深度学习(十五) TextCNN理解
2024-08-28 18:34:31
以下是阅读TextCNN后的理解
步骤:
1.先对句子进行分词,一般使用“jieba”库进行分词。
2.在原文中,用了6个卷积核对原词向量矩阵进行卷积。
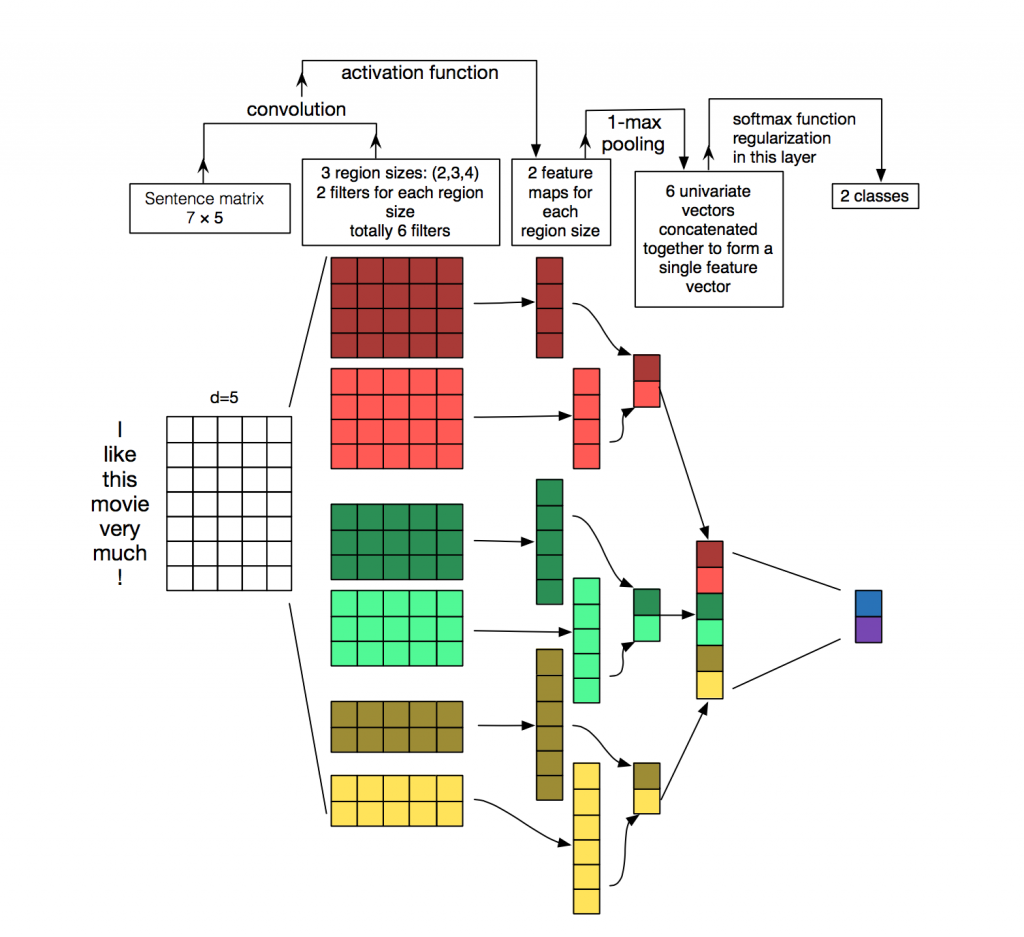
3.6个卷积核大小:2个4*6、2个3*6和2个2*6,如上图所示;然后进行池化,对相同卷积核产生的特征图进行连接;再进行softmax输出2个类别。
1).这里对no-static进行阐述,表示在训练的过程中,词向量是可以进行微调的,也叫做fine-tuning。
4.为什么采用不同大小的卷积核,不同的感受视野,卷积核的宽取词汇表的纬度,有利于语义的提取。
5.研究证明为什么要采用字,而不采用字,原因是词粒度准确率>字粒度准确率。存在两种模型,一种是词袋模型,第二种是词向量模型。下面对词向量模型来进行讲述。
词向量模型:
一般开始为高纬度,高稀疏向量,利用嵌入层对其进行降维,增加稠密性。
使用词向量进行文本分类的步骤为:
①.先使用分词工具提取词汇表。
②.将要分类的内容转换为词向量。
a.分词
b.将每个词转换为word2vec向量。
c.按顺序组合word2vec,那么就组合成了一个词向量。
d.卷积、池化和连接,然后进行分类。
6.嵌入层
原来一句话被分成了许多词,因为在训练好的词向量中,是用语料库中所有的词拿来进行训练的,所以训练好的word2vec是一个字典,键值是词,value值就是该词词向量的值,嵌入层的作用就是将一句话中词拿到训练好的词向量字典中去组合词向量,组合好的词向量就是这句话的向量。
最新文章
- jvm的内存分配总结
- Windows下配置nginx+php(wnmp)
- 关于原生的Javascript
- Js作用域与作用域链详解
- 基础2 JVM
- ios基础篇(五)——UITextField的详细使用
- ArrayAdapter的简单使用
- 02.Hibernate映射基础
- C#反编译工具 ILSPY-x64可动态调试-君临汉化版
- 解决IE6下不支持 png24的透明图片问题
- ubuntu ssh-keygen Permission denied
- 修改apache默认主页,重定向404页面
- XMLTABLE
- Linux内存管理 (11)page引用计数
- HTML协议
- 【BZOJ3730】震波(动态点分治)[复习]
- jsp 进度条
- MySQL5.7 Group Replication (MGR)--Mysql的组复制之多主模式
- 创建Web API并使用
- 解决openwrt中文界面异常