Hadoop3.2.0+Centos7三节点完全分布式安装配置
2024-08-27 20:12:26
一、环境准备
①准备三台虚拟机,配置静态IP
②先修改主机名(每个节点统一命名规范)
vim /etc/hostname
master #重启生效
配置DNS每个节点
vim /etc/hosts
192.168.60.121 master
192.168.60.122 salve1
192.168.60.123 salve2
永久关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
配置免密登录
ssh-keygen -t rsa #一路回车即可
cd 到 .ssh
cp id_rsa.pub authorized_keys #生成公钥
将公钥拷贝到节点
scp authorized_keys root@slave1:/root/.ssh/
scp authorized_keys root@slave2:/root/.ssh/
登录到hadoop2主机cd到.ssh
cat id_isa.pub >> authorized_keys #使用cat追加方式
登录到2号主机重复操作,再将公钥拷贝到三台主机上
二、配置jdk1.8
将jdk解压到自定义目录
vim /etc/profile #添加如下信息
export JAVA_HOME=jdk安装目录
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:JAVA_HOME/bin
再保存执行
#source /etc/profile
验证
#java -version
三、Hadoop环境配置
解压并移动到自定义位置
vim /etc/profile
export HADOOP_HOME=Hadoop的安装目录
export PATH=$PAHT:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/Hadoop
更新资源使生效
source /etc/profile
首先在hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中指定JDK的路径
export JAVA_HOME=jdk安装目录
配置core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property><!--namenode持久存储名字空间及事务日志的本地文件系统路径-->
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property><!--DataNode存放块数据的本地文件系统路径-->
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property><!--数据需要备份的数量,不能大于集群的机器数量,默认为3-->
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property><!--namenode持久存储名字空间及事务日志的本地文件系统路径-->
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property><!--DataNode存放块数据的本地文件系统路径-->
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property><!--数据需要备份的数量,不能大于集群的机器数量,默认为3-->
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<property><!--NodeManager上运行的附属服务,用于运行mapreduce-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property><!--ResourceManager 对外web暴露的地址,可在浏览器查看-->
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
<property><!--NodeManager上运行的附属服务,用于运行mapreduce-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property><!--ResourceManager 对外web暴露的地址,可在浏览器查看-->
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改workers文件,删除localhost,并换成
slave1
slave2
修改文件
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh
两处增加以下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
处理2
$ vim sbin/start-yarn.sh
$ vim sbin/stop-yarn.sh
两处增加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
复制Hadoop文件到节点
scp -r /目的目录 hadoop2:./目的目录

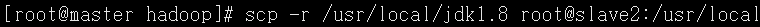
Hadoop安装完成,格式化Namenode
cd到bin目录./Hdfs namenode -format

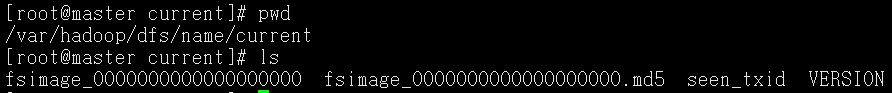
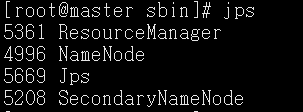
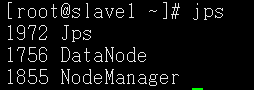
启动Hadoop
cd到sbin下 ./start-all.sh
OVER。。。
最新文章
- SQLSERVER2012 Audit (审核)功能
- 清北学堂模拟day6 兔子
- [Python] Search navigation in Pycharm
- [原创]java WEB学习笔记54:Struts2学习之路---概述,环境的搭建
- 项目中Enum枚举的使用
- 1.关于UltraEdit中的FTP和Tenent配置,UE远程连接Linux进行文件操作
- Android Studio 初体验
- 深入浅出Node.js (3) - 异步I/O
- Bootstrap 网格系统
- bug 对应
- SQLServer之创建事务序列化
- python高级-动态特性(20)
- Dynamics 365测试和启用邮箱时候一直显示“安排电子邮件配置测试”怎么办?
- 此主机支持Intel VT-x,但Intel VT-x处于禁用状态
- matplotlib 入门之Image tutorial
- CSS 图像居中对齐
- loadrunner 场景设计-制定负载测试计划
- win10系统如何关掉系统自动更新
- 绕过cookies进行登录并封装请求方法
- C++:引用的简单理解