Efficient training of physics-informed neural networks via importance sampling


因为看着作者是英伟达的,便看了一下。总体感觉没有什么新意,改进幅度也很小,但是理论推导可以看一下。可以借鉴一下。
本文通过重要性采样对PINN进行高效计算,本文提出的方法很简单,也很直观,但效果提升有限。大概说一下,就是利用一个与损失函数成比例的分布,进行采样,再利用这个子集更新网络参数。最后为了减少计算量,提出了一个分段常数近似(利用最近邻算法)。
一开始,作者提到,目前在PINN中,常使用的mini-SGD,其中由于小批量的选取服从均匀分布,所以会导致对解的收敛产生阻碍影响,因为,有可能很少或者几乎没有梯度信息被获取,这将会阻碍收敛。因此,作者认为通过重要性采样,选取一组合适的配置点可以加速收敛。目前,根据图像和文本领域的发现,如果在每次训练中,根据与损失的梯度的二范数成比例的建议分布进行采样,可以将训练收敛速度最大化。但是,这样直接计算这样的建议分布是计算昂贵的,因此该作者使用了与损失函数本身成比例的近似建议分布来提高计算效率。这在图像分类和语言建模中已经验证了。最后,为了减少计算量,提出分段常数近似(PWC)。由于所提出方法十分简单,所以可以直接应用到目前的PINN模型中。
有一个逐步的推导:
这是目前的优化目标函数,最小化所有配置点的损失
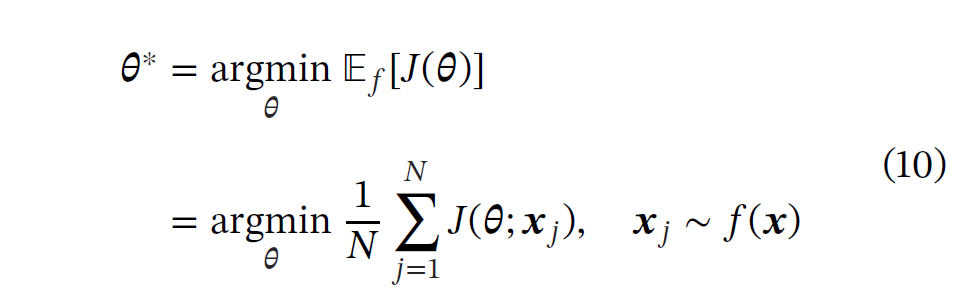
作者希望将其改进成下式,因为有理论证明,下式可以假如收敛。f是均匀采样,q是我们所需要的找的采样分布。在这里我们只考虑离散分布。
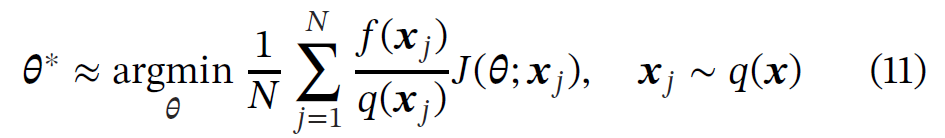
根据理论,这个分布可以找到,并且这个分布于损失函数梯度的二范数相关(某点的损失与所有点的损失之和的比值,考虑离散分布)。
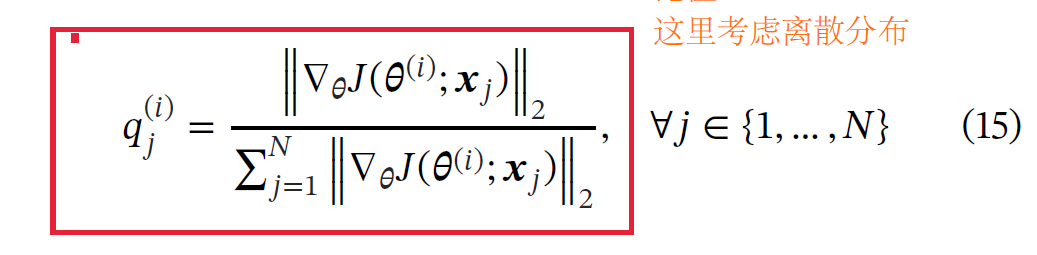
然后,训练时,我们利用q,从N个配置点中,选取m个,作为重要性的代表,用来更新网络。作者认为这样比均匀采样更具代表性,更有利于PINN的收敛。
最后我们的更新方法为下式(η应该为学习率):
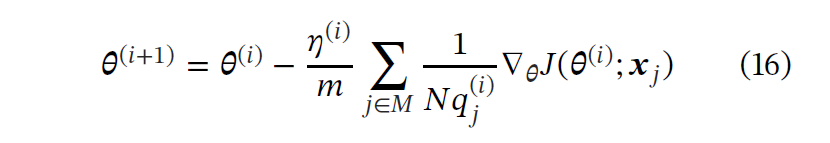
理论证明(上面的推导),可以通过重要性采样加速PINN的训练,其中训练样本是从与损失函数相对于模型参数的梯度的2范数成比例的分布中获得的。但是,直接计算这个分布是昂贵。再次根据理论(Katharopoulos and Fleuret),我们可以使用损失值而不是梯度来作为重要性指标。我们最后获得的分布是:
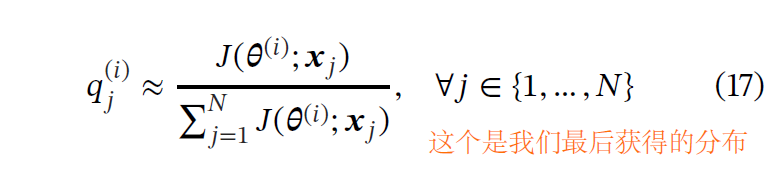
不过,每次迭代中对计算这种分布也是昂贵的,因此作者提出了一个分段常数近似对于损失函数。即,只在点子集上评估,然后使用最近邻搜索,对于每一个配置点j,确定最近的种子s,并且将配置点j的损失值设定成种子s处的损失值。下图为一个示意图,其中橙色为种子s。

伪代码如下:

实验部分,作者做了很多消融实验。但具体的性能提升是有限的。也没有与其他PINN的变体相比。
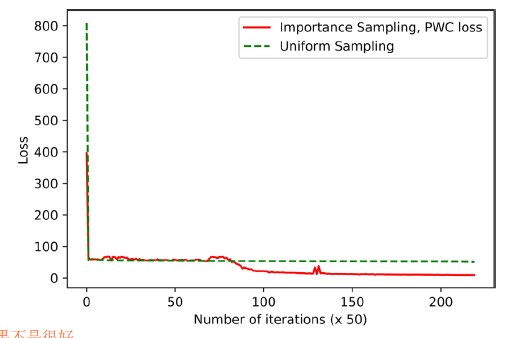
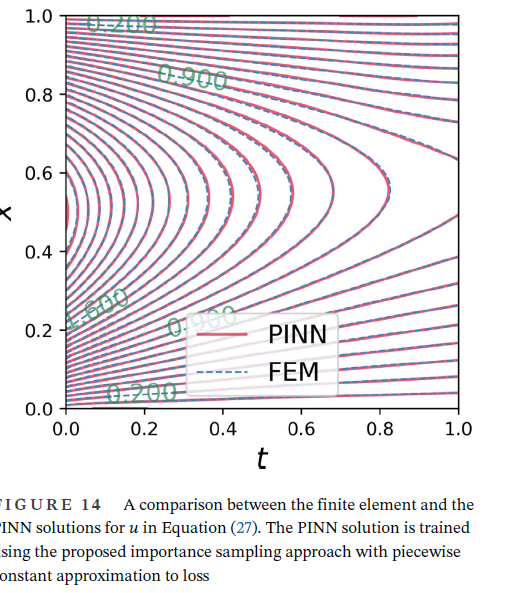
这篇论文虽然简单,还很一般,但是我还是有收获的。最大的一点就是,本文有少量的理论推导,以前我是读不动的,这次读起来感觉还可以。因此以后可以逐渐的进步了。
最新文章
- BitHacks
- .net使用pdfobject.js加载pdf文件
- 日常维护sql
- ASP.NET后台获取cookie中文乱码解决办法
- 无任何网络提供程序接受指定的网络路径(系统服务里没有workstation服务)
- OD常用断点
- 【原创】alias与export
- Codeforces 17D Notepad 简单的数论
- MYsql数据库ERROR总结
- bootstrap_下拉菜单+头部
- 《principles of model checking》中的离散时间马尔科夫链
- cannot open file "cxcore.lib"
- coursea机器学习课程作业
- python利用xlrd读取excel文件始终报错原因
- SAP abap 内表增加字段方法,结构复用
- Spark连接MongoDB之Scala
- c输出格式
- BZOJ5323:[JXOI2018]游戏
- 转:eclipse的快捷键
- Mac OS 装gdb