RNN,LSTM,BERT
RNN
RNN 按照时间步展开
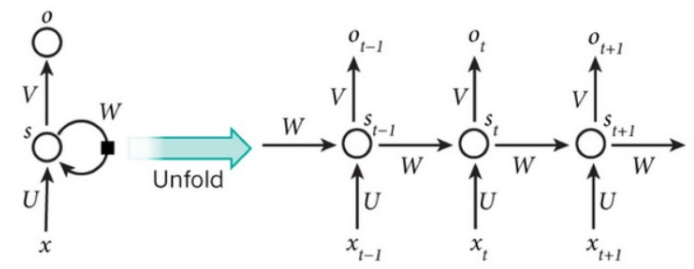
Bi-RNN
向前和向后的隐含层之间没有信息流。
LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失问题。
LSTM 对内部结构进行精心的设计,加入了输入门,遗忘门,输出门,和一个内部记忆单元\(c_t\)。输入门控制当前计算新状态以多大程度更新到记忆单元;遗忘门控制前一步记忆单元中的信息有多大程度被遗忘;输出门控制当前输出有多大程度上取决于当前的记忆单元。
和普通RNN相比,主要的输入输出区别如下
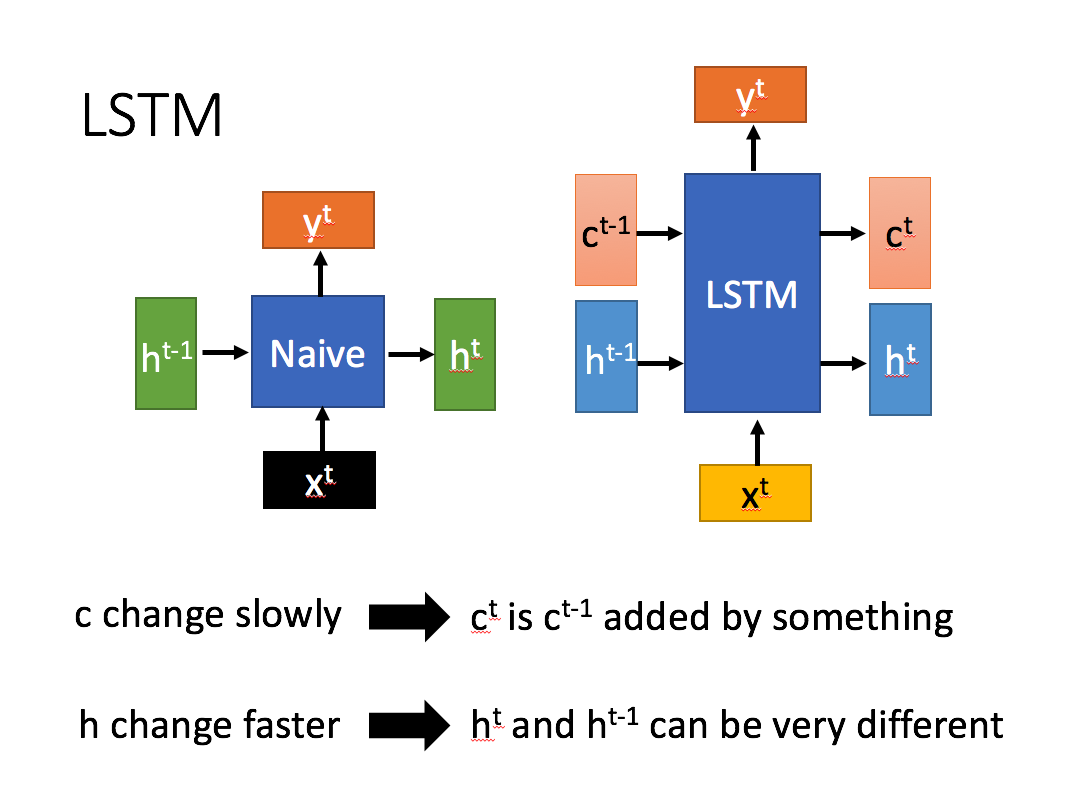
相比RNN只有一个传递状态\(h^t\),LSTM有两个传输状态,\(c^t\) (cell state)和 \(h^t\)(hidden state)。
计算公式
i_t = \sigma(W_i*[x_t, h_{t-1}]+b_i) \\
o_t = \sigma(W_o*[x_t, h_{t-1}]+b_o) \\
\tilde{C_t} = tanh(W_c*[h_t-1,x_t]+b_c) \\
C_t = f_t\odot C_{t-1}+i_t\odot \tilde{C_t} \\
h_t = o_t\odot tanh(C_t)
\]
参数量计算
\((hidden size * (hidden size + x_dim ) + hidden size) *4\)
self-attention
核心思想:用文本中的其他词来增强目标词的语义表示,从而更好地利用上下文信息。
计算步骤:
- 相似度计算
- softmax
- 加权平均
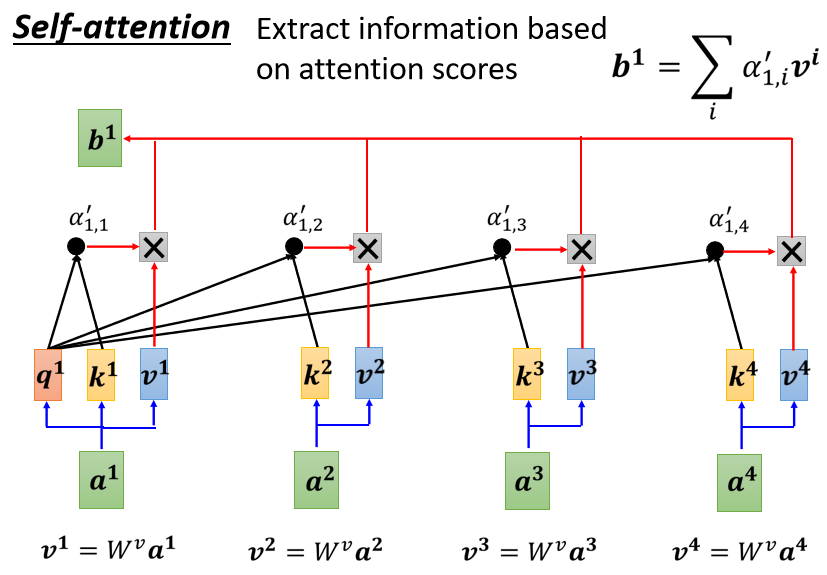
问题:常规的attention中,一般k=v, 那么self-attention中可以这样吗。
bert
推荐看原文哦: 超细节的BERT/Transformer知识点
史上最细节的自然语言处理NLP/Transformer/BERT/Attention面试问题与答案
上一个链接里问题的答案
论文
- Transformer: Attention Is All You Need
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
源码
问题
问题:为什么选择使用[cls]的输出代表整句话的语义表示?
或者说为什么不选择token1的输出
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。
为什么选它呢,
- 因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
- 从上面self-attention图片中可以看出把cls位置当做q,类似于站在全局的角度去观察整个句子文本。
问题:为什么是双线性点积模型(经过线性变换Q != K)?
- 双线性点积模型,引入非对称性,更具健壮性(Attention mask对角元素值不一定是最大的,也就是说当前位置对自身的注意力得分不一定最高)
展开解释:
- self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。
- 对于 self-attention,一般会说它的 q=k=v,这里的相等实际上是指它们来自同一个基础向量,而在实际计算时,它们是不一样的,因为这三者都是乘了QKV参数矩阵的。那如果不乘,每个词对应的q,k,v就是完全一样的。
- 在相同量级的情况下,\(q_i\) 与 \(k_i\) 点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。
- 那在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
- 而乘以QKV参数矩阵,会使得每个词的q,k,v都不一样,能很大程度上减轻上述的影响。
问题:self-attention的时间复杂度
- 时间复杂复杂度为:\(O(n^2d)\)
- 相似度计算可以看成矩阵(n×d)×(d×n),这一步的时间复杂度为O(n×d×n)
- softmax的时间复杂度O(n^2)
- 加权平均可以看成矩阵(n×n)×(n×d), 时间复杂度为O(n×n×d)
多头注意力机制的时间复杂度:
hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a- 并将 num_attention_heads 维度transpose到前面,使得Q和K的维度都是(m,n,a),这里不考虑batch维度。
- 这样点积可以看作大小为(m,n,a)和(m,a,n)的两个张量相乘,得到一个(m,n,n)的矩阵,其实就相当于(n,a)和(a,n)的两个矩阵相乘,做了m次,时间复杂度是\(O(n^2×a×m) = O(n^2d)\)
问题:BERT 怎么处理长文本?
问题:BERT 比ELMO 效果好的原因
从网络结构以及最后的实验效果来看,BERT 比 ELMo 效果好主要集中在以下几点原因:
- LSTM 抽取特征的能力远弱于 Transformer
- 拼接方式双向融合的特征融合能力偏弱(没有具体实验验证,只是推测)
- 其实还有一点,BERT 的训练数据以及模型参数均多余 ELMo,这也是比较重要的一点
知乎:transformer中multi-head attention中每个head为什么要进行降维?
link
简洁的说:在不增加时间复杂度的情况下,同时,借鉴CNN多核的思想,在更低的维度,在多个独立的特征空间,更容易学习到更丰富的特征信息。
问题:BERT中的mask
- 预训练的时候在句子编码的时候将部分词mask,这个主要作用是用被mask词前后的词来去猜测mask掉的词是什么,因为是人为mask掉的,所以计算机是知道mask词的正确值,所以也可以判断模型猜的词是否准确。
- Transformer模型的decoder层存在mask,这个mask的作用是在翻译预测的时候,如“我爱你”,翻译成“I love you”,模型在预测love的时候是不知道you的信息,所以需r要把后面“you”的信息mask掉。但是bert只有encoder层,所以这个算是transformer模型的特征。
- 每个attention模块都有一个可选择的mask操作,这个主要是输入的句子可能存在填0的操作,attention模块不需要把填0的无意义的信息算进来,所以使用mask操作。
问题:bert中进行ner为什么没有使用crf;使用DL进行序列标注问题的时候CRF是必备嘛(todo: in action)
进行序列标注时CRF是必须的吗?
如果你已经将问题本身确定为序列标注了,并且正确的标注结果是唯一的,那么用CRF理论上是有正的收益的,但如果主体是BERT等预训练模型,那么可能要调一下CRF层的学习率,参考CRF层的学习率可能不够大进行NER时必须转为序列标注吗?
就原始问题而言,不论是NER、词性标注还是阅读理解等,都不一定要转化为序列标注问题,既然不转化为序列标注问题,自然也就用不着CRF了。不转化为序列标注的做法也有很多,比如笔者提的GlobalPointer
问题:BERT的初始标准差为什么是0.02?
Retrieved from https://kexue.fm/archives/8747
cnn vs rnn vs self-attention
语义特征提取能力
- 目前实验支持如下结论:Transformer在这方便的能力非常显著超过RNN和CNN,RNN和CNN两者能力差不多。
长距离特征捕捉能力
实验支持如下结论:- 原生CNN特征抽取器在这方面显著弱于RNN和Transformer
- Transformer微弱优于RNN模型(距离小于13的时)
- 在比较远的距离上RNN微弱优于Transformer
任务综合特征抽取能力(机器翻译)
Transformer > 原生CNN == 原生RNN
并行计算能力及运行效率
Transformer和CNN差不多,都强于RNN
最新文章
- Redis ConnectionException
- zt:Linux查看程序端口占用情况
- js获取时间(本周、本季度、本月..)
- 无shell情况下的mysql远程mof提权利用方法详解
- 64bit Ubuntu, Android AAPT, R.java
- android string.xml里的空格字符
- Laravel Packages 开发
- ZOJ1100 状压DP +深搜
- Moocryption
- 【转】深入理解RunLoop
- java 基础知识六 字符串2
- Hibernate的使用
- java读写锁ReadWriteLock
- SpringMVC框架学习笔记(5)——数据处理
- Mybatis中文查询没有结果
- torch.nn.functional中softmax的作用及其参数说明
- CF698C - LRU
- PHP爬取历史天气
- Linux网络编程学习(五) ----- 信号(第四章)
- 使用JS监听键盘按下事件(keydown event)
热门文章
- VMware Workstation Pro 16、docker和Mysql相关
- 老毛桃WinPE以ISO镜像模式安装CentOS7
- 在ubuntu的docker中apt-get update更新失败:GPG error: https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu180,,,,,
- elasticsearch别名
- 狂神--Vue
- 【面试题】手写async await核心原理,再也不怕面试官问我async await原理
- apk文件查看指纹证书方法
- 那些年我们用过的xshell小彩蛋
- cenots7 rpm 包升级ssh
- Dapper、EF、WebAPI转载记录