【基础】字符编码-ASCII、Unicode、utf-8
一、各自背景
1. ASCII
ASCII 只有127个字符,表示英文字母的大小写、数字和一些符号。但由于其他语言用ASCII编码表示字节不够,例如:常用中文需要两个字节,且不能和ASCII冲突,中国定制了GB2312编码格式,相同的,其他国家的语言也有属于自己的编码格式。这导致了在多语言混合的文本中,显示出来会有乱码。
2. Unicode
由于每个国家的语言都有属于自己的编码格式,在多语言编辑文本中会出现乱码,这样Unicode应运而生,Unicode就是将这些语言统一到一套编码格式中。Unicode通常两个字节表示一个字符,而ASCII是一个字节表示一个字符,这样如果你编译的文本是全英文的,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
3. Utf-8
为了解决上述问题,又出现了把Unicode编码转化为“可变长编码”UTF-8编码,UTF-8编码将Unicode字符按数字大小编码为1-6个字节,英文字母被编码成一个字节,常用汉字被编码成三个字节,如果你编译的文本是纯英文的,那么用UTF-8就会非常节省空间,并且ASCII码也是UTF-8的一部分。
二、三者关系
搞清楚了ASCII、Unicode和UTF-8的背景,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
(1) 在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
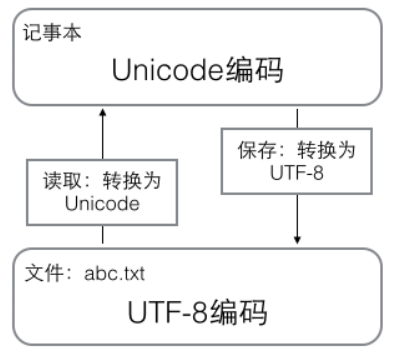
(2) 用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
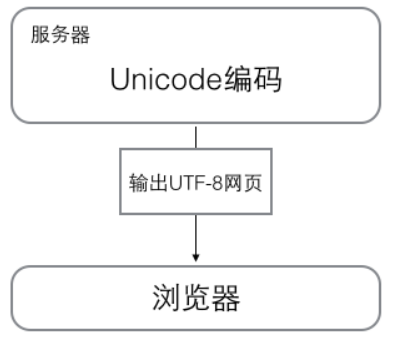
(3)浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
三、总结
utf-8变长编码意味着要判定长度时需要计算,在编辑时用会耗费额外的计算成本,为了提高运行速度可以使用Unicode。而存储为了节省空间,使用utf-8. 也就是说编辑时用Unicode减少判定时间,保存时用utf-8节省存储空间。
最新文章
- PHP_Cli模式初涉——转载一篇
- webApi 数据绑定 获取
- Masonry的使用
- 0823--静默安装、fiddler设置断点、f12清除数据记录
- ubuntu下ssh使用proxy:corkscrew
- Winform程序以Icon的形式显示在任务栏右下角
- jQuery/javascript实现网页注册的表单验证
- ASP.NET MVC的路由
- [mysql] mysql主从复制(基于日志点)
- mysql C API 字符串玩转备份调优
- android学习3——长宽的单位问题dp,px,dpi
- IDEA之Jrebel插件激活
- Linux下的Shell编程(1)最简单的例子
- python笔记:#004#注释
- Vue-admin工作整理(十一):Vuex-动态注册模块
- 搞Java的年薪 40W 是什么水平?
- Confluence 6 CSS 编辑快速入门
- Rancher2.0导入本地RKE Kubernetes集群图解
- Java:ConcurrentHashMap
- AS 自定义 Gradle plugin 插件 案例 MD