Ensemble learning A survey 论文阅读
Ensemble learning A survey是2018年发表的一篇关于集成学习的综述性论文
发展
在Surowiecki的书中The Wisdom of Crowds,当符合以下标准时,大众的智慧可能会超过一个决策者
1. 独立性:一个人的观点不受他人观点的影响。
2. 分散化:一个人能够根据当地信息进行专门化和得出结论。
3.多样性:一个人应该持有个人意见,即使它只是对已知事实的古怪解释。
4. 聚合:存在将个人判断转变为集体决策的机制。
这些概念在监督学习的背景下的表现已经被探索,Tukey (1977)提出了两个线性回归模型的集合。Tukey建议对原始数据拟合第一个线性回归模型,对残余的拟合第二个线性模型。Dasarathy和Sheela(1979)建议使用两个或两个以上不同类别的分类器组成一个分类性能更好的系统。90年代在这一领域取得了重大进展。Hansen and Salamon(1990)表明,在集成神经网络时,可以降低神经网络的泛化误差。Schapire(1990)展示了在一个可能近似正确的意义上组合几个弱学习器如何胜过一个强学习器。这项工作为著名的AdaBoost (adaptive boosting)算法奠定了基础。
集成学习的优点:1)过拟合避免。 2)计算性能优势,集成学习降低了陷入局部最小值的风险。 3)最优假设可能在任何单一模型的空间之外。通过结合不同的模型,可以扩展搜索空间,从而更好地适应数据空间。
集成学习处理的一些挑战:
1)类别不平衡:许多算法面对类别不平衡时,偏好多数类,忽略少数类。集成学习可以应对这样的问题,创建一个集合,其中每个基学习器都使用数据的是平衡子样本进行训练(Nikulin & Ng, 2009)。将随机欠采样技术与集成技术(如bagging或boost)相结合,可以显著提高对阶级不平衡问题的预测性能(Galar, Fernandez, Barrenechea, Bustince, & Herrera, 2012)。EUSBoost利用改进的欠采样来促进基学习器的多样性(Galar, Fernandez, Barrenechea, & Herrera, 2013)。
2)概念漂移:在许多实时机器学习应用程序中,特征和标签的分布往往会随着时间而改变,这种现象经常会影响模型的预测性能。动态加权多数(DWM)(Kolter & Maloof, 2003),根据预测性能的变化动态创建和删除单个决策树。另一项研究考察了集成多样性水平如何影响它们对新概念的概括(Minku, White, & Yao, 2010)。这项工作还表明,基学习器多样性可以减少由漂移引起的“误差的初始增加”(initial increase in error)。DDD(Minku & Yao, 2012)方法,在漂移检测发生之前使用低多样性森林。在检测到漂移后,训练新的低多样性森林和高多样性森林,并根据(a)老的高多样性森林,(b)新的低多样性森林和(c)老的低多样性森林的加权多数投票对新实例进行预测。关于概念漂移的更多介绍可以参考我上一篇论文阅读。
3)维度灾难:增加输入到机器学习模型中的特征的数量通常会成倍地增加搜索空间,因此,无法推广的拟合模型的概率也会增加。(Bryll, Gutierrez-Osuna和Quek,2003)引入了属性bagging (AB),一种使用随机选择的特征子集来训练诱导器的方法。AB还试图通过评估不同子集大小所获得的精度来确定特征子集的合适大小。(IDF; Huang, Fang, & Fan, 2010)通过应用指定的特征选择机制来处理高维数据集。Rokach(2008)提出了一种搜索特征集最佳互斥划分的算法,取代了随机划分。 最优特征集划分(OFSP)方法创建固定数量的特征视图,以降低维数和优化精度(Kumar & Minz, 2016)。
集成学习模型训练策略
集成模型一般有两点原则,1)多样性:的优越性能主要是由于使用了各种“inductive biases”(Deng, Runger, Tuv, & Vladimir, 2013). 2)表现性能,至少应该比随机猜测高。
不同类基学习器的集成并不总是能提高预测性能(Bi, 2012)。整体集成模型的预测性能 与 不相关的基学习器造成错误程度 是正相关的(Ali & Pazzani, 1995).
(Chan & Stolfo, 1995a) 对不同的基学习器使用不同的训练样本,样本可能是随机的,也可能是基于类别分布的。
(Brown, Wyatt, & Tiňo, 2005) 改变基学习器的收敛路径来产生不同的学习器,例如,决策树中在选择最佳划分属性时加入随机性。
Distributing neighbors (Maudes, Rodríguez, & García-Osorio, 2009) 是一种通过生成原始特征的不同组合来扩展特征空间的方法
(Lin & Chen, 2012)通过改变一些超参数来获得不同的学习器。例如,用不同的学习率、不同的层次和属性等来训练一个神经网络诱导器。
(Chawla, Hall, Bowyer, & Kegelmeyer, 2004). horizontal partitioning水平分割数据集,将数据集分成包含整个特征集的多个集合。
(Rokach, 2008). Vertical partitioning垂直分割将数据集分为使用相同样本,不同特征的多个集合.
(Feating; Ting, Wells, Tan, Teng, & Webb, 2011) 特征子空间聚合方法,通过预定的特征数量将数据分割。
(Feating; Błaszczynski, Stefanowski, & Słowinski, 2016)有序一致性驱动的特征子空间聚合,将属性空间细分为局部区域。该方法对产生一致区域的分区进行优先排序。CoFeating在具有大量属性的数据集中表现良好。
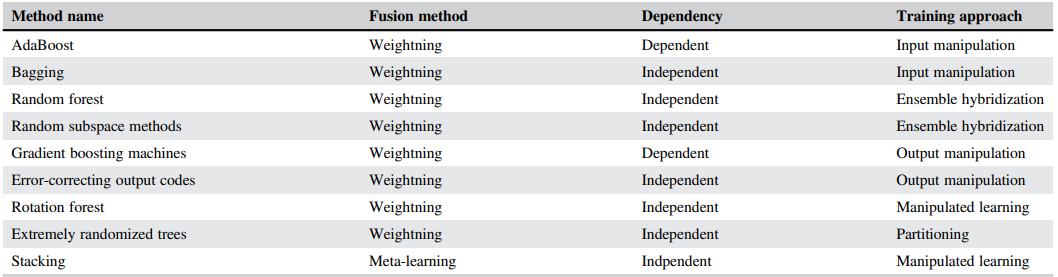
(Dietterich & Bakiri, 1995) ECOC码将 多个二分类器组合成多分类器。文章很多,不介绍。
(Zhong & Cheriet, 2013) AECOC 在训练不同的二进制分类器时增加了常规约简( conventionality reduction )过程。
n元纠错编码方案是一种最近发展起来的方法,它将主要的多类分类器分解为更简单的多类子问题(Zhou,Tsang, Ho, & Muller, 2016)。
(Zhang & Zhang, 2008).RotBoost是结合了 旋转森林 和 AdaBoost的一种方法,在每一轮迭代中,都生成一个新的Rotation Matrix旋转矩阵来生成新的数据集,然后再用AdaBoost。
(Bernard, Adam, & Heutte, 2012)动态随机森林,自适应树归纳。每棵树的训练都是由它如何补充已经训练过的树来指导的。通过使用与随机森林相关的重采样方法和随机化过程来实现。
(GarcÃa-Pedrajas, GarcÃa-Osorio, & Fyfe, 2007).每轮都对被误分类的样本创建新基学习器。
(Blaser & Fryzlewicz, 2016)随机旋转集成,在训练每个基学习器时都对特征空间进行旋转。该方法对包含许多连续特征的问题是有效的。
集成学习结果聚合策略
权重法,权重法适用于基学习器的性能可比较的情况。投票法就是最简单的权重法,
在贝叶斯组合方法中,权重是基于给定整个数据集得到模型的概率概率(Duan, Ajami,Gao, & Sorooshian, 2007)
(Schapire and Singer ,1998)使用基于置信度的结果聚合,置信度的计算是基于决策树可到达的叶节点数量。
(Derbeko, El-Yaniv, & Meir, 2002)是方差优化bagging or bogging的方法,基于方差来做的。
权值也可以通过使用目标函数来分配,即将权重也作为学习的一环,目标是误差最小(Mao et al., 2015)。
(Haque, Noman, Berretta, & Moscato, 2016)提出使用Matthews相关系数(MCC)作为权重选择的度量。
Meta-learning method:元学习是让学习器学会学习的一种表述。在元学习中,一个基学习器的输出将作为元学习的输入,最终产生输出。
Stacking是最流行的元学习技术(Wolpert, 1992),该方法通过使用元学习器,试图归纳出哪些基本模型是可靠的,哪些是不可靠的。在stacking中,我们创建了一个元数据集,其中包含了在原始数据集中发现的相同数量的实例。
Troika (Menahem, Rokach, & Elovici, 2009)旨在提高多类数据集的预测性能
Arbiter trees, combiner trees and grading(Chan & Stolfo, 1995b;Seewald & Furnkranz, 2001)是为集成基学习器的输出而开发的额外元学习算法。
加权bagging (Shieh & Kamm, 2009)的特点是一个预处理过程,在这个过程中,利用核密度估计器根据点与目标类的接近程度给点分配概率权重。
(ME)是元学习的一种非常流行的变体,它依赖于分治的思想,因为问题空间是由几个experts来划分的。ME使用错误函数来为数据空间的不同分布定位最合适的基模型(Jacobs, Jordan, Nowlan, & Hinton, 1991)
Omari and Figueiras-Vidal (2015)使用了一种后聚合方法用于集成大规模的决策树。第一步,用权重法对 每一个决策树进行初始聚合。第二步,用机器学习的方法对初始聚合的结果进行再聚合。
算法
AdaBoost的变体
Soft margin Adaboost (Ratsch,Onoda, & Muller, 2001) 在算法中使用正则化来缓解离群值的影响
Modest Adaboost (Vezhnevets & (Vezhnevets, 2005) 增加了正则化,提高了模型的泛化,但降低了训练的准确性
SpatialBoost (Avidan, 2006) 将 Spatial reasoning与Adaboost结合。
Palit and Reddy (2012) 使用MapReduce模式,做了可并行的AdaBoost.PL and LogitBoost.PL
bagging的变体
改进的bagging算法(IBA; Jiang, Li, Zheng, & Sun, 2011),采样过程中加入了信息熵,提高了一定的泛化能力。
online bagging(Oza, 2005)提高了运行速度。
Waggingg (weight aggregation; Bauer & Kohavi, 1999)对每个样本分配权重。
在Double-bagging(Hothorn & Lausen, 2003)中,每次迭代使用包外示例训练两个分类器
随机森林or随机子空间
具有实时性的Random Forest 考虑了概念漂移的影响(Saffari, Leistner, Santner, Godec, & Bischof, 2009),该版本增加了一种时间加权方案,该方案根据树在不同时间间隔内的误差自适应地排除一些树,然后生长新的树来替代被排除的树。
random subspace method (RSM; Ho, 1998)不需要使用决策树作为基学习器。
(Kamath & Cantu-Paz, 2001)使用特征分割后的样本中的一部分来训练。
Kulkarni and Sinha (2013)专门做了一篇关于随机森林的综述。
(Han, Jiang, Zhao, Wang, & Yin, 2018)最近的研究发现,与极限学习机、支持向量机和神经网络相比,随机森林的鲁棒性和稳定性更强,特别是在训练集较小的情况下。
Gradient boosting machines
梯度提升算法与其他技术不同的地方是,GBM优化应用于函数空间(function space.)???更具体的,GBM,计算一连串的回归树,每一棵连续树预测前一棵树的伪残差并给出一个可微的损失函数。通常它的数比RF更广,而RF则更深。
使用随机梯度增强方法(Friedman, 2002)可以减少过拟合,该方法使用从原始数据集中采样的小子集连续训练树。
XGBoost (Chen & Guestrin, 2016)是一个可调整的机器学习系统,用于树提升。XGB对GMB进行了几点优化,首先是特征选择上,(a)处理稀疏数据的节点默认方向,(b)使用合并和修剪操作处理加权数据,(c)有效地枚举所有可能的分割,以便分割阈值得到优化。XGBoost中另一个重要的改进是,它在GBM中呈现的损失函数中添加了一个正则化组件,目的是创建更简单、更有泛化能力的集成学习器。最后,XGBoost可以运行的很快,它支持分布式运算。
LightGBM是微软开发的另一种梯度增强方法,也有很多文章介绍。
rotation forest
旋转森林是通过旋转特征来生成多样性的方法,当训练集形成时,特征被随机划分为K个子集,并对每个子集应用PCA。有效的为每一个基学习器提供了有效的特征。除了促进树间的多样性,旋转树还减轻了决策树只将输入空间分割成与原始特征轴平行的超平面的限制。但是该算法,计算成本高于随机森林,其旋转后的特征可解释性降低。
Schclar and Rokach (2009)推荐使用随机选择特征,而不是PCA选择特征。每一个派生特征都是原始特征的线性组合。
(Ahmad & Brown, 2014)随机投影随机离散化集合(RPRDE)是一种旋转森林变体,它从连续特征中创建离散特征
Extremely randomized trees
是另一种在训练过程中注入随机性的方法。除了从随机子集中选择最优特征,特征分割点也具有随机性。与随机森林的区别还包括,并不对训练集做预处理。. Geurts et al.证明了虽然极限随机数有高偏差和方差,但足够大的树集合可以消除这一点。
集成学习与深度学习
Deep neural decision forests (Kontschieder, Fiterau, Criminisi, & Rota Bulo, 2015) 结合了决策森林和神经网络。通过随机反向传播使决策树生成决策森林。
另一个由cnn组成的集成的例子,最近被开发用于面部表情识别任务(Wen et al., 2017)。
gcForest (Zhou & Feng, 2017)是一种将集成方法与DNNs相结合的新方法,与上述方法不同,它将神经元替换为随机森林模型,将每个随机森林的输出向量作为下一层的输入。当输入是高维的时候,它通过应用多粒度扫描来支持表示学习。
对比
(Dietterich, 2000) 比较了由C4.5决策树组成的randomizing、bagging和boost集合。实验表明,在数据噪声较小的情况下,boosting能获得最佳效果。
(Bauer & Kohavi)研究发现,bagging降低了不稳定方法的方差,而boosting方法降低了不稳定方法的偏差和方差,但增加了稳定方法的方差。
Banfield, Hall, Bowyer和Kegelmeyer(2007)用57个公开数据集进行了一项实验,将bagging与其他7种基于随机的技术进行比较。最好的方法仅在8个数据集中比bagging准确率高。有1000颗树的随机森林和boosting有着最好的平均排名。
集成学习简化模型
减少集成学习的规模可能看上去会降低集成学习的泛化能力,(Zhou, Wu, and Tang, 2002)证明了“many-could-be-better-than-all”,这使降低学习器规模而保持性能变得有道理。
通常有两类“剪枝”策略 Ranking 和 Search-based,排序法通过阈值选择靠前的基学习器;
Caruana, Niculescu-Mizil, Crew, Ksikes(2004)提出了一个向前逐步选择程序,以便从众多诱导因子中选择最相关的诱导因子(就预测性能而言)。
FS-PP-EROS (Hu, Yu, Xie, and Li, 2007)生成一个选择性的粗糙子空间集合。该方法进行了精确引导的前向搜索,寻找最相关的成员。实验结果表明,该方法在提供较小的集成的同时,优于bagging方法.
AB (Bryll et al., 2003)使用wrapper approach评估随机选择的top-N性能的学习器。
Margineantu and Dietterich (1997)提出基于kappa统计值的选择方法。
hang和Wang(2009)提出了一种具体的随机森林修剪方法,该方法使用了三种度量,将准确性和多样性考虑在内。
Dai(2013)提出了四种适合于时间序列域的基于排序的剪枝评价指标。
GASEN算法,在给定的集合中选择最合适的诱导器(Zhou et al., 2002)。首先,GASEN给每个模型分配一个随机权重。然后使用遗传算法对权重进行改进,从而表明模型在集成中的适合度,并去除权重较低的基础模型。
Prodromidis, Stolfo(2001)引入了一种基于后向相关的修剪类型,它根据基本模型的输出进行训练,并删除与元分类器相关性较低的成员。
森林修剪(FP;Jiang, Wu, & Guo, 2017)是最近开发的一种剪枝方法,它关注于一个决策树的集合,在这个集合中,树的分支是基于一个叫做分支重要性的新度量来剪枝的,该度量表示集合中单个分支和节点的重要性。
结论
集合法在做重要决定之前,通过征询不同意见来模仿人的本性。这些方法的主要思想是权衡几个单独的模型,并将它们结合起来,以提高预测性能。本文回顾了该领域的主要方法和技术,同时讨论了培训机构的核心原则。希望对你有所帮助。
Sagi, O, Rokach, L. Ensemble learning: A survey. WIREs Data Mining Knowl Discov. 2018; 8:e1249.
最新文章
- C#进阶系列——WebApi 跨域问题解决方案:CORS
- Caused by: java.sql.BatchUpdateException: Transaction error, need to rollback. errno:1205 Lock wait timeout exceeded; try restarting transaction
- pd name与comment互换,或者code互换,总之互换
- swift调用oc语言文件,第三方库文件或者自己创建的oc文件——简书作者
- 用NMAKE创建VS2012 C++工程 HelloWorld
- bzoj 3999: [TJOI2015]旅游
- Linux下jetty报java.lang.OutOfMemoryError: PermGen space及Jetty内存配置调优解决方案
- 传输控制协议(TCP) -- 连接建立及终止过程
- 学习jQuery必须知道的几种常用方法
- CUDA编程之快速入门
- KMP(字符串匹配)算法
- KVM虚拟化技术(二)KVM介绍
- 如何制作chm文件
- 05: MySQLdb 原生SQL语句操作数据库
- UVaLive 4597 Inspection (网络流,最小流)
- HDU2665_Kth number
- R302指识别开发笔记
- 【BZOJ4832】[Lydsy2017年4月月赛]抵制克苏恩 概率与期望
- IP流量重放与pcap文件格式解析
- Python学习进程(1)Python简介