python selenium-4自动化测试模型
2024-09-08 15:42:03
1.线性测试
特点:每一个脚本都是完整且独立的,可以单独执行。
缺点:用例的开发与维护成本很高

2.模块化驱动测试
特点:把重复的操作独立成公共模块,提高测试用例的可维护性
示例:将搜索封装到func中,其他文件直接导入使用即可
func.py
class Func():
def search(self,driver):
driver.find_element_by_xpath("//input[@id='kw' and @class='s_ipt']").send_keys("hello")
driver.find_element_by_xpath("//input[@value='百度一下' and @id='su']").click()
result_text = driver.find_element_by_xpath("//span[@class='nums_text']").text
assert "百度为您找到相关结果约" in result_text
action.py
import sys
from selenium import webdriver;
from time import sleep
from testcase import func
path = sys.path[0].replace("testcase", "") + "driver/geckodriver"
driver = webdriver.Firefox(executable_path=path)
driver.implicitly_wait(5)
driver.get("http://www.baidu.com")
print("打开百度")
func.Func().search(driver)
#等同于
#s=func.Func()
#s.search(driver)
sleep(3)
driver.quit()
print("退出")
3.数据驱动测试
3.1参数化搜索关键字
func.py
from time import sleep
class Func():
def search(self,driver,word):
driver.find_element_by_xpath("//input[@id='kw' and @class='s_ipt']").clear()
driver.find_element_by_xpath("//input[@id='kw' and @class='s_ipt']").send_keys(word)
driver.find_element_by_xpath("//input[@value='百度一下' and @id='su']").click()
result_text = driver.find_element_by_xpath("//span[@class='nums_text']").text
assert "百度为您找到相关结果约" in result_text
sleep(1)
action.py
import sys
from selenium import webdriver;
from testcase import func
path = sys.path[0].replace("testcase", "") + "driver/geckodriver"
driver = webdriver.Firefox(executable_path=path)
driver.implicitly_wait(5)
driver.get("http://www.baidu.com")
print("打开百度")
func.Func().search(driver,"hello")
func.Func().search(driver,"world")
driver.quit()
print("退出")
3.2读取txt文件
read():读取整个文件
readline():读取一行数据
readlins():读取所有行的数据
word.txt
java,廖雪峰
pyhton,菜鸟
selenium,阮一峰
action.py
import sys
from selenium import webdriver;
from testcase import func
path = sys.path[0].replace("testcase", "") + "driver/geckodriver"
driver = webdriver.Firefox(executable_path=path)
driver.implicitly_wait(5)
driver.get("http://www.baidu.com")
print("打开百度")
file = open("word.txt","r")
lines = file.readlines()
file.close()
for i in lines:
searchWord = i.split(',')[0]
func.Func().search(driver,searchWord)
driver.quit()
print("退出")
3.3读取csv文件
word.csv
#读取csv文件
import csv
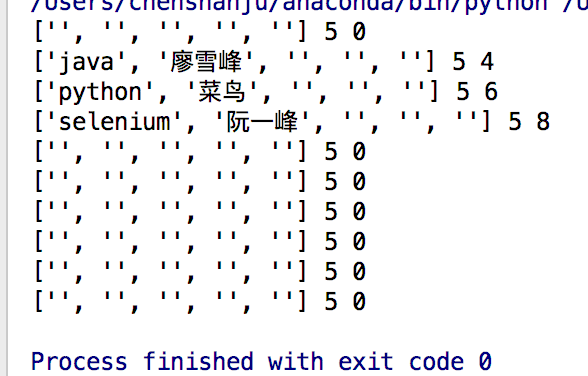
data = csv.reader(open("word.csv","r"))
for user in data:
print(user,len(user),len(user[0]))
aciton.py
```#python
import csv
import sys
from selenium import webdriver;
from testcase import func
path = sys.path[0].replace("testcase", "") + "driver/geckodriver"
driver = webdriver.Firefox(executable_path=path)
driver.implicitly_wait(5)
driver.get("http://www.baidu.com")
print("打开百度")
data = csv.reader(open("word.csv",'r'))
for row in data:
if len(row[0])==0:
pass
else:
func.Func().search(driver,row[0])
func.Func().search(driver,row[1])
driver.quit()
print("退出")
## 3.4读取Excel文件
<img src="https://img2018.cnblogs.com/blog/1418970/201811/1418970-20181120151340811-1621898753.png" width="400" />
```#python
import xlrd
#打开表格
file = xlrd.open_workbook("word.xlsx")
#获取所有sheet,sheet_names()表名
print(file.sheet_names())
#根据sheet索引或名称获取shell内容
sheet1=file.sheet_by_index(0)
sheet2=file.sheet_by_name("工作表 1 - word")
#获取sheet表格的行数和列数
sheet2_row= sheet2.nrows
sheet2_col= sheet2.ncols
print(sheet2.name,sheet2_row,sheet2_col)
#获取每一行的数据
for i in range(sheet2_row):
print("",sheet2.row_values(i))
#获取每一列的数据
for i in range(sheet2_col):
print(sheet2.col_values(i))
# #获取单元格的数据
print(sheet2.cell(2,1).value,sheet2.cell(2,0).value)
#循环打印非空值
for i in range(sheet2_row):
for j in range(sheet2_col):
if len(sheet2.cell(i,j).value) != 0:
print(sheet2.cell(i,j).value)
import xlrd
import sys
from selenium import webdriver;
from testcase import func
path = sys.path[0].replace("testcase", "") + "driver/geckodriver"
driver = webdriver.Firefox(executable_path=path)
driver.implicitly_wait(5)
driver.get("http://www.baidu.com")
print("打开百度")
data = xlrd.open_workbook("word.xlsx")
sheet2_data=data.sheet_by_index(1)
sheet2_rows=sheet2_data.nrows
sheet2_col=sheet2_data.ncols
for i in range(sheet2_rows):
for j in range(sheet2_col):
if i > 0:
text=sheet2_data.cell(i,j).value
if len(text) > 0:
func.Func().search(driver,text)
driver.quit()
print("退出")
3.5读取xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!--注意:第一行如果直接键入会报错。输入<?xml,然后直接使用tab键生成第一行,删除多余内容即可-->
<info>
<base>
<platform>Windows</platform>
<browser>Firefox</browser>
<url>http://www.baidu.com</url>
<login username="admin" password="123456" />
<login username="guest" password="654321" />
</base>
<test>
<province>北京</province>
<province>广东</province>
<city>深圳</city>
<city>珠海</city>
<province>浙江</province>
<city>杭州</city>
</test>
</info>
http://www.w3school.com.cn/xmldom/dom_nodes.asp
from xml.dom import minidom
dom = minidom.parse('info.xml')
root = dom.documentElement
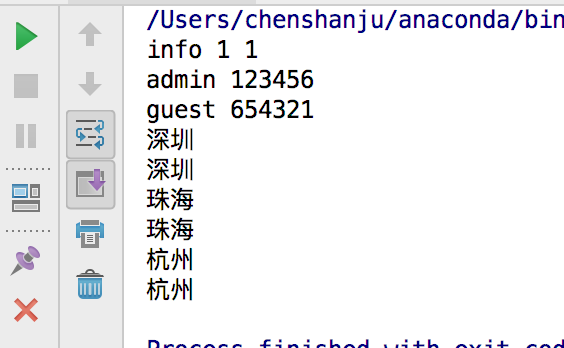
print(root.nodeName,root.nodeType,root.ELEMENT_NODE)
pros = dom.getElementsByTagName("login")
for pro in pros:
print(pro.getAttribute("username"),pro.getAttribute("password"))
pros = dom.getElementsByTagName("city")
for pro in pros:
print(pro.childNodes[0].data)
#等价于
print(pro.firstChild.data)
4.关键字驱动测试
最新文章
- [译] 企业级 OpenStack 的六大需求(第 2 部分):开放架构和混合云兼容
- UVA 1349(二分图匹配)
- httpd的警告
- a链接中关于this的使用
- 关于tableView的那些坑(一)—— automaticallyAdjustsScrollViewInsets属性
- BZOJ2768: [JLOI2010]冠军调查
- 分享一个用安卓手机就能引导pc安装linux系统办法
- 使用jsp标签和java资源管理实现jsp支持多语言
- jQuery中delegate与on的用法与区别
- struts2标签库使用小结
- [bzoj4161]Shlw loves matrix I
- Vue之v-for、v-show使用举例
- JavaScript下实现交换数组元素上下移动例子
- 在java服务端判断请求是来自哪个终端
- android 中文api
- 文件上传 accept 兼容性
- C#数据库连接方法
- 使用 python 将 "\r\n" 转换为 "\n"
- SQL Server会话KILL不掉,一直处于KILLED /ROLLBACK状态情形浅析[转]
- JS里的居民们5-数组(栈)