32 import spark.implicits._
33 val df1 = rdd.toDF("word") // 表df1:只有一个列"word"
34
35 // 创建视图
36 df1.createOrReplaceTempView("words")
37
38 // 执行SQL,通过SQL执行WordCount
39 spark.sql("select word,count(*) from words group by word").show
40 })
41
42 ssc.start()
43 ssc.awaitTermination()
44 }
45 }

数据源
- 基本数据源
- 文件流
1 import org.apache.log4j.{Level, Logger}
2 import org.apache.spark.SparkConf
3 import org.apache.spark.storage.StorageLevel
4 import org.apache.spark.streaming.{Seconds, StreamingContext}
5
6 object FileStreaming {
7 def main(args: Array[String]): Unit = {
8 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
9 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
10 // 创建一个StreamingContext对象,以local模式为例
11 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
12 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
13
14 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
15 val ssc = new StreamingContext(conf,Seconds(3))
16
17 // 直接监控本地的某个目录,如果有新的文件产生,就读取进来
18 val lines = ssc.textFileStream("F:\\idea-workspace\\temp")
19
20 lines.print()
21 ssc.start()
22 ssc.awaitTermination()
23 }
24 }
- RDD队列流
1 import org.apache.log4j.{Level, Logger}
2 import org.apache.spark.SparkConf
3 import org.apache.spark.rdd.RDD
4 import org.apache.spark.storage.StorageLevel
5 import org.apache.spark.streaming.{Seconds, StreamingContext}
6 import scala.collection.mutable.Queue
7
8 object RDDQueueStream {
9 def main(args: Array[String]): Unit = {
10 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
11 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
12 // 创建一个StreamingContext对象,以local模式为例
13 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
14 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
15
16 // 两个参数:1.conf 和 2.采样时间间隔:每隔1s
17 val ssc = new StreamingContext(conf,Seconds(1))
18
19 // 创建队列,作为数据源
20 val rddQueue = new Queue[RDD[Int]]()
21 for(i<-1 to 3){
22 rddQueue += ssc.sparkContext.makeRDD(1 to 10)
23 // 睡1s
24 Thread.sleep(1000)
25 }
26
27 // 从队列中接收数据,创建DStream
28 val inputDStream = ssc.queueStream(rddQueue)
29
30 // 处理数据
31 val result = inputDStream.map(x=>(x,x*2))
32 result.print()
33
34 ssc.start()
35 ssc.awaitTermination()
36 }
37 }
- 套接字流(socketTextStream)
- 高级数据源
- Flume
- 基于Flume的Push模式
- 依赖jar包:Flume的lib目录,spark-streaming-flume_2.10-2.1.0
- 启动Flume:bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf Dflume.root.logger=INFO,console
- 基于Flume的Push模式
- Flume
1 import org.apache.log4j.Logger
2 import org.apache.log4j.Level
3 import org.apache.spark.SparkConf
4 import org.apache.spark.streaming.StreamingContext
5 import org.apache.spark.streaming.Seconds
6 import org.apache.spark.streaming.flume.FlumeUtils
7
8 object MyFlumeStreaming {
9 def main(args: Array[String]): Unit = {
10 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
11 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
12
13 val conf = new SparkConf().setAppName("MyFlumeStreaming").setMaster("local[2]")
14
15 val ssc = new StreamingContext(conf,Seconds(3))
16
17 //创建 flume event 从 flume中接收push来的数据 ---> 也是DStream
18 //flume将数据push到了 ip 和 端口中
19 val flumeEventDstream = FlumeUtils.createStream(ssc, "192.168.174.1", 1234)
20
21 val lineDStream = flumeEventDstream.map( e => {
22 new String(e.event.getBody.array)
23 })
24
25 lineDStream.print()
26
27 ssc.start()
28 ssc.awaitTermination()
29 }
30 }
- 基于Customer Sink的Pull模式()
- /logs-->source-->sink-->程序从sink中pull数据-->打印
- 需要定义sink组件
- 把spark的jar包拷贝到Flume下:cp *.jar ~/training/apache-flume-1.7.0-bin/
- 把spark-streaming-flume-sink_2.10-2.1.0.jar放到Flume/lib下
- 清空training/logs:rm -rf *
- 基于Customer Sink的Pull模式()
1 package day0615
2
3 import org.apache.log4j.{Level, Logger}
4 import org.apache.spark.SparkConf
5 import org.apache.spark.storage.StorageLevel
6 import org.apache.spark.streaming.{Seconds, StreamingContext}
7 import org.apache.spark.streaming.flume.FlumeUtils
8
9 object MyFlumePullStreaming {
10 def main(args: Array[String]): Unit = {
11 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
12 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
13
14 val conf = new SparkConf().setAppName("MyFlumeStreaming").setMaster("local[2]")
15
16 val ssc = new StreamingContext(conf, Seconds(3))
17
18 // 创建 DStream,从Flume中接收事件(Event),采用Pull方式
19 val flumeEventStream = FlumeUtils.createPollingStream(ssc,"192.168.174.111",1234,StorageLevel.MEMORY_ONLY)
20
21 // 从Event事件中接收字符串
22 val stringDStream = flumeEventStream.map(e =>{
23 new String(e.event.getBody.array())
24 })
25
26 stringDStream.print()
27
28 ssc.start()
29 ssc.awaitTermination()
30 }
31 }
- Kafka
- 基于Receiver:接收到的数据保存在Spark executors中,然后由Spark Streaming启动Job来处理数据
- 启动Kafka服务:bin/kafka-server-start.sh config/server.properties &
- 启动Kafka生产者:bin/kafka-console-producer.sh --broker-list bigdata111:9092 --topic mydemo1
- 在IDEA中启动任务,接收Kafka消息
1 import org.apache.log4j.{Level, Logger}
2 import org.apache.spark.SparkConf
3 import org.apache.spark.streaming.kafka.KafkaUtils
4 import org.apache.spark.streaming.{Seconds, StreamingContext}
5
6 object KafkaReceiveDemo {
7 def main(args: Array[String]): Unit = {
8 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
9 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
10
11 val conf = new SparkConf().setAppName("SparkKafkaReciever").setMaster("local[2]")
12 val ssc = new StreamingContext(conf, Seconds(10))
13
14 // 从mydemo1中每次获取一条数据
15 val topics = Map("mydemo1" -> 1)
16 // 从Kafka接收数据
17 // ssc是Spark Streaming Context
18 // 192.168.174.111:2181是ZK地址
19 // MyGroup:Kafka的消费者组,同一个组的消费者只能消费一次消息
20 // topics:Kafka的Toipc(频道)
21 val kafkaDStream = KafkaUtils.createStream(ssc, "192.168.174.111:2181", "MyGroup", topics)
22
23 val stringDStream = kafkaDStream.map(e => {
24 new String(e.toString())
25 })
26
27 stringDStream.print()
28
29 ssc.start()
30 ssc.awaitTermination()
31 }
32 }
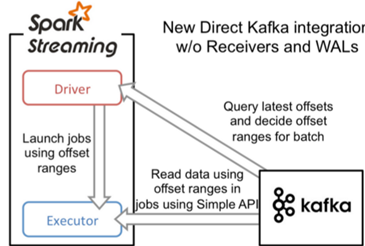
- 直接读取:定期从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量范围在每个batch里处理数据
- 效率更高
- 直接读取:定期从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量范围在每个batch里处理数据
1 import kafka.serializer.StringDecoder
2 import org.apache.log4j.{Level, Logger}
3 import org.apache.spark.SparkConf
4 import org.apache.spark.streaming.kafka.KafkaUtils
5 import org.apache.spark.streaming.{Seconds, StreamingContext}
6
7 object KafkaDirectDemo {
8 def main(args: Array[String]): Unit = {
9 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
10 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
11
12 val conf = new SparkConf().setAppName("SparkKafkaReciever").setMaster("local[2]")
13 val ssc = new StreamingContext(conf, Seconds(3))
14
15 // 参数
16 val topics = Set("mydemo1")
17 // broker地址
18 val kafkaParam = Map[String,String]("metadata.broker.list"->"192.168.174.111:9092")
19
20 // 从Kafka的Broker中直接读取数据
21 // StringDecoder:字符串解码器
22 val kafkaDirectStream = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParam,topics)
23
24 // 处理数据
25 val StringDStream = kafkaDirectStream.map(e=>{
26 new String(e.toString())
27 })
28
29 StringDStream.print()
30
31 ssc.start()
32 ssc.awaitTermination()
33 }
34 }

参考
IDEA Maven scala
https://www.jianshu.com/p/ecc6eb298b8f
kafka分区
https://www.cnblogs.com/qmfsun/p/10951282.html
与kafka整合
https://blog.csdn.net/drl_blogs/article/details/94721434
https://www.cnblogs.com/bonelee/p/7435506.html
http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
https://www.jianshu.com/p/667e0f58b7b9
最新文章
- 第三章 --- 关于Javascript 设计模式 之 代理模式
- xtrareport实现指定记录数以及填补空白行(网上整理)
- [转]Android性能优化典范
- codeforces 381 D Alyona and a tree(倍增)(前缀数组)
- viewpager viewpager+fragment
- dede源码详细分析之--全局变量覆盖漏洞的防御
- Html5时钟的实现
- (翻译)什么是Java的永久代(PermGen)内存泄漏
- Android Camera 预览图像被拉伸变形的解决方法【转】
- Linux权限体系总结
- Java菜鸟学习笔记--数组篇(二):数组实例&args实例
- linux创建用户和组
- 系统运维-hub, repeater, switch, router初览
- Stimulsoft.Report.net报表简单实用
- pb9常见错误及含义
- ELK原理与简介
- 打开visual studio 2010报错:未能正确加载“VSTS for Database Professionals Sql Server Data-tier Application”包
- Java 关键字 static
- maven一键部署tomcat war包
- 22-Python3 输入和输出