pandas数据结构:Series/DataFrame;python函数:range/arange
1. Series
Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index)。
1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会使用默认索引(从0到N-1)。

# 引入Series和DataFrame
In [16]: from pandas import Series,DataFrame
In [17]: import pandas as pd In [18]: ser1 = Series([1,2,3,4]) In [19]: ser1
Out[19]:
0 1
1 2
2 3
3 4
dtype: int64
1.2 当要生成一个指定索引的Series 时候,可以这样:
# 给index指定一个list
In [23]: ser2 = Series(range(4),index = ["a","b","c","d"]) In [24]: ser2
Out[24]:
a 0
b 1
c 2
d 3
dtype: int64
1.3 也可以通过字典来创建Series对象
In [45]: sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
In [46]: ser3 = Series(sdata)
# 可以发现,用字典创建的Series是按index有序的
In [47]: ser3
Out[47]:
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
在用字典生成Series的时候,也可以指定索引,当索引中值对应的字典中的值不存在的时候,则此索引的值标记为Missing,NA,并且可以通过函数(pandas.isnull,pandas.notnull)来确定哪些索引对应的值是没有的。
In [48]: states = ['California', 'Ohio', 'Oregon', 'Texas'] In [49]: ser3 = Series(sdata,index = states) In [50]: ser3
Out[50]:
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
# 判断哪些值为空
In [51]: pd.isnull(ser3)
Out[51]:
California True
Ohio False
Oregon False
Texas False
dtype: bool In [52]: pd.notnull(ser3)
Out[52]:
California False
Ohio True
Oregon True
Texas True
dtype: bool
1.4 访问Series中的元素和索引:
# 访问索引为"a"的元素
In [25]: ser2["a"]
Out[25]: 0
# 访问索引为"a","c"的元素
In [26]: ser2[["a","c"]]
Out[26]:
a 0
c 2
dtype: int64
# 获取所有的值
In [27]: ser2.values
Out[27]: array([0, 1, 2, 3])
# 获取所有的索引
In [28]: ser2.index
Out[28]: Index([u'a', u'b', u'c', u'd'], dtype='object')
1.5 简单运算
在pandas的Series中,会保留NumPy的数组操作(用布尔数组过滤数据,标量乘法,以及使用数学函数),并同时保持引用的使用
In [34]: ser2[ser2 > 2]
Out[34]:
a 64
d 3
dtype: int64 In [35]: ser2 * 2
Out[35]:
a 128
b 2
c 4
d 6
dtype: int64 In [36]: np.exp(ser2)
Out[36]:
a 6.235149e+27
b 2.718282e+00
c 7.389056e+00
d 2.008554e+01
dtype: float64
1.6 Series的自动对齐
Series的一个重要功能就是自动对齐(不明觉厉),看看例子就明白了。 差不多就是不同Series对象运算的时候根据其索引进行匹配计算。
# ser3 的内容
In [60]: ser3
Out[60]:
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
# ser4 的内容
In [61]: ser4
Out[61]:
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
# 相同索引值的元素相加
In [62]: ser3 + ser4
Out[62]:
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
1.7 命名
Series对象本身,以及索引都有一个 name 属性
In [64]: ser4.index.name = "state" In [65]: ser4.name = "population" In [66]: ser4
Out[66]:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
转自:http://www.cnblogs.com/linux-wangkun/p/5903380.html
DataFrame
用pandas中的DataFrame时选取行或列:
import numpy as np
import pandas as pd
from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是Series类型 data.w #选择表格中的'w'列,使用点属性,返回的是Series类型 data[['w']] #选择表格中的'w'列,返回的是DataFrame类型 data[['w','z']] #选择表格中的'w'、'z'列 data[0:2] #返回第1行到第2行的所有行,前闭后开,包括前不包括后 data[1:2] #返回第2行,从0计,返回的是单行,通过有前后值的索引形式,
#如果采用data[1]则报错 data.ix[1:2] #返回第2行的第三种方法,返回的是DataFrame,跟data[1:2]同 data['a':'b'] #利用index值进行切片,返回的是**前闭后闭**的DataFrame,
#即末端是包含的 #——————新版本pandas已舍弃该方法,用iloc代替———————
data.irow(0) #取data的第一行
data.icol(0) #取data的第一列 ser.iget_value(0) #选取ser序列中的第一个
ser.iget_value(-1) #选取ser序列中的最后一个,这种轴索引包含索引器的series不能采用ser[-1]去获取最后一个,这会引起歧义。
#————————————————————————————----------------- data.head() #返回data的前几行数据,默认为前五行,需要前十行则data.head(10)
data.tail() #返回data的后几行数据,默认为后五行,需要后十行则data.tail(10) data.iloc[-1] #选取DataFrame最后一行,返回的是Series
data.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame data.loc['a',['w','x']] #返回‘a’行'w'、'x'列,这种用于选取行索引列索引已知 data.iat[1,1] #选取第二行第二列,用于已知行、列位置的选取。
转自:https://blog.csdn.net/xiaodongxiexie/article/details/53108959
DataFrame的排序
原来的方法sort/sort_index都已经过时,调用时会报错:
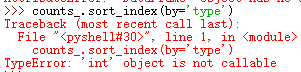
sort方法就直接找不到。
应该调用sort_values方法来进行排序:

Python 中的range,以及numpy包中的arange函数
range()函数
- 函数说明: range(start, stop[, step]) -> range object,根据start与stop指定的范围以及step设定的步长,生成一个序列。
参数含义:start:计数从start开始。默认是从0开始。例如range(5)等价于range(0, 5);
end:技术到end结束,但不包括end.例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
scan:每次跳跃的间距,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
函数返回的是一个range object
例子:
>>> range(0,5) #生成一个range object,而不是[0,1,2,3,4]
range(0, 5)
>>> c = [i for i in range(0,5)] #从0 开始到4,不包括5,默认的间隔为1
>>> c
[0, 1, 2, 3, 4]
>>> c = [i for i in range(0,5,2)] #间隔设为2
>>> c
[0, 2, 4]
若需要生成[ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
>>> range(0,1,0.1) #range中的setp 不能使float
Traceback (most recent call last):
File ”<pyshell#5>”, line 1, in <module>
range(0,1,0.1)
TypeError: ’float’ object cannot be interpreted as an integer
arrange()函数
- 函数说明:arange([start,] stop[, step,], dtype=None)根据start与stop指定的范围以及step设定的步长,生成一个 ndarray。 dtype : dtype
The type of the output array. If `dtype` is not given, infer the data
type from the other input arguments.
>>> np.arange(3)
array([0, 1, 2])
>>> np.arange(3.0)
array([ 0., 1., 2.])
>>> np.arange(3,7)
array([3, 4, 5, 6])
>>> np.arange(3,7,2)
array([3, 5]) >>> arange(0,1,0.1)
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
转自:http://blog.csdn.net/qianwenhong/article/details/41414809
Python 中的range,以及numpy包中的arange函数
range()函数
- 函数说明: range(start, stop[, step]) -> range object,根据start与stop指定的范围以及step设定的步长,生成一个序列。
参数含义:start:计数从start开始。默认是从0开始。例如range(5)等价于range(0, 5);
end:技术到end结束,但不包括end.例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
scan:每次跳跃的间距,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
函数返回的是一个range object
例子: - >>> range(0,5) #生成一个range object,而不是[0,1,2,3,4]
- range(0, 5)
- >>> c = [i for i in range(0,5)] #从0 开始到4,不包括5,默认的间隔为1
- >>> c
- [0, 1, 2, 3, 4]
- >>> c = [i for i in range(0,5,2)] #间隔设为2
- >>> c
- [0, 2, 4]
>>> range(0,5) #生成一个range object,而不是[0,1,2,3,4]
range(0, 5)
>>> c = [i for i in range(0,5)] #从0 开始到4,不包括5,默认的间隔为1
>>> c
[0, 1, 2, 3, 4]
>>> c = [i for i in range(0,5,2)] #间隔设为2
>>> c
[0, 2, 4]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 若需要生成[ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
- >>> range(0,1,0.1) #range中的setp 不能使float
- Traceback (most recent call last):
- File ”<pyshell#5>”, line 1, in <module>
- range(0,1,0.1)
- TypeError: ’float’ object cannot be interpreted as an integer
>>> range(0,1,0.1) #range中的setp 不能使float
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
range(0,1,0.1)
TypeError: 'float' object cannot be interpreted as an integer- 1
- 2
- 3
- 4
- 5
arrange()函数
- 函数说明:arange([start,] stop[, step,], dtype=None)根据start与stop指定的范围以及step设定的步长,生成一个 ndarray。 dtype : dtype
The type of the output array. If `dtype` is not given, infer the data
type from the other input arguments.- >>> np.arange(3)
- array([0, 1, 2])
- >>> np.arange(3.0)
- array([ 0., 1., 2.])
- >>> np.arange(3,7)
- array([3, 4, 5, 6])
- >>> np.arange(3,7,2)
- array([3, 5])
>>> np.arange(3)
array([0, 1, 2])
>>> np.arange(3.0)
array([ 0., 1., 2.])
>>> np.arange(3,7)
array([3, 4, 5, 6])
>>> np.arange(3,7,2)
array([3, 5])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- >>> arange(0,1,0.1)
- array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
>>> arange(0,1,0.1)
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
最新文章
- IOS第二天多线程-03对列组合并图片
- 【转】SVN管理多个项目版本库
- Android开发探秘之一:创建可以点击的Button
- 关于用Max导出Unity3D使用的FBX文件流程注解
- jquery实现跨域提交(原创)
- css规范大全
- xcode import<xx/xx.h> 头文件报错
- 笔记——ES5 Array
- Windows下bmp文件格式
- 【原创】史上最全的Android开发环境搭建
- ICP编程软件配置(烧写KEIL编译后的bin文件)
- java-创建线程的两种方式
- js的处理技巧
- Android View事件机制一些事
- ES6常用
- 这款APP太像微信 腾讯起诉索赔1000万
- 算法提高 P0101
- Mybatis学习3——动态代理
- kbmmw 5.05.00 发布
- 05: python中的函数