数据可视化之powerBI技巧(八)Power BI按多列排序的技巧
目前PowerBI的表格已经支持多列排序,但是矩阵依然还不支持按多个字段排序,虽然这个需求很普遍,这里利用DAX提供一个变通的实现方式。
模拟数据如下,有两个数据指标:
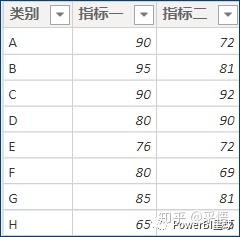
对类别首先按[指标一]进行排序,如果[指标一]数据相同,则按[指标二]排序。
因为PowerBI目前只能按一列排序,自然会想到构造个辅助列来实现,比如这样来添加辅助列:
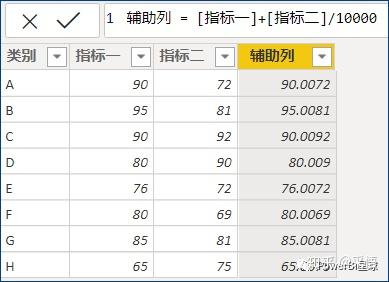
原理就是在主排序列上加上一个特别小的数,这个特别小的数是由次排序列生成,两个数据加到一起,就生成了一个由两个指标混合而成,并且不会损坏原数据大小顺序的列,然后按这个辅助列计算排名就可以了。
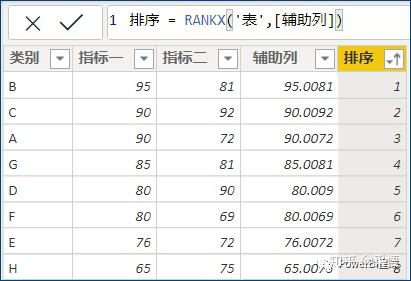
这个排序就是按照指标一和指标二作为主次排序字段生成。
该方法的关键就是确定如何生成这个辅助列,因为上面的数据一目了然,随便用[指标二]除以一个很大的数,就可以生成一个不改变指标二顺序的序列,并且加上这个序列以后,不会影响到[指标一]的总体顺序。
但是如果数据量很大,并且数据大小跨度也很大,你就不能轻易的决定是除以10000、还是除以1000000更合适,必须先清楚的了解排序指标的数据结构,才能保证排序正确。
这里给出一个更加普适的方式来构造这个辅助列,无需考虑排序列的绝对数据大小,而改用相对大小,用它们自身的排名来构造,如下图:
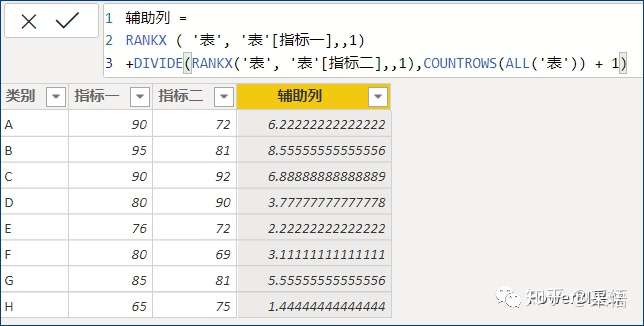
也就是[指标一]的升序排名,加上,[指标二]的升序排名除以(行数+1),原理是类似的,然后按这个辅助列排序就可以了。
当然,也可以不加物理辅助列,而把这个逻辑放到公式内部,一次性生成按两个指标的排名:
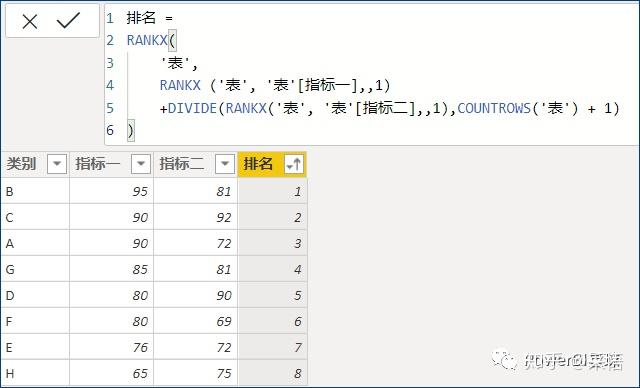
这里用了三个RANKX,你可以慢慢琢磨一下这个公式的逻辑,同时加深对这个函数的理解。
度量值的方式同样可以实现,用这几个字段生成矩阵,并把排名度量值放进去,效果如下:
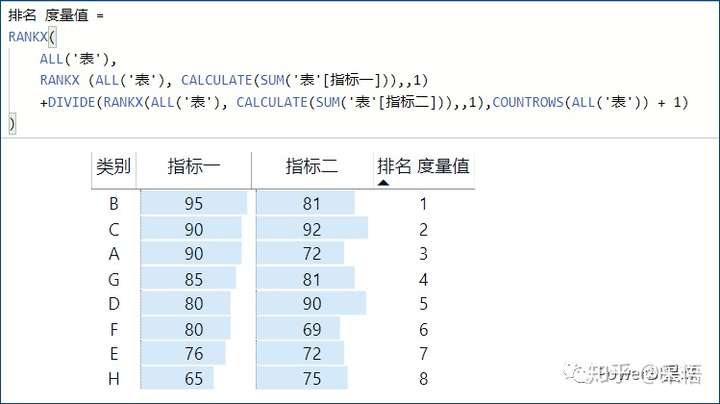
本文示例是按两个字段排序,如果是两个以上,同样是这样的原理和逻辑,需要的时候,直接套用就可以了。
最新文章
- soj 2013年 Nanjing Slection
- Linux学习 : 裸板调试 之 配置UART
- 前端:js
- 杭电1013-Digitai Root(另解)
- UVA 10047 The Monocycle
- Android防微信首页左右滑动切换
- C语言中 指针和数组
- javascript进阶——测试和打包分发
- bzoj2124 等差子序列(hash+线段树)
- iOS APP之本地数据存储(译)
- 什么是优先级队列(priority queue)?
- UiAutomator1.0 与 UiAutomator2.0
- Django与ajax、分页器
- CSAPP:第一章学习笔记:斗之气1段
- poj 1386 Play on Words门上的单词【欧拉回路&&并查集】
- iperf使用指南
- Maven相关问题解决.docx
- 最全Kafka 设计与原理详解【2017.9全新】
- spring cloud: 使用consul来替换eureka
- ElasticSearch 安装 go-mysql-elasticsearch 同步mysql的数据