集成算法——Ensemble learning
目的:让机器学习效果更好,单个不行,群殴啊!
Bagging:训练多个分类器取平均
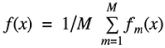
Boosting:从弱学习器开始加强,通过加权来进行训练

(加入一棵树,比原来要强)
Stacking:聚合多个分类或回归模型(可以分阶段来做)
bagging模型
全称:bootstrap aggregation(说白了就是并行训练一堆分类器)
最典型代表:随机森林
随机:数据采样随机,特征选择随机
森林:很多个决策树并行放在一起
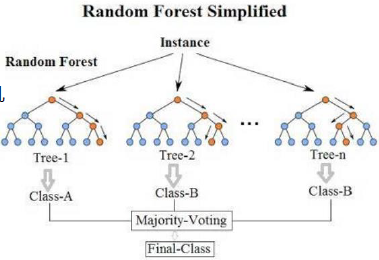
构造树模型
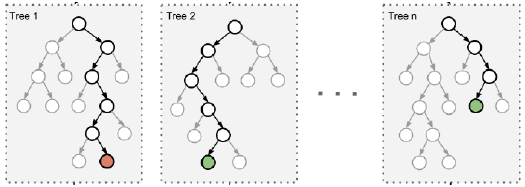
由于二重随机性,使得每个树基本上都不会一样,最终的结果也会不一样。
树模型:
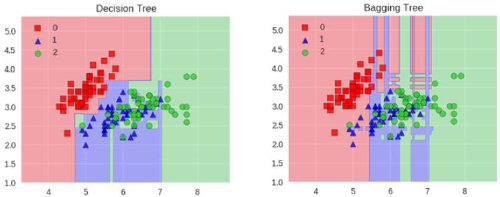
之所以要进行随机,是要保证泛化能力,如果树都一样,就没有意义了。
随机森林优势
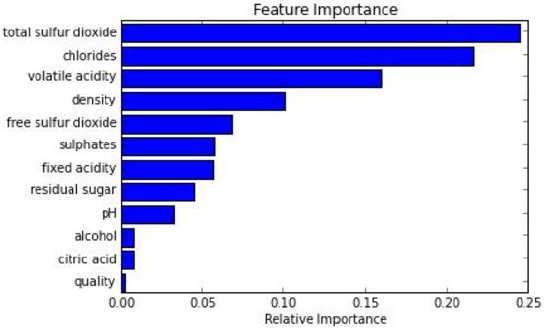
能够处理很高维度(feature很多)的数据,并且不用做特征选择
在训练完后,它能够给出哪些feature比较重要
容易做成并行化方法,速度比较快
可以进行可视化展示,便于分析
KNN模型
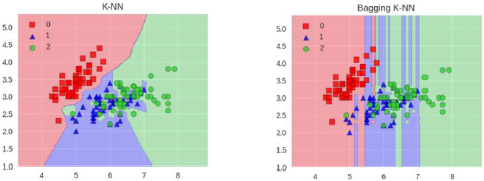
KNN就不太适合,因为很难去随机让泛化能力变强!
树模型
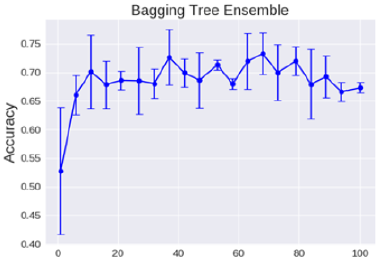
理论上越多的树效果会越好,但实际上基本超过一定数量就差不多上下浮动了。
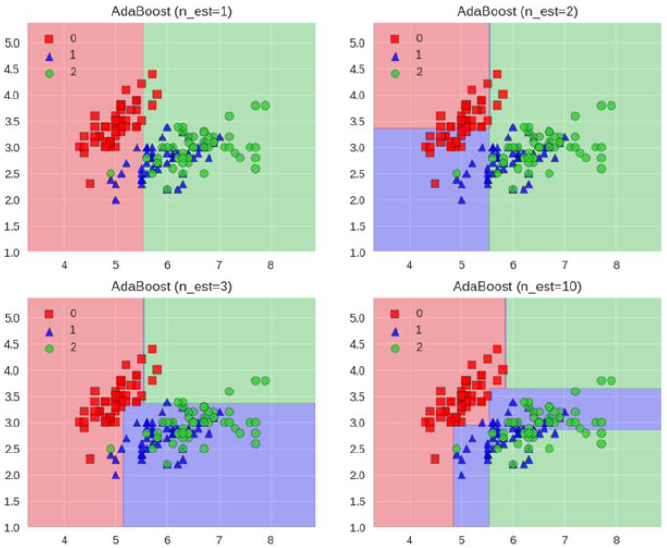
Boosting模型
典型代表:AdaBoost,Xgboost
Adaboost会根据前一次的分类效果调整数据权重
如果某一个数据在这次分错了,那么在下一次就会给它更大的权重
最终结果:每个分类器根据自身的准确性来确定各自的权重,再合体
Adaboost工作流程
每一次切一刀
最终合在一起
弱分类器就升级了
Stacking模型
堆叠:很暴力,拿来一堆直接上(各种分类器都来了)
可以堆叠各种各样的分类器(KNN,SVM,RF等等)
分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
为了刷结果,不择手段!
堆叠在一起确实能使得准确率提升,但是速度是个问题
集成算法是竞赛与论文神器,当我们更关注与结果时不妨试试!
最新文章
- Oracle 数据库1046事件
- vue-cli#2.0 webpack 配置分析
- struts2中的ognl详解,摘抄
- ubuntu下使用apt-get install安装的软件在哪个目录
- 21.altera fpga 芯片中 pin 和 pad 区别
- Rsync文件同步
- [SQL Server系] -- 视图
- PHP开发安全之近墨者浅谈(转)
- JQuery EasyUI combobox动态添加option
- DLL注入_拦截技术之Hook方式
- hadoop每个家庭成员
- 揭开Html 标签的面纱,忘不了的html .
- 批处理数据--db2备份数据
- NAVICAT 拒绝链接的问题
- 时间处理之strtotime
- Equipment UVA - 1508(子集补集)
- 总zabbix配置-搭建-邮件报警-微信报警-监控mysql
- 使用xargs与awk联合使用批量杀进程,很方便
- docker 数据管理数据卷
- Android-Activity启动模式-应用场景