用requests-html和SelectorGadget轻松精准抓取网页数据
2024-09-08 19:31:08
我们在抓取网页数据时,最常採用Python的requests搭配BeautifulSoup的模式来完成。然而,requests-html整合了上述2个套件,又添加了新的功能,或许是抓取网页数据值得考虑的新选项。我们来看个实例,假设我们想要抓取stackoverflow网站上有关Python问题第1页的标题,先在网页上按"F12"查看网页原始码;我们会发现"a.s-link"可能会是个不错的CSS Selector。
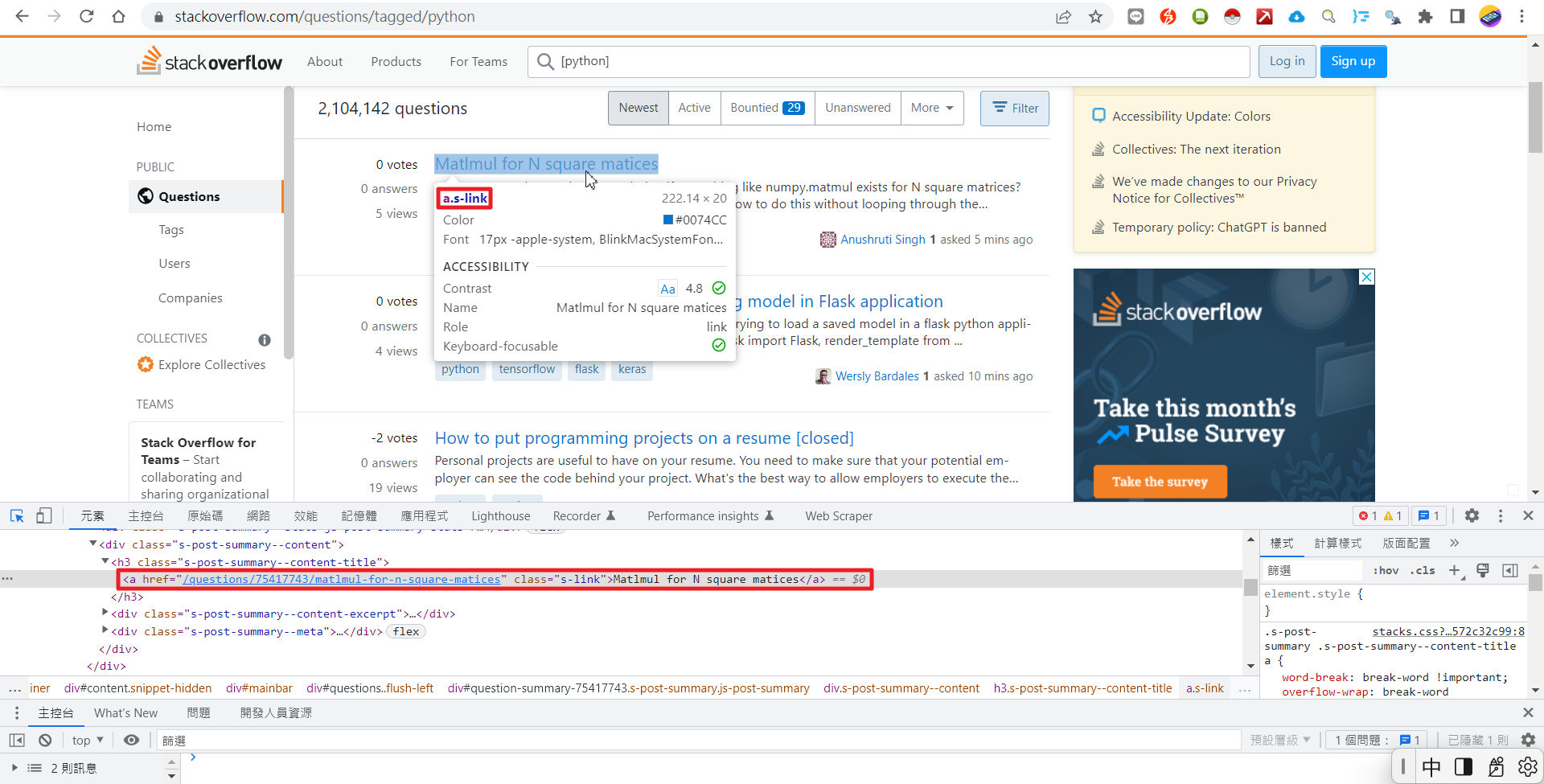
因此,初步尝试撰写爬虫代码如下:
1 from requests_html import HTMLSession
2
3 session = HTMLSession()
4 keyword = 'Python'
5 url = f'https://stackoverflow.com/questions/tagged/{keyword}'
6 r = session.get(url)
7 titles = r.html.find('a.s-link')
8
9 for title in titles:
10 print(title.text)
可是,程式执行之后;我们会看到数据的上方多了2行空白,下方的"Hot Network Quesions"又不是我们想要的数据。
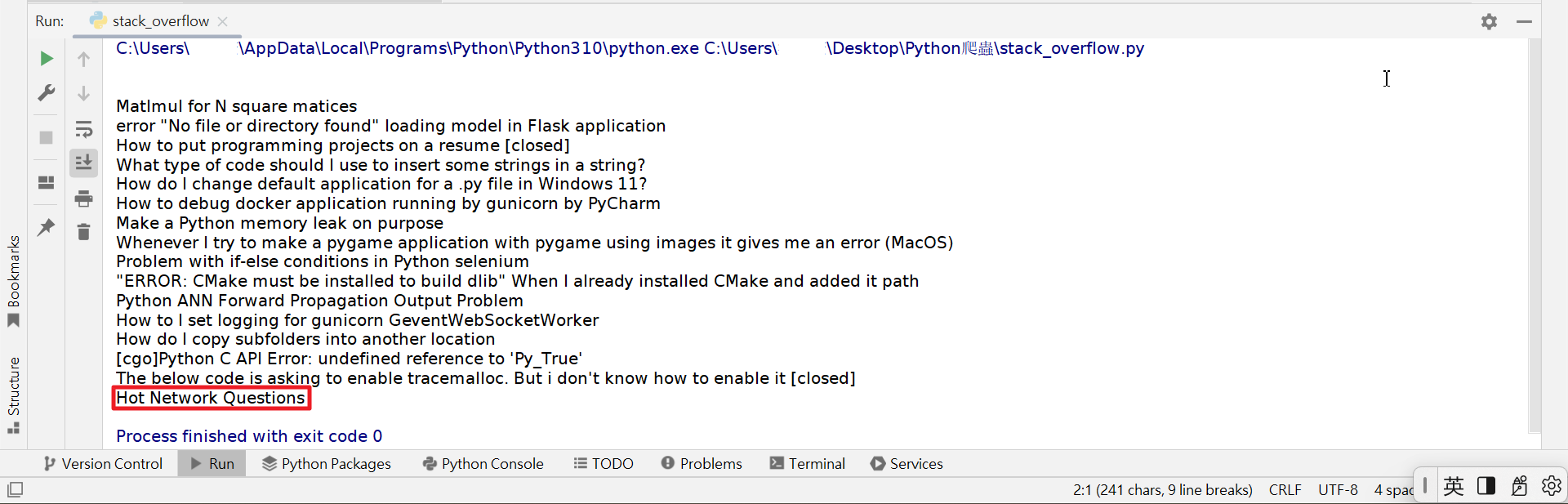
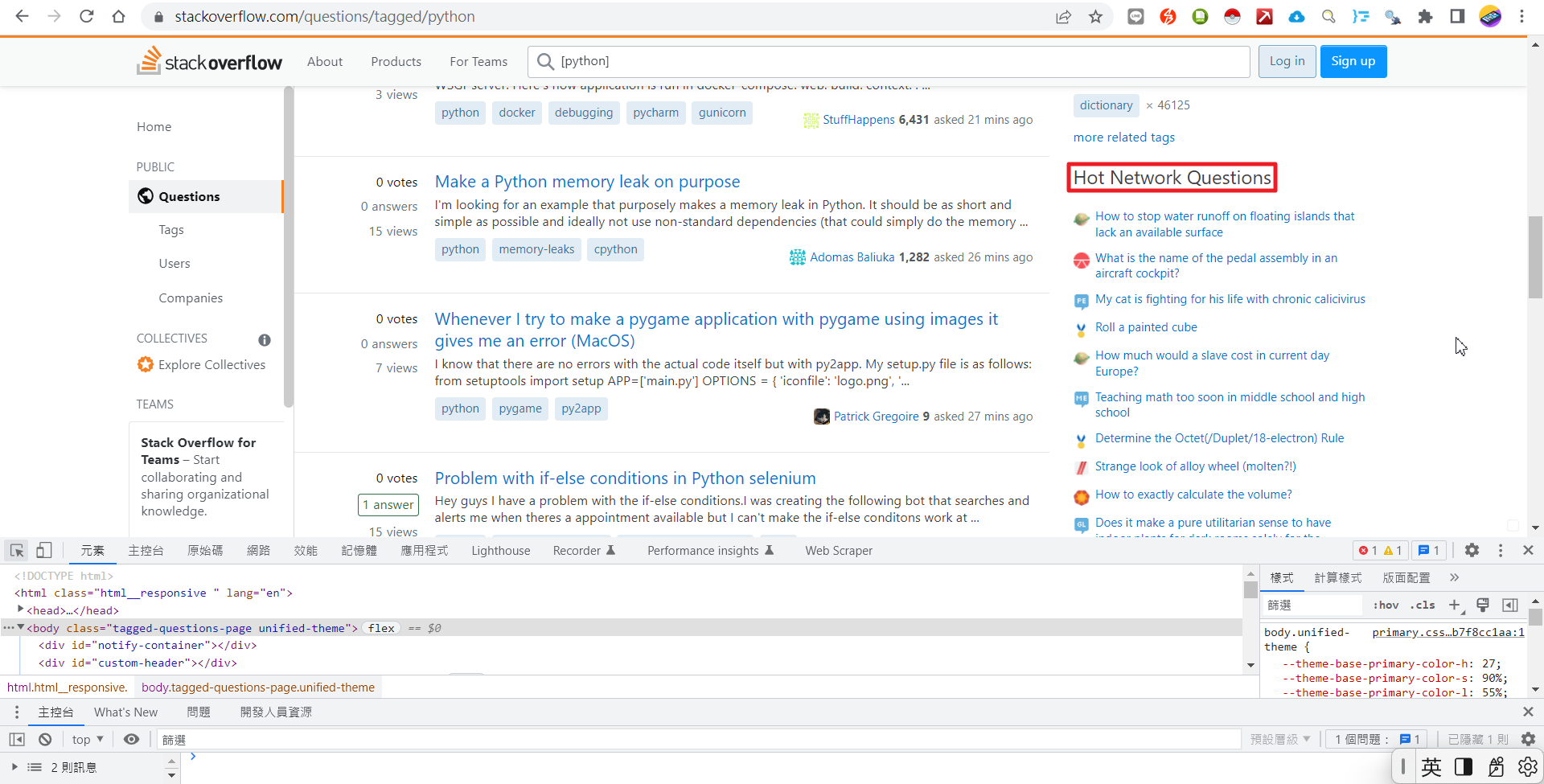
显然,我们设定的CSS Selector不太正确。在修正这个问题之前,我们先把SelectorGadget这个Chrome浏览器的插件安装好,并钉选在工具列上以方便日后操作。启动SelectorGadget之后,点选stackoverflow页面上的任1个问题的标题;选中的标题会变成绿色,其他的标题会变成黄色;但同时会看到"Hot Network Quesions"也变成了黄色。此时,再点选"Hot Network Quesions",会让"Hot Network Quesions"变成红色而被排除在外。
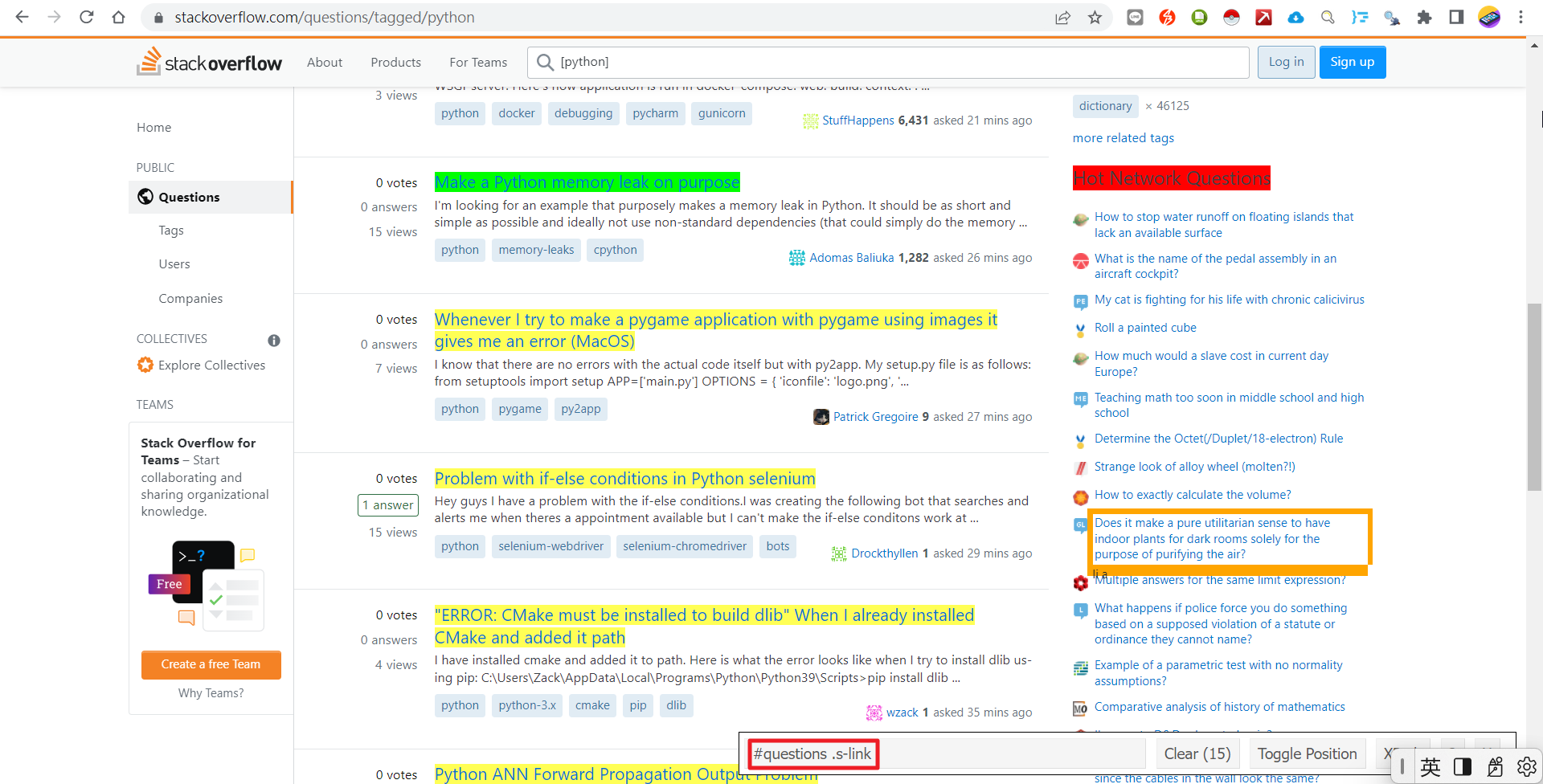
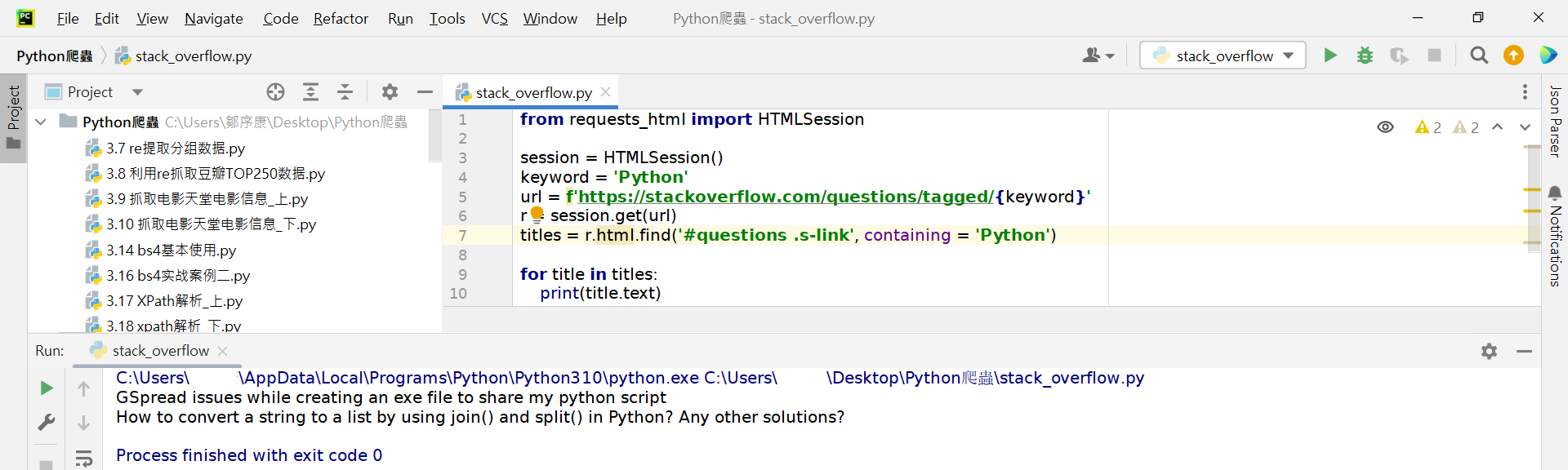
对SelectorGadget视窗左方的CSS Selector按滑鼠右键选"複製",取代原先代码中的CSS Selector。
titles = r.html.find('#questions .s-link')
再次执行程式,我们会看到果然输出了正确的结果。
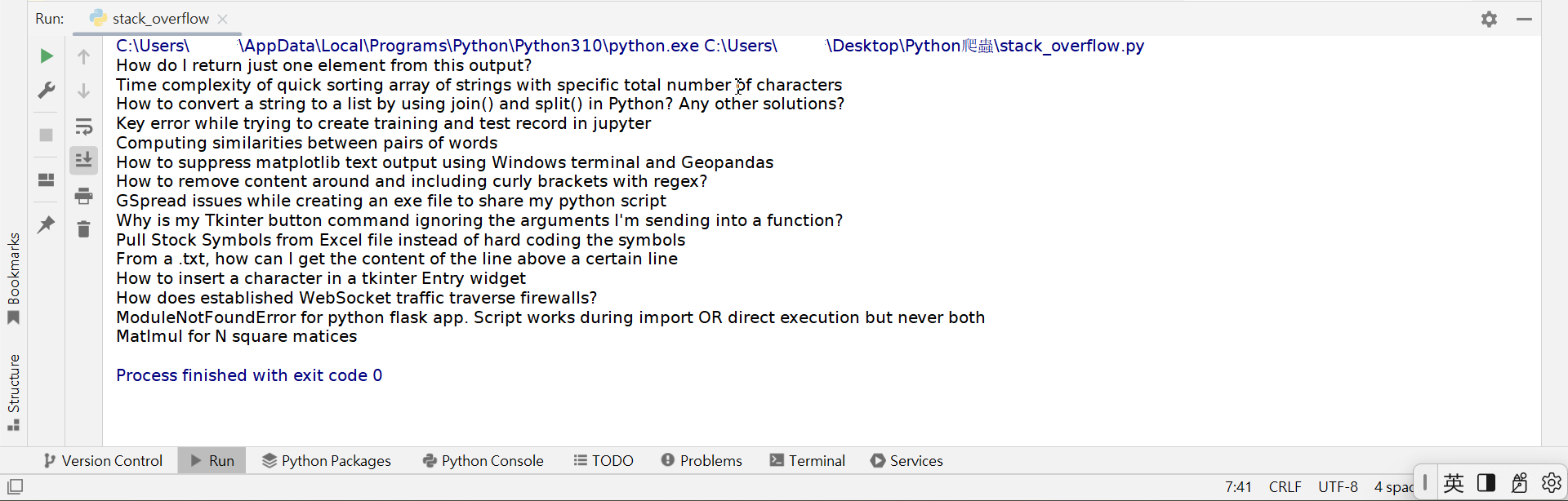
如果我们想要更进一步精准地从上面的标题中挑出含有"Python"的标题,也是非常容易地喔。只要在find()方法中添加containing参数即可。
有没有发现requests-html搭配SelectorGadget真得是超好用的呢?!
最新文章
- 文件上传大小js判断
- Atitit 图像处理知识点体系知识图谱 路线图attilax总结 v4 qcb.xlsx
- P1032 字串变换
- css中常用的几种居中方法
- Web工程软件升级之数据库升级(一)
- [转]JavaScript ES6 class指南
- PAT (Advanced Level) 1010. Radix (25)
- javascript学习-类型判断
- html结合js实现简单的树状目录
- 淘宝tairKV分布式
- Mysql数据库性能优化(一)
- easyui改变tab标题
- 数值分析之Neville's Algorithm
- CentOS搭建内网NTP服务器
- struts开发<struts中的參数传递.三>
- oracle的学习笔记
- 解决Failure to transfer org.apache.maven.plugins:maven-surefire-plugin:pom:2.12.4
- 优化 resolv.conf
- Linux命令 lsof使用
- object-oriented 第二次作业(2)