python学习-Day9
2024-10-19 14:37:42
目录
记忆不清点回顾
- 字符编码只针对文本文件
字符编码相关知识
ASCII码:记录了英文字符与数字的对应关系
1bytes(8bit)来表示英文
"""
A-Z:65-90
a-z:97-122
""" GBK:记录了英文、中文与数字的对应关系
1bytes(8bit)来表示英文
2bytes(16bit)来表示中文(很多时候都是3bytes)
Euc_kr:记录了英文、韩文与数字的对应关系
shift_JIS:记录了英文、日文与数字的对应关系
"""
乱码:'编写'和'翻译'阶段使用的编码表不一致
""" unicode:万国码
所有的字符都是2bytes起步存储
会浪费空间和IO时间
utf8:万国码的转换版本
"""
内存使用的是unicode 硬盘使用的是utf8
"""
今日概要
- 大作业讲解
- 字符编码的实际应用
- 文件操作简介
- 文件的读写模式
- 文件的操作模式
- 文件内置方法
今日内容
大作业讲解
"""
写代码最好写一个功能就测试一个,这样可以缩小排查范围
"""
# 代码实战篇
# 1.添加员工信息
# 提示:编号(不能重复)、姓名、年龄、薪资
# 2.查询特定员工
# 提示:根据编号查找 展示结构用格式化输出美化
# 3.修改员工薪资
# 提示:先根据编号查找之后再修改薪资
# 4.查询所有员工
# 提示:循环一行行展示
# 5.删除特定员工
# 提示根据编号确定
# 答案:
# 1.定义一个存储用户数据的字典
user_data_dict = {}
"""
{'员工编号':{员工数据}, '员工编号':{员工数据}, '员工编号':{员工数据}}
"""
# 2.循环打印系统功能
while True:
print("""
1.添加员工信息
2.修改员工薪资
3.查看指定员工
4.查看所有员工
5.删除员工数据
""")
# 3.获取用户想要执行的功能编号
choice = input('请输入您想要执行的功能编号>>>:').strip()
# 4.判断用户想要执行的功能
if choice == '1':
# pass # TODO:补全语法 但是本身没有任何功能
# 1.先获取员工编号
emp_id = input('请输入新员工的编号>>>:').strip()
# 2.判断员工编号是否已存在 如果存在则提示重复 不存在则正常往下执行
if emp_id in user_data_dict:
print('员工编号已存在 无法添加')
continue # 3.存在 则直接结束本次循环
# 4.正常获取员工的其他数据
emp_name = input('请输入员工的姓名>>>:').strip()
emp_age = input('请输入员工的年龄>>>:').strip()
emp_salary = input('请输入员工的薪资>>>:').strip()
# 5.临时构建一个用户小字典
user_dict = {'emp_id': emp_id, 'emp_name': emp_name, 'emp_age': emp_age, 'emp_salary': emp_salary}
# 6.将数据添加到大字典中
user_data_dict[emp_id] = user_dict # 键不存在则新增键值对
# 7.打印提示信息
print(f'员工{emp_name}添加成功')
elif choice == '2':
# 1.先获取想要修改薪资的员工编号
target_id = input('请输入您想要修改的员工编号>>>:').strip()
# 2.判断当前编号是否存在
if target_id not in user_data_dict:
print('员工编号不存在 无法修改')
continue # 3.存在 则直接结束本次循环
# 4.获取对应员工的字典
user_dict = user_data_dict.get(target_id)
# 5.获取新的薪资
new_salary = input('请输入该员工新的薪资待遇>>>:').strip()
# 6.修改员工字典数据
user_dict['emp_salary'] = new_salary
# 7.修改大字典数据
user_data_dict[target_id] = user_dict
# 8.提示信息
print(f'编号为{target_id}的员工薪资成功修改为{new_salary}')
elif choice == '3':
# 1.获取员工编号
target_id = input('请输入您想要查看的员工编号>>>:').strip()
# 2.判断当前编号是否存在
if target_id not in user_data_dict:
print('员工编号不存在 无法查看')
continue # 3.存在 则直接结束本次循环
# 4.直接获取对应的员工数据字典
user_dict = user_data_dict.get(target_id)
# 5.打印员工数据
print("""
------------emp info------------
员工编号:%s
员工姓名:%s
员工年龄:%s
员工薪资:%s
---------------end--------------
""" % tuple(user_dict.values())) # %(1,2,3,4) 简便写法
elif choice == '4':
for user_dict in user_data_dict.values(): # {} {} {}
print("""
------------emp info------------
员工编号:%s
员工姓名:%s
员工年龄:%s
员工薪资:%s
---------------end--------------
""" % tuple(user_dict.values())) # %(1,2,3,4) 简便写法
# print("""
# ------------emp info------------
# 员工编号:%s
# 员工姓名:%s
# 员工年龄:%s
# 员工薪资:%s
# --------------end---------------
# """ % (user_dict.get('emp_id'), user_dict.get('emp_name'), user_dict.get('emp_age'),
# user_dict.get('emp_salary'))) # %(1,2,3,4)
elif choice == '5':
# 1.获取想要删除的员工编号
delete_id = input('请输入您想要删除的员工编号>>>:').strip()
# 2.判断当前编号是否存在
if delete_id not in user_data_dict:
print('员工编号不存在 无法删除')
continue # 3.存在 则直接结束本次循环
# 3.根据字典的key删除数据
res = user_data_dict.pop(delete_id)
# 4.提示
print(f'员工信息删除完毕',res)
else:
print('请输入正确的功能编号')

字符编码实际应用
编码与解码
编码
将人类能够读懂的字符编码成计算机能够直接读懂的字符
s1 = '事已至此 何不一搏'
# 编码 encode
print(s1.encode('gbk'))
解码
将计算机能够直接读懂的字符解码成人类能够读懂的字符
# 解码 decode
res = b'\xca\xc2\xd2\xd1\xd6\xc1\xb4\xcb \xba\xce\xb2\xbb\xd2\xbb\xb2\xab'
print(res.decode('gbk'))
"""
字符串前面如果加了字母b 表示该数据类型为 bytes类型
bytes类型可以看成是二进制
"""
"""
基于网络传输数据 数据都必须是二进制格式
所以肯定涉及到编码与解码
"""
# 3.python解释器层面
python2解释器默认的编码是ASCII码
1.文件头:必须写在文件的最上方 告诉解释器使用指定的编码
# coding:utf8
# -*- coding:utf8 -*- 美化写法
2.字符前缀:在使用python2解释器的环境下定义字符串习惯在前面加u
name = u'你好啊'
python3解释器默认的编码是utf8
如何解决乱码的问题
数据当初以什么编码编写的 就以什么编码解码即可
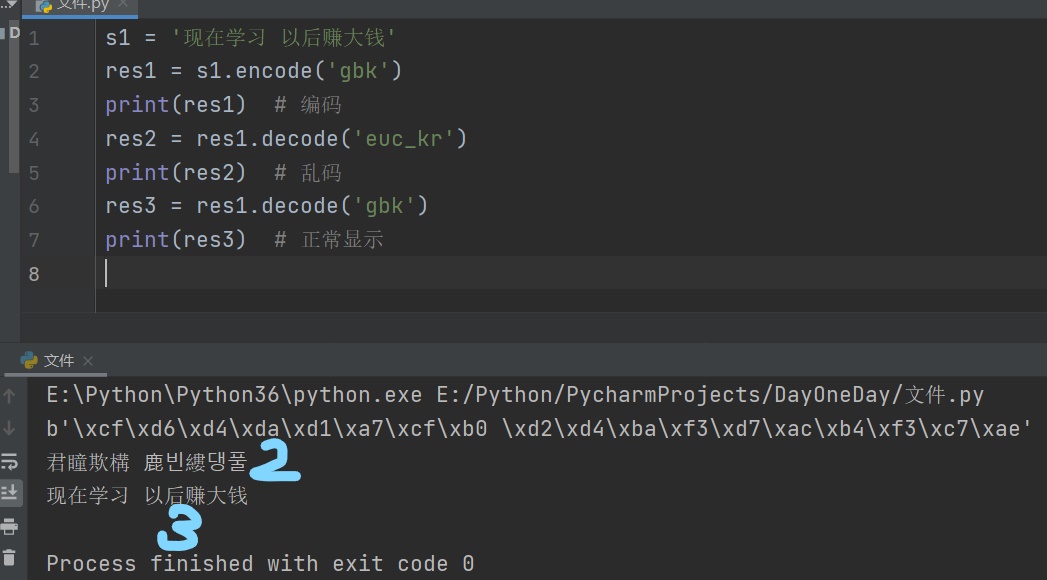
res1 = s1.encode('gbk')
print(res1) # 编码
res2 = res1.decode('euc_kr')
print(res2) # 乱码
res3 = res1.decode('gbk')
print(res3) # 正常显示
文件操作简介
什么是文件
操作系统暴露给用户可以直接操作硬盘的快捷方式(接口)
代码操作文件
代码操作文件的流程
1.打开文件、创建文件
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
2.编辑文件内容
data=f.read()
data=f.writ()
3.保存文件内容
4.关闭文件
f.close()
基本语法结构
结构1(了解即可):
f1 = open()
f1.close()
结构2(推荐使用):
with open() as f:
pass
使用关键字打开文件
'''以后写路径为了防止特殊符号 直接加r'''
open(r'a.txt') # 相对路径
open(r'D:\py1\day09\a.txt') # 绝对路径
res = open(r'a.txt', 'r', encoding='utf8')
"""
open(文件的路径,文件的操作模式,文件的编码)
1.文件的路径是必写的
2.文件的操作模式、文件的编码有时候不用写
"""
print(res.read()) # 读取文件内容
res.close() # 关闭文件
"""上述操作open完,最后都需要执行close() 但经常被遗忘"""
with上下文管理
with open(r'a.txt', 'r', encoding='utf8') as f: # f = open()
data = f.read()
print(data)
文件的读写模式
r read 只读模式:只能读不能写
w write 只写模式:只能写不能读
a append 只追加模式:在文件末尾添加内容
r 模式
with open(r'b.txt', 'r', encoding='utf8') as f1:
# pass (推荐)补全语法结构 本身没有任何功能
# ... (不推荐)补全语法结构 本身没有任何功能
pass
# 路径存在:正常打开文件并等待内容读取
with open(r'a.txt', 'r', encoding='utf8') as f1:
print(f1.read()) # 一次性读取文件内所有的内容
f1.write('学会python!!!') # 报错
"""
readable 具备读的能力
writable 具备写的能力
"""
w 模式
# 路径不存在:自动创建文件
with open(r'b.txt', 'w', encoding='utf8') as f1:
# pass (推荐)补全语法结构 本身没有任何功能
# ... (不推荐)补全语法结构 本身没有任何功能
pass
# 路径存在:先清空文件内容 之后再写入数据
with open(r'a.txt', 'w', encoding='utf8') as f1:
f1.write('你们是我见过的最优秀一批学生1\n') # 写入文件内容
f1.write('你们是我见过的最优秀一批学生2\r') # 写入文件内容
f1.write('你们是我见过的最优秀一批学生3\n') # 写入文件内容
print(f1.read())
换行
"""
换行在最早的时候:\r\n
为了节省空间支持一个字符 根据操作系统的不同可能有所区别
\n 、 \r
"""
a 模式
# 路径不存在:自动创建文件
with open(r'c.txt', 'a', encoding='utf8') as f1:
pass
# 路径存在:不会清空文件内容 而是在文件末尾等待新内容的添加
with open(r'a.txt', 'a', encoding='utf8') as f1:
f1.write('她怎么还不向我表白')

文件的操作模式
t模式
文本模式-->是默认的模式
r rt
w wt
a at
1.该模式只能操作文本文件
2.该模式必须要指定encoding参数
3.该模式读写都是以字符串为最小单位
b模式
二进制模式-->可以操作任意类型的文件
rb 不能省略b
wb 不能省略b
ab 不能省略b
1.该模式可以操作任意类型的文件
2.该模式不需要指定encoding参数
3.该模式读写都是以bytes类型为最小单位
文件内置方法
read() # 一次性读取文件内容
1.执行完之后光标在文件末尾 继续读取没有内容
2.当文件内容特别大的时候 容易造成内存溢出(满了)
readline() # 一次只读一行内容
readlines() # 结果是一个列表 里面的各个元素是文件的一行行内容
readable() # 判断当前文件是否可读
支持for循环 # 一行行读取文件内容(推荐使用) 内存中同一时刻只会有一行内容
write() # 写入文件内容(字符串或者bytes类型)
writelines() # 可以将列表中多个元素写入文件
writable() # 判断文件是否可写
flush() # 相当于主动按了ctrl+s(保存)

没啦~
最新文章
- Spring4读书笔记(2)- 使用场景
- View加载过程
- XidianOJ 1120 Gold of Orz Pandas
- python学习之路-day4-装饰器&json&pickle
- 【转】去掉eclipse的validate
- [原]最短路专题【基础篇】(updating...)
- C++STL 之排列
- @Entity设置实体lazy = false
- 数据库中substring的使用方法 CONVERT(varchar(12) , getdate(), 112 )
- [Leetcode] Binary search, Divide and conquer--240. Search a 2D Matrix II
- PAT (Basic Level) Practise (中文) 1017. A除以B (20)
- 利用阿里云Centos7建站过程
- 动态的加载显示oracle警告日志文件内容
- Habits of Considerate People
- wxWidgets 在 Linux 下开发环境配置
- myBatis学习之路1-基本功能实现
- iOS 11开发教程(十九)iOS11应用视图美化按钮之设置按钮的外观
- java String 内存模型
- PeopleSoft 多套Web App Prcs交叉访问
- 使用 C# 编写简易 ASP.NET Web 服务器 ---- 模拟IIS的处理过程
热门文章
- ES6中对象新增的方法
- 生命周期内create和mounted的区别?
- Correct the classpath of your application so that it contains a single, compatible version of org.springframework.util.Assert
- 如何从https://developer.mozilla.org上查询对象的属性、方法、事件使用说明和示例
- 微信小程序中涉及虚拟产品购买,ios暂不支持的相关整理意见
- django REST框架- Django-ninja
- 模拟web服务器http请求应答
- Chrome 53 Beta一些有意思的改动
- java连接oracle数据库(转)
- 第一天·浏览器内核及Web标准